This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
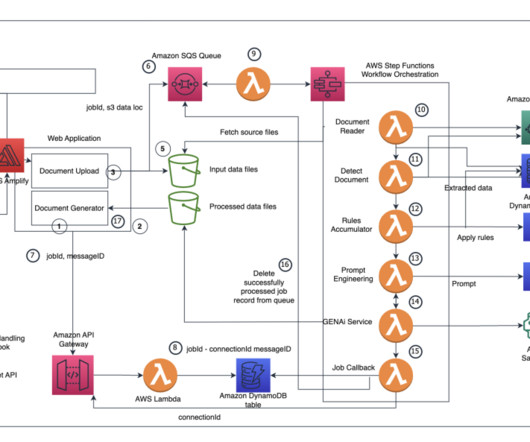
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. This request contains the user’s message and relevant metadata.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
This AI-driven approach is particularly valuable in cloud development, where developers need to orchestrate multiple services while maintaining security, scalability, and cost-efficiency. Skip hours of documentation research and immediately access ready-to-use patterns for complex services such as Amazon Bedrock Knowledge Bases.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Hybrid search – In RAG, you may also optionally want to implement and expose different templates for performing hybrid search that help improve the quality of the retrieved documents. This logic sits in a hybrid search component.
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. Although the implementation is straightforward, following best practices is crucial for the scalability, security, and maintainability of your observability infrastructure.
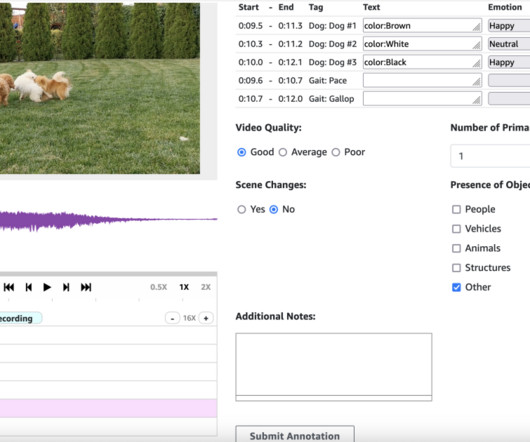
Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. The pre-annotation Lambda function can process the input manifest file before data is presented to annotators, enabling any necessary formatting or modifications. documentation. Give your job a name.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
However, these tools may not be suitable for more complex data or situations requiring scalability and robust business logic. In short, Booster is a Low-Code TypeScript framework that allows you to quickly and easily create a backend application in the cloud that is highly efficient, scalable, and reliable. WTF is Booster?
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
However, it’s important to note that in RAG-based applications, when dealing with large or complex input text documents, such as PDFs or.txt files, querying the indexes might yield subpar results. Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents.
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. Install Python 3.7 or later on your local machine.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. To convert the source document excerpt into ground truth, we provide a base LLM prompt template. Further, Amazons operating income and Free Cash Flow (FCF) dramatically improved.
This was not only about rewriting applications, but the backend data stores were also redesigned in terms of dynamic scalability , high performance, and flexibility for event-driven architecture.
Many companies across various industries prioritize modernization in the cloud for several reasons, such as greater agility, scalability, reliability, and cost efficiency, enabling them to innovate faster and stay competitive in today’s rapidly evolving digital landscape.
With Pulumis modern IaC approach, you can move beyond traditional Terraform and CloudFormation and embracea more scalable, flexible, and efficient way to manage AWS resources. Experiment with More AWS Services Deploy API Gateway, Lambda, or DynamoDB. Explore Pulumi Stacks Manage multiple environments efficiently.
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. A Lambda function with business logic invokes the primary Lambda function.
The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Furthermore, our solutions are designed to be scalable, ensuring that they can grow alongside your business.
They provide a strategic advantage for developers and organizations by simplifying infrastructure management, enhancing scalability, improving security, and reducing undifferentiated heavy lifting. For direct device actions like start, stop, or reboot, we use the action-on-device action group, which invokes a Lambda function.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. The file saved on Amazon S3 creates an event that triggers a Lambda function. The function invokes the modules.
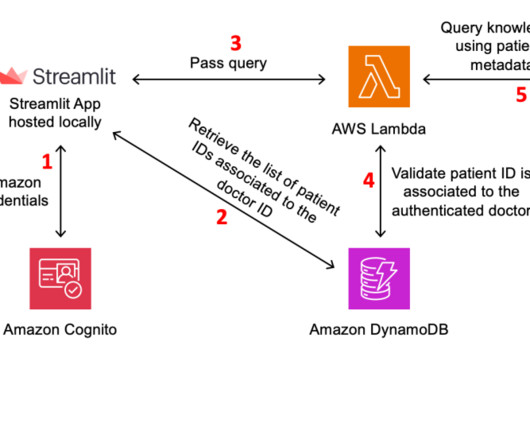
By incorporating their unique data sources, such as internal documentation, product catalogs, or transcribed media, organizations can enhance the relevance, accuracy, and contextual awareness of the language model’s outputs. The access ID associated with their authentication when the chat is initiated can be passed as a filter.
