This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
That’s where the new Amazon EMR Serverless application integration in Amazon SageMaker Studio can help. In this post, we demonstrate how to leverage the new EMR Serverless integration with SageMaker Studio to streamline your data processing and machine learning workflows.
API Gateway is serverless and hence automatically scales with traffic. Loadbalancer – Another option is to use a loadbalancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application LoadBalancer to implement this approach.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. You can also fine-tune your choice of Amazon Bedrock model to balance accuracy and speed.
Fargate Cluster: Establishes the Elastic Container Service (ECS) in AWS, providing a scalable and serverless container execution environment. Public Application LoadBalancer (ALB): Establishes an ALB, integrating the previous SSL/TLS certificate for enhanced security. The ALB serves as the entry point for our web container.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. The RAG Retrieval Lambda function stores conversation history for the user interaction in an Amazon DynamoDB table.
In addition, you can also take advantage of the reliability of multiple cloud data centers as well as responsive and customizable loadbalancing that evolves with your changing demands. Cloud adoption also provides businesses with flexibility and scalability by not restricting them to the physical limitations of on-premises servers.
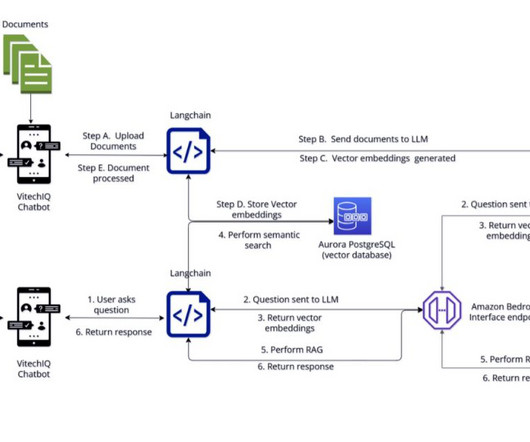
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
Creating a pipeline to continuously deploy your serverless workload on a Kubernetes cluster. The serverless approach to computing can be an effective way to solve this problem. Serverless allows running event-driven functions by abstracting the underlying infrastructure. This tutorial covers: Setting up Knative and ArgoCD.
A tool called loadbalancer (which in old days was a separate hardware device) would then route all the traffic it got between different instances of an application and return the response to the client. Developer portal , where APIs are documented and become discoverable for users. Loadbalancing.
Kubernetes loadbalancer to optimize performance and improve app stability The goal of loadbalancing is to evenly distribute incoming traffic across machines, enabling an app to remain stable and easily handle a large number of client requests. But there are other pros worth mentioning.
Identify sources of documentation or technical assistance (for example, whitepapers or support tickets). LoadBalancers, Auto Scaling. Lambda – what is lambda / serverless. Serverless Compute. The basic security and compliance aspects of the AWS platform and the shared security model. CloudTrail.
If you ever need a backend, you can create microservices or serverless functions and connect to your site via API calls. Function as a Service (Serverless) options: Netlify , AWS with SAM framework , Azure Functions and Google Cloud. What are the Benefits? JAMStack removes those complexities. Final Thoughts.
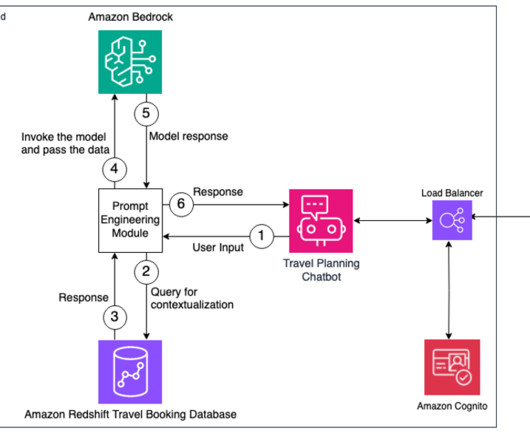
First, the user logs in to the chatbot application, which is hosted behind an Application LoadBalancer and authenticated using Amazon Cognito. The following diagram provides a high-level overview of the workflow and the components involved in this architecture. Select the Anthropic Claude model, then choose Save changes.
There are two options for it: Serverless option (with Fargate). Loadbalancer (EC2 feature) . Therefore, we will configure Virtual Private Cloud using AWS documentation on Creating a VPC with Public and Private Subnets for your cluster and then create: Virtual Private Cloud. Add loadbalancer name.
Cloudflare and Vercel are two powerful platforms, each with their own approach to web infrastructure, serverless functions, and data storage. DNS and LoadBalancing : Cloudflare provides a highly performant DNS service with loadbalancing capabilities, helping ensure applications stay online during traffic spikes.
When a draft is ready to be deployed in production, it is published to the Catalog, and can be productionalized with serverless DataFlow Functions for event-driven, micro-bursty use cases or auto-scaling DataFlow Deployments for low latency, high throughput use cases.
To learn more about this new feature, check out the AWS documentation page “Using the Neptune Workbench with Jupyter Notebooks.”. A database proxy is software that handles questions such as loadbalancing and query routing, sitting between an application and the database(s) that it queries.
AWS Keyspaces is a fully managed serverless Cassandra-compatible service. What is more interesting is that it is serverless and autoscaling: there are no operations to consider: no compaction , no incremental repair , no rebalancing the ring , no scaling issues. It’s a bit ceremonial to get started but well documented.
Adopt tools that can flag routing or network services that expose traffic externally, including loadbalancers and content delivery networks. Misconfiguration and exploitation of serverless and container workloads. Carry out a business impact analysis to get visibility into your information assets.
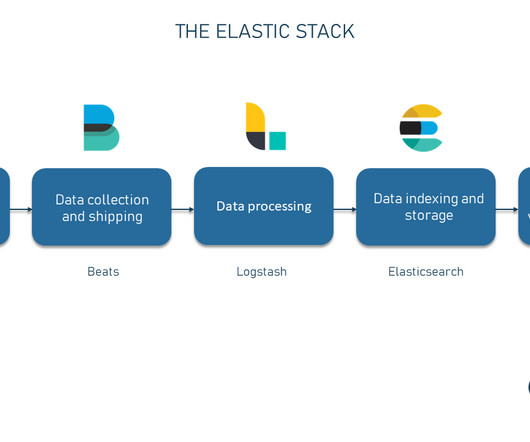
Data in Elasticsearch is organized into documents, which are then categorized into indices for better search efficiency. Each document is a collection of fields, the basic data units to be searched. Fields in these documents are defined and governed by mappings akin to a schema in a relational database.
The expert also documents problems and how they were addressed and creates metrics reports. All this documentation is used to develop effective troubleshooting practices, improve stability and performance, and optimize the company’s IT environment. Documentation and reporting. Among skills gained are.
The YAML syntax is incredible and well-documented. ” The term infrastructure refers to components like EC2 instances, loadbalancers, databases, and networking. If you have access to cloud services that allow you to go serverless entirely, consider that. Terraform is a Hashicorp product. Absolutely!
The API used for communication with the daemon is well-defined and documented, allowing developers to write programs that interface directly with the daemon without using the Docker client. Then deploy the containers and loadbalance them to see the performance. Well-written documentation. Docker registries.
You can host your documentation directly from your repositories for free with GitHub Pages. Github doesn’t provide you with thoroughly-explained documents on importing or exporting. It has thorough documentation about importing and exporting data. You should definitely check it out. Yet it comes with a tool called?—?Github
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content