This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
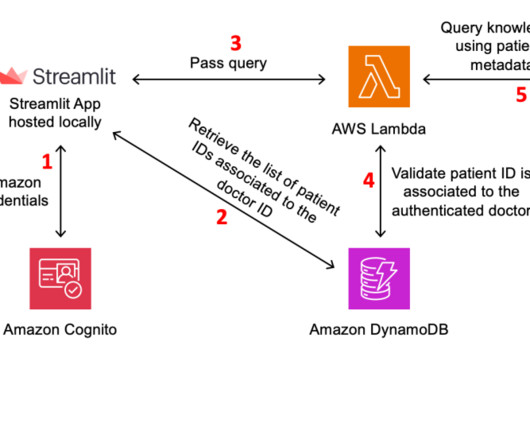
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. This request contains the user’s message and relevant metadata.
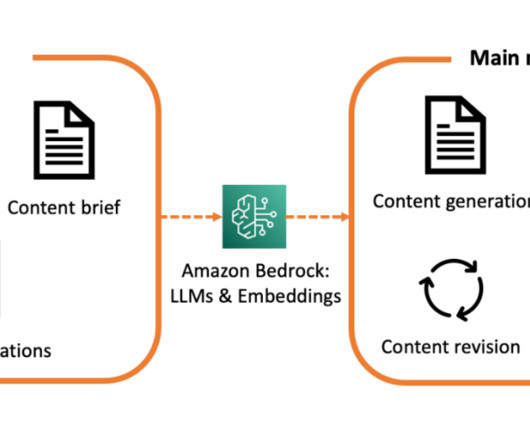
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
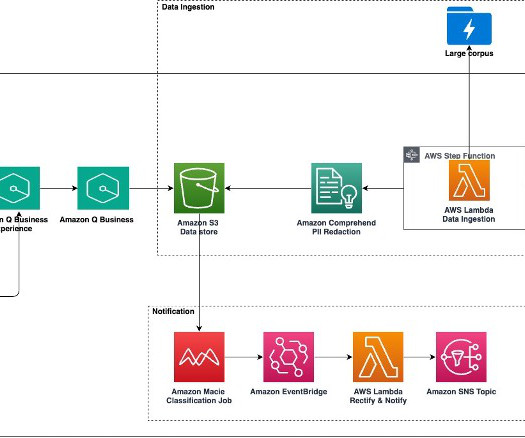
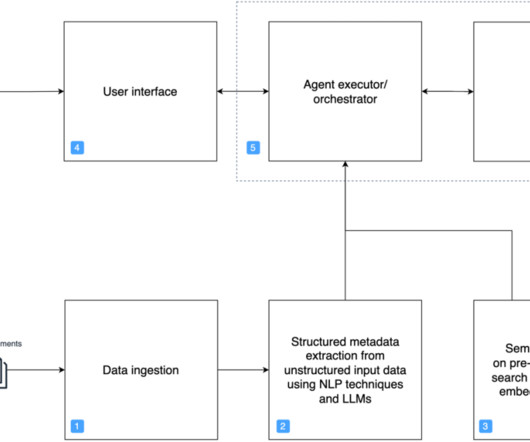
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
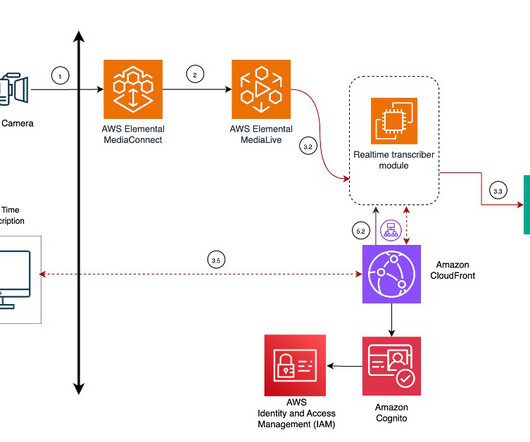
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
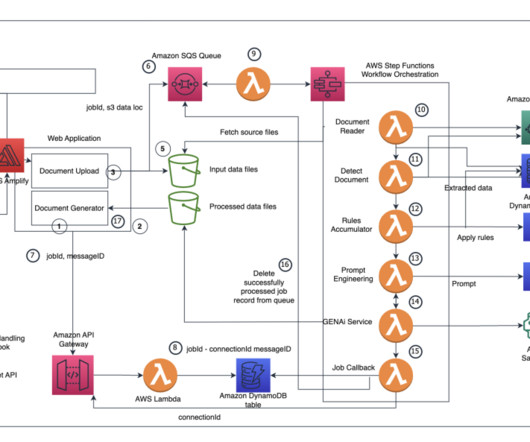
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
This is where intelligent document processing (IDP), coupled with the power of generative AI , emerges as a game-changing solution. The process involves the collection and analysis of extensive documentation, including self-evaluation reports (SERs), supporting evidence, and various media formats from the institutions being reviewed.
