This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS offers powerful generativeAI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. This request contains the user’s message and relevant metadata.
Recently, we’ve been witnessing the rapid development and evolution of generativeAI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. In the context of Amazon Bedrock , observability and evaluation become even more crucial.
In this post, we explore a generativeAI solution leveraging Amazon Bedrock to streamline the WAFR process. We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices.
While organizations continue to discover the powerful applications of generativeAI , adoption is often slowed down by team silos and bespoke workflows. To move faster, enterprises need robust operating models and a holistic approach that simplifies the generativeAI lifecycle.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generativeAI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Many commercial generativeAI solutions available are expensive and require user-based licenses.
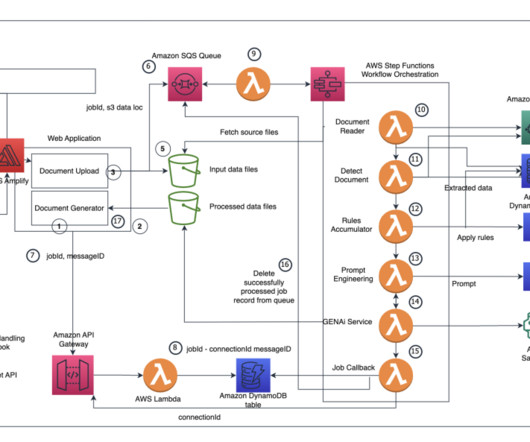
To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. We walk you through our solution, detailing the core logic of the Lambda functions. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
GenerativeAI has transformed customer support, offering businesses the ability to respond faster, more accurately, and with greater personalization. AI agents , powered by large language models (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses.
At the forefront of using generativeAI in the insurance industry, Verisks generativeAI-powered solutions, like Mozart, remain rooted in ethical and responsible AI use. Solution overview The policy documents reside in Amazon Simple Storage Service (Amazon S3) storage.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
GenerativeAI question-answering applications are pushing the boundaries of enterprise productivity. These assistants can be powered by various backend architectures including Retrieval Augmented Generation (RAG), agentic workflows, fine-tuned large language models (LLMs), or a combination of these techniques.
This is where intelligent document processing (IDP), coupled with the power of generativeAI , emerges as a game-changing solution. Enhancing the capabilities of IDP is the integration of generativeAI, which harnesses large language models (LLMs) and generative techniques to understand and generate human-like text.
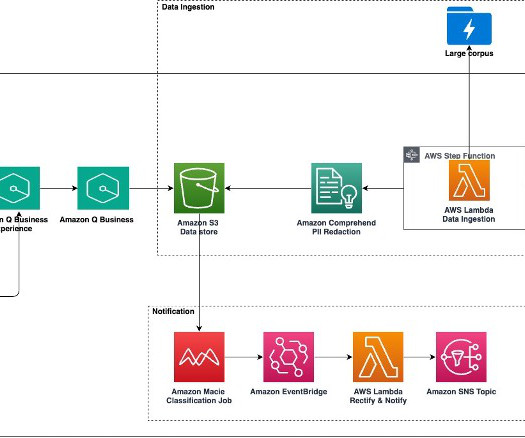
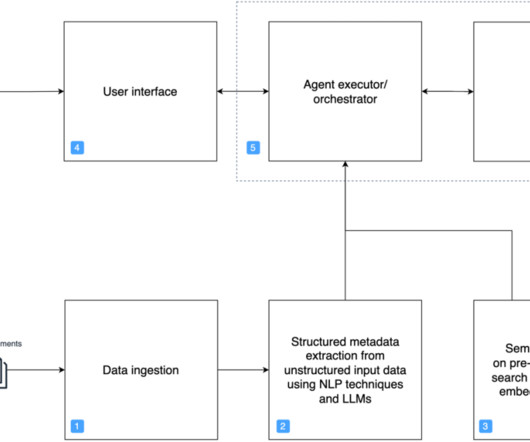
In this new era of emerging AI technologies, we have the opportunity to build AI-powered assistants tailored to specific business requirements. Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Companies across all industries are harnessing the power of generativeAI to address various use cases. Cloud providers have recognized the need to offer model inference through an API call, significantly streamlining the implementation of AI within applications.