Amazon Lambda : to run the backend code, which encompasses the generative logic. Amazon Textract : for documents parsing, text, and layout extraction. Amazon Simple Storage Service (S3) : for documents and processed data caching. It sends it back to the WebSocket via the Lambda function.
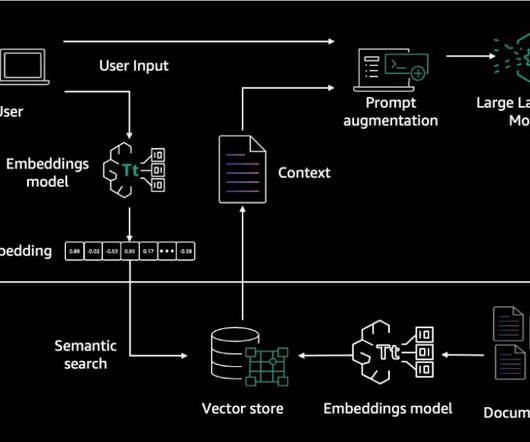
Embeddings are created for documents and user questions. The document embeddings are split into chunks and stored as indexes in a vector database. The text generation workflow then takes a question’s embedding vector and uses it to retrieve the most similar document chunks based on vector similarity.
Steps to Setup Amazon Lambda. In other cases, however, data is received from a wide variety of unstructured documents without any rhyme or reason to the way the information is presented. It can also analyze a document such as related text, tables, key-value pairs, and selection elements. Steps to Setup Amazon Lambda.
The three cloud providers we will be comparing are: AWS Lambda. Scalability, Limits, and Restrictions. Documentation. AWS Lambda. Pricing: AWS Lambda (Lambda) implements a pay-per-request pricing model: Meter. . Lambda simply transforms the event into an object and passes it to your function.
In this post, we explore how Amazon Bedrock Knowledge Bases address the use case of numerical analysis across a number of documents. Although this approach holds a lot of promise for textual documents, the presence of non-textual elements, such as tables, pose a significant challenge. This action initiates the workflow.
This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. You can then remove resources from your Amazon Bedrock IDE project and delete domains by following the Amazon SageMaker Unified Studio documentation.
Ben Kehoe recently wrote a post about AWS API Gateway to Lambda integration: How you should?—?and use API Gateway proxy integration with Lambda. He writes: The pattern that I am recommending against is the “API Gateway proxy integration” as shown in the API Gateway documentation here. Your API is less self-documenting.
Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale.
AWS has documented these concerns under the AWS Well-Architected Framework. In the AWS Cloud, this typically happens through Amazon EventBridge triggering an AWS Lambda function in response to an incoming event. We then tell EventBridge to trigger a customer AWS Lambda function. This can be a difficult balance to strike.
Self-hosted runners allow you to host your own scalable execution environments in your private cloud or on-premises, giving you more flexibility to customize and control your CI/CD infrastructure. When configuring your service, refer to the systemd documentation if you need to make changes. The first step is to create a resource class.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. The solution’s scalability quickly accommodates growing data volumes and user queries thanks to AWS serverless offerings.
Scalability and reusability : Promote scalability and reusability across different AWS migration projects. Additionally, modular design facilitates scalability by allowing users to scale the migration operation up or down based on workload demands. Create and associate a Lambda function to handle the action’s logic.
Event-driven compute with AWS Lambda is a good fit for compute-intensive, on-demand tasks such as document embedding and flexible large language model (LLM) orchestration, and Amazon API Gateway provides an API interface that allows for pluggable frontends and event-driven invocation of the LLMs.
The public cloud infrastructure is heavily based on virtualization technologies to provide efficient, scalable computing power and storage. Cloud adoption also provides businesses with flexibility and scalability by not restricting them to the physical limitations of on-premises servers. Scalability and Elasticity.
To enable quick information retrieval, we use Amazon Kendra as the index for these documents. Amazon Kendra uses natural language processing (NLP) to understand user queries and find the most relevant documents. The relevant information is then provided to the LLM for final response generation.
A CloudFormation stack to create an Amazon Lex bot and an AWS Lambda fulfillment function, which implement the core Retrieval Augmented Generation (RAG) question answering capability. When you’re done, the top level of your S3 bucket should contain six folders, each containing a single Word or PDF document.
React is a UI library well-known to developers that allows new comers to get onboard quickly due to its massive quantity of libraries and documentation and the ease of reusing components across the application. In our case, we used AWS DynamoDB, Cognito, API Gateway, SNS and Lambdas. We will talk more about these endpoints later on.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content