This engine uses artificial intelligence (AI) and machinelearning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. You can invoke Lambda functions from over 200 AWS services and software-as-a-service (SaaS) applications.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. Hybrid search – In RAG, you may also optionally want to implement and expose different templates for performing hybrid search that help improve the quality of the retrieved documents. This logic sits in a hybrid search component.
For a detailed breakdown of the features and implementation specifics, refer to the comprehensive documentation in the GitHub repository. The CloudFormation template provisions resources such as Amazon Data Firehose delivery streams, AWS Lambda functions, Amazon S3 buckets, and AWS Glue crawlers and databases.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
Skip hours of documentation research and immediately access ready-to-use patterns for complex services such as Amazon Bedrock Knowledge Bases. He builds prototypes and solutions using generative AI, machinelearning, data analytics, IoT & edge computing, and full-stack development to solve real-world customer challenges.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
Organizations possess extensive repositories of digital documents and data that may remain underutilized due to their unstructured and dispersed nature. Information repository – This repository holds essential documents and data that support customer service processes.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machinelearning models. For more information about catalogs, refer to this documentation [link]. Introduction. Using Catalogs. from pyspark.sql import Row from pyspark.sql import SparkSession.
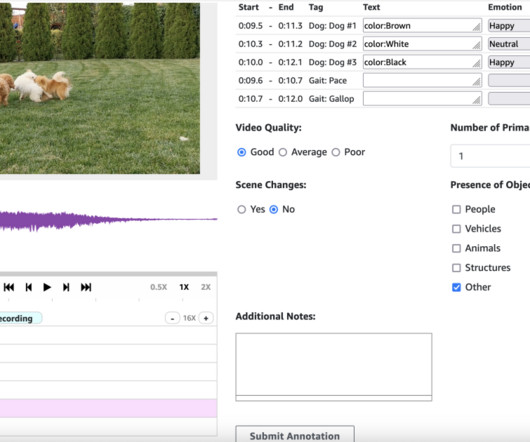
Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow. The pre-annotation Lambda function can process the input manifest file before data is presented to annotators, enabling any necessary formatting or modifications. documentation. Give your job a name.
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. or later on your local machine. Install Python 3.7
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
However, it’s important to note that in RAG-based applications, when dealing with large or complex input text documents, such as PDFs or.txt files, querying the indexes might yield subpar results. Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents.
Many RPA platforms offer computer vision and machinelearning tools that can guide the older code. Optical character recognition, for example, might extract a purchase order from an uploaded document image and trigger accounting software to deal with it.
The following is an example FlowMultiTurnInputRequestEvent JSON object: { "nodeName": "Trip_planner", "nodeType": "AgentNode", "content": { "document": "Certainly! The following is an example FlowOutputEvent JSON object: { "nodeName": "FlowOutputNode", "content": { "document": "Great news! I've successfully booked your flight to Paris.
For example, consider how the following source document chunk from the Amazon 2023 letter to shareholders can be converted to question-answering ground truth. To convert the source document excerpt into ground truth, we provide a base LLM prompt template. Further, Amazons operating income and Free Cash Flow (FCF) dramatically improved.
A streamlined process should include steps to ensure that events are promptly detected, prioritized, acted upon, and documented for future reference and compliance purposes, enabling efficient operational event management at scale. It contains the latest AWS documentation on selected topics.
In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda. The file saved on Amazon S3 creates an event that triggers a Lambda function. Refer to the Python documentation for an example.