With Amazon Bedrock and other AWS services, you can build a generativeAI-based email support solution to streamline email management, enhancing overall customer satisfaction and operational efficiency. AI integration accelerates response times and increases the accuracy and relevance of communications, enhancing customer satisfaction.
Skip hours of documentation research and immediately access ready-to-use patterns for complex services such as Amazon Bedrock Knowledge Bases. Core generates a comprehensive architecture diagram showing the knowledge base integration, Amazon Bedrock Agents configuration with action groups, API connectivity, and data flow between components.
GenerativeAI and transformer-based large language models (LLMs) have been in the top headlines recently. These models demonstrate impressive performance in question answering, text summarization, code, and text generation. Amazon Lambda : to run the backend code, which encompasses the generative logic.
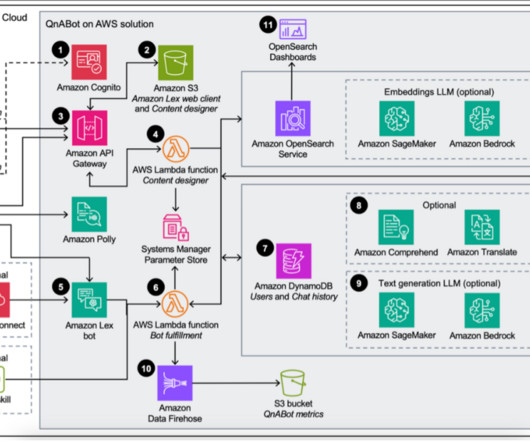
In turn, customers can ask a variety of questions and receive accurate answers powered by generativeAI. Lastly, if you don’t want to set up custom integrations with large data sources, you can simply upload your documents and support multi-turn conversations. Amazon Lex forwards requests to the Bot Fulfillment Lambda function.
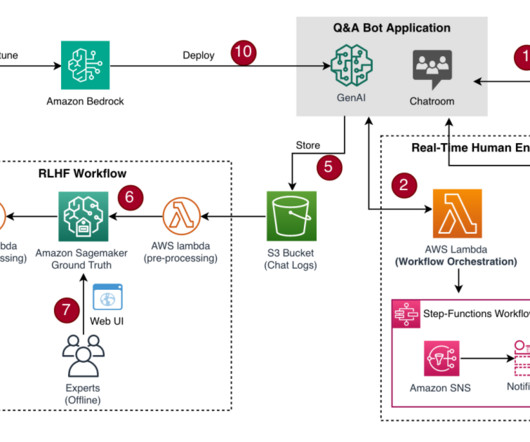
As generativeAI models advance in creating multimedia content, the difference between good and great output often lies in the details that only human feedback can capture. Pre-annotation and post-annotation AWS Lambda functions are optional components that can enhance the workflow.
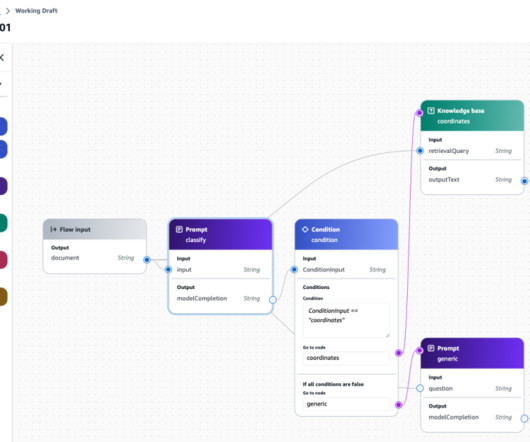
Amazon Bedrock Flows offers an intuitive visual builder and a set of APIs to seamlessly link foundation models (FMs), Amazon Bedrock features, and AWS services to build and automate user-defined generativeAI workflows at scale. Amazon Bedrock Agents offers a fully managed solution for creating, deploying, and scaling AI agents on AWS.
GenerativeAI agents are capable of producing human-like responses and engaging in natural language conversations by orchestrating a chain of calls to foundation models (FMs) and other augmenting tools based on user input. In this post, we demonstrate how to build a generativeAI financial services agent powered by Amazon Bedrock.
