This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Disasterrecovery is more than just an IT issue. In fact, successful recovery from cyberattacks and other disasters hinges on an approach that integrates business impact assessments (BIA), business continuity planning (BCP), and disasterrecovery planning (DRP) including rigorous testing.
Diamond founded 11:11 Systems to meet that need – and 11:11 hasn’t stopped growing since. Our valued customers include everything from global, Fortune 500 brands to startups that all rely on IT to do business and achieve a competitive advantage,” says Dante Orsini, chief strategy officer at 11:11 Systems. “We
You diligently back up critical servers to your on-site appliance or to the cloud, but when an incident happens and you need it the most, the backup recovery fails. . Let’s take a look at why disasterrecovery fails and how you can avoid the factors that lead to this failure: . Configuration Issues .
In the event of a disruption, businesses must be able to quickly recover mission-critical data, restore IT systems and smoothly resume operations. A robust business continuity and disasterrecovery (BCDR) plan is the key to having confidence in your ability to recover quickly with minimal disruption to the business.
Jeff Ready asserts that his company, Scale Computing , can help enterprises that aren’t sure where to start with edge computing via storage architecture and disasterrecovery technologies. Managing a fleet of edge devices across locations can be a burden on IT teams that lack the necessary infrastructure.
It’s common knowledge among CIOs that disasterrecovery investments are always de-prioritized by company boards — until disaster strikes. But disasterrecovery is just one example of projects that are of an important and preemptive nature that CIOs want to fund but find de-prioritized when it comes to budget approval.
Additionally, the cost of cyber disruption will increase next year as businesses experience downtime due to cyberattacks and scramble to implement defenses fit for the AI-enabled attacker era. As part of Palo Alto Networks 2025 predictions , read on to uncover Unit 42’s insights on what to expect in the coming year.
Capital One built Cloud Custodian initially to address the issue of dev/test systems left running with little utilization. Weve worked with multiple clients who have insisted on cross-region, active-active disasterrecovery implementations, only to pull back when faced with the cost. Overemphasis on tools, budgets and controls.
At the helm of efforts is Nikhil Prabhakar, CIO, IndiaMART , who dives in-depth into how the e-commerce platform is creating systems where market players can be more digitally savvy, using AI for optimized buyer-seller connections and how robust technology has them poised to scale their business until sky is the limit.
They also check a variety of sources before making a final purchasing decision, from search engines and retail websites to product ratings and reviews, price comparison websites, and social media. Other impediments include older IT systems and lack of visibility into sales and the supply chain.
Cyber attacks and data breaches can wreak havoc on a business’ IT systems, resulting in massive costs to fix the damage and a long-lasting impact on customers that could hamper a company’s growth for years to come. Implement ICT security tools and processes: Any DORA-focused preparations need to take tools and processes into account.
As customers import their mainframe and legacy data warehouse workloads, there is an expectation on the platform that it can meet, if not exceed, the resilience of the prior system and its associated dependencies. Why disasterrecovery? The CDP DisasterRecovery Reference Architecture. At best, it led to confusion.
Yesterday, they reviewed a detailed report from NYC-based VC group Work-Bench on the city’s enterprise tech startups. Disasterrecovery can be an effective way to ease into the cloud. Before making the wholesale shift to digital, companies