Mozart, the leading platform for creating and updating insurance forms, enables customers to organize, author, and file forms seamlessly, while its companion uses generative AI to compare policy documents and provide summaries of changes in minutes, cutting the change adoption time from days or weeks to minutes.
A serverless, event-driven workflow using Amazon EventBridge and AWS Lambda automates the post-event processing. He specializes in Generative AI & MachineLearning with focus on Data and Feature Engineering domain. He specializes in MachineLearning and Data Science with a focus on Deep Learning and NLP.
Amazon Lambda : to run the backend code, which encompasses the generative logic. Amazon Textract : for documents parsing, text, and layout extraction. Amazon Simple Storage Service (S3) : for documents and processed data caching. It sends it back to the WebSocket via the Lambda function.
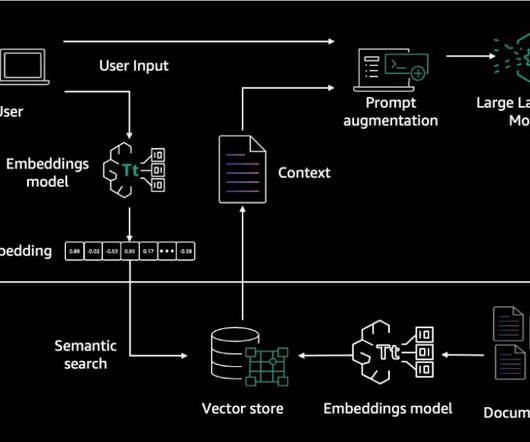
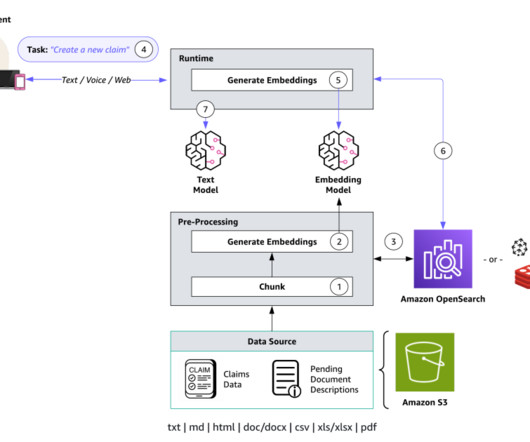
Embeddings are created for documents and user questions. The document embeddings are split into chunks and stored as indexes in a vector database. The text generation workflow then takes a question’s embedding vector and uses it to retrieve the most similar document chunks based on vector similarity.
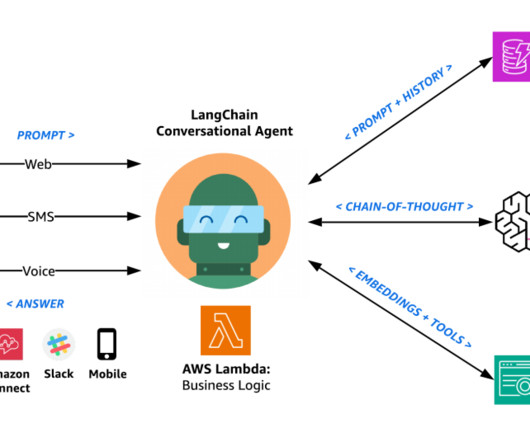
The solution is extensible, uses AWS AI and machinelearning (ML) services, and integrates with multiple channels such as voice, web, and text (SMS). Lastly, if you don’t want to set up custom integrations with large data sources, you can simply upload your documents and support multi-turn conversations.
Your Amazon Bedrock-powered insurance agent can assist human agents by creating new claims, sending pending document reminders for open claims, gathering claims evidence, and searching for information across existing claims and customer knowledge repositories. Send a pending documents reminder to the policy holder of claim 2s34w-8x.