Recent advances in artificial intelligence have led to the emergence of generativeAI that can produce human-like novel content such as images, text, and audio. An important aspect of developing effective generativeAI application is Reinforcement Learning from Human Feedback (RLHF).
Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generativeAI, using historical data, to drive efficiency and effectiveness. Use case overview Using generativeAI, we built Account Summaries by seamlessly integrating both structured and unstructured data from diverse sources.
A generativeAI Slack chat assistant can help address these challenges by providing a readily available, intelligent interface for users to interact with and obtain the information they need. This can lead to productivity losses, frustration, and delays in decision-making.
Generative artificial intelligence (generativeAI) has enabled new possibilities for building intelligent systems. Recent improvements in GenerativeAI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval.
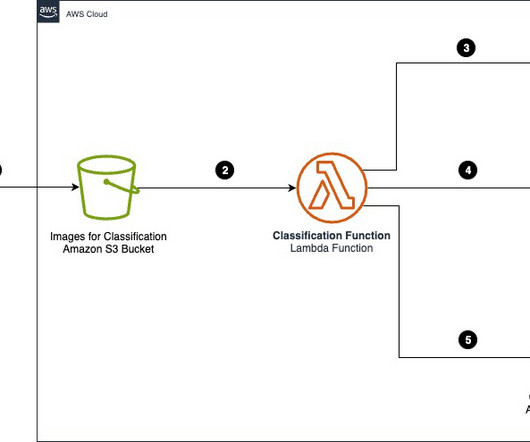
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
For several years, we have been actively using machine learning and artificial intelligence (AI) to improve our digital publishing workflow and to deliver a relevant and personalized experience to our readers. These applications are a focus point for our generativeAI efforts.
As the adoption of generativeAI continues to grow, many organizations face challenges in efficiently developing and managing prompts. Before introducing the details of the new capabilities, let’s review how prompts are typically developed, managed, and used in a generativeAI application.
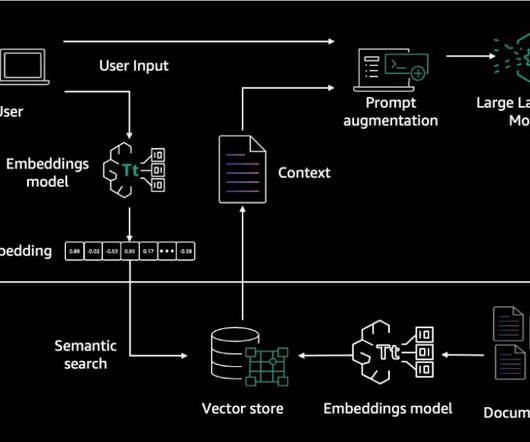
Knowledge Bases for Amazon Bedrock is a fully managed service that helps you implement the entire Retrieval Augmented Generation (RAG) workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows, pushing the boundaries for what you can do in your RAG workflows.
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. Install Python 3.7 or later on your local machine.
Site monitors conduct on-site visits, interview personnel, and verify documentation to assess adherence to protocols and regulatory requirements. However, this process can be time-consuming and prone to errors, particularly when dealing with extensive audio recordings and voluminous documentation.
Generative artificial intelligence (AI) provides an opportunity for improvements in healthcare by combining and analyzing structured and unstructured data across previously disconnected silos. GenerativeAI can help raise the bar on efficiency and effectiveness across the full scope of healthcare delivery.
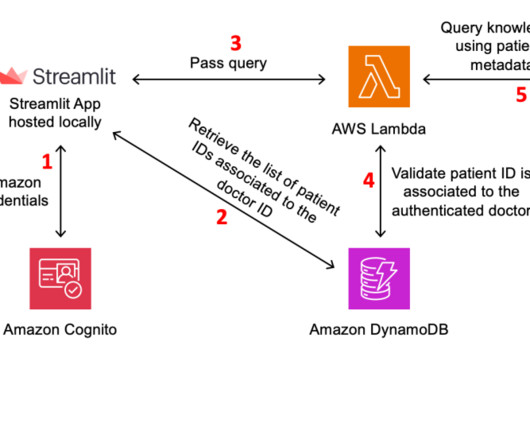
This data is used to enrich the generativeAI prompt to deliver more context-specific and accurate responses without continuously retraining the FM, while also improving transparency and minimizing hallucinations. The RAG Retrieval Lambda function stores conversation history for the user interaction in an Amazon DynamoDB table.