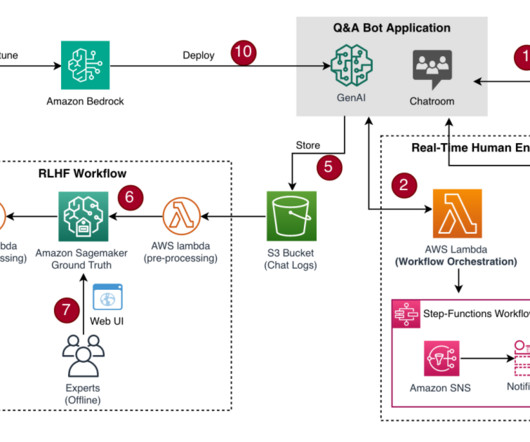
An important aspect of developing effective generative AI application is Reinforcement Learning from Human Feedback (RLHF). RLHF is a technique that combines rewards and comparisons, with human feedback to pre-train or fine-tune a machinelearning (ML) model. You can build such chatbots following the same process.
Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale.
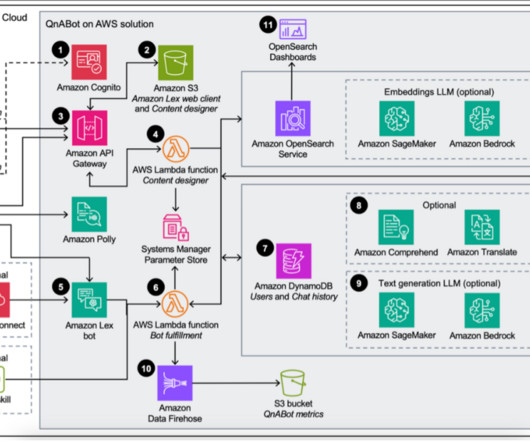
Amazon Lex then invokes an AWS Lambda handler for user intent fulfillment. The Lambda function associated with the Amazon Lex chatbot contains the logic and business rules required to process the user’s intent. The agent is equipped with tools that include an Anthropic Claude 2.1 ConversationIndexTable – Tracks the conversation state.
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. A Lambda function with business logic invokes the primary Lambda function.
This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. You can then remove resources from your Amazon Bedrock IDE project and delete domains by following the Amazon SageMaker Unified Studio documentation.
This is done using ReAct prompting, which breaks down the task into a series of steps that are processed sequentially: For device metrics checks, we use the check-device-metrics action group, which involves an API call to Lambda functions that then query Amazon Athena for the requested data. Anthropic Claude v2.1
You can use the BGE embedding model to retrieve relevant documents and then use the BGE reranker to obtain final results. The application sends the user query to the vector database to find similar documents. The documents returned as a context are captured by the QnA application.
By incorporating their unique data sources, such as internal documentation, product catalogs, or transcribed media, organizations can enhance the relevance, accuracy, and contextual awareness of the language model’s outputs. The access ID associated with their authentication when the chat is initiated can be passed as a filter.
Steps to Setup Amazon Lambda. In other cases, however, data is received from a wide variety of unstructured documents without any rhyme or reason to the way the information is presented. It can also analyze a document such as related text, tables, key-value pairs, and selection elements. Steps to Setup Amazon Lambda.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. Amazon API Gateway routes the incoming message to the inbound message handler, executed on AWS Lambda.
Amazon Kendra is a fully managed service that provides out-of-the-box semantic search capabilities for state-of-the-art ranking of documents and passages. Amazon Kendra offers simple-to-use deep learning search models that are pre-trained on 14 domains and don’t require machinelearning (ML) expertise. Ask me a question.”
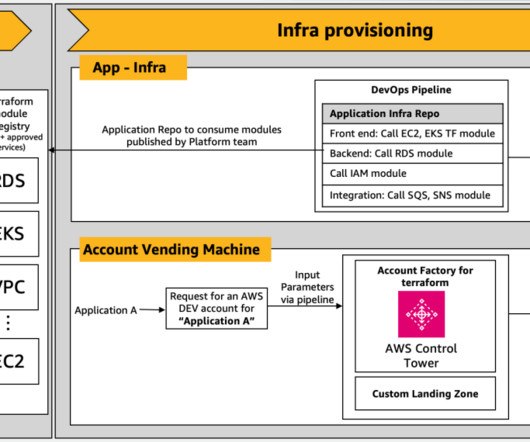
Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts. In parallel, the AVM layer invokes a Lambda function to generate Terraform code. For creating lambda function, please follow instructions. Access to Amazon Bedrock models.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content