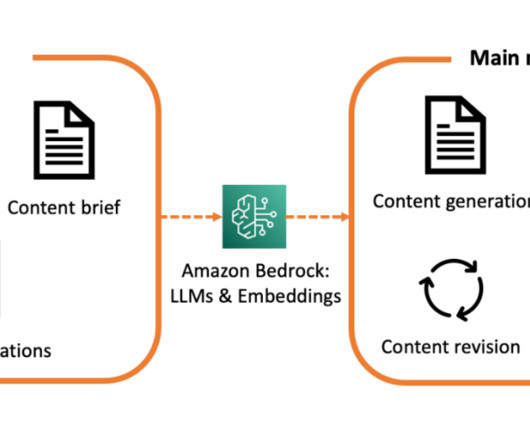
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generativeAI applications with security, privacy, and responsible AI.
To address this challenge, the contact center team at DoorDash wanted to harness the power of generativeAI to deploy a solution quickly, and at scale, while maintaining their high standards for issue resolution and customer satisfaction. You might want to peruse the sample documents you uploaded for some ideas about questions to ask.
Amazon Bedrock Agents helps you accelerate generativeAI application development by orchestrating multistep tasks. The generativeAI–based application builder assistant from this post will help you accomplish tasks through all three tiers. Create and associate an action group with an API schema and a Lambda function.
Conversational AI has come a long way in recent years thanks to the rapid developments in generativeAI, especially the performance improvements of large language models (LLMs) introduced by training techniques such as instruction fine-tuning and reinforcement learning from human feedback.
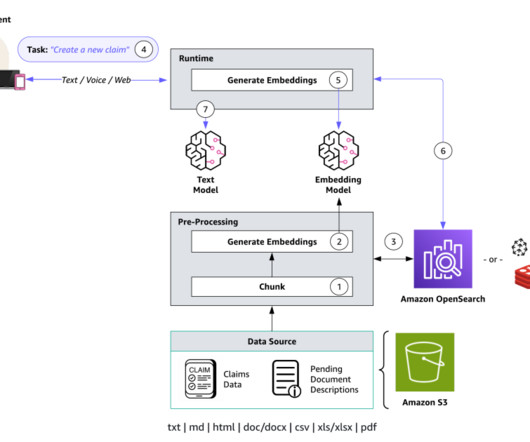
GenerativeAI agents are a versatile and powerful tool for large enterprises. These agents excel at automating a wide range of routine and repetitive tasks, such as data entry, customer support inquiries, and content generation. Send a pending documents reminder to the policy holder of claim 2s34w-8x.
A streamlined process should include steps to ensure that events are promptly detected, prioritized, acted upon, and documented for future reference and compliance purposes, enabling efficient operational event management at scale. It contains the latest AWS documentation on selected topics.
Conversational artificial intelligence (AI) assistants are engineered to provide precise, real-time responses through intelligent routing of queries to the most suitable AI functions. With AWS generativeAI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests.
We aim to target and simplify them using generativeAI with Amazon Bedrock. The application generates SQL queries based on the user’s input, runs them against an Athena database containing CUR data, and presents the results in a user-friendly format. This is a proof of concept setup. CUR data stored in an S3 bucket.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generativeAI capabilities into your applications using the AWS services you are already familiar with. The Lambda wrapper function searches for similar questions in OpenSearch Service.
This feature allows organizations to harness the power of large language models (LLMs) while making sure that the generated responses are tailored to their specific domain knowledge, regulations, and business requirements. The access ID associated with their authentication when the chat is initiated can be passed as a filter.
Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale.
Embeddings are created for documents and user questions. The document embeddings are split into chunks and stored as indexes in a vector database. The text generation workflow then takes a question’s embedding vector and uses it to retrieve the most similar document chunks based on vector similarity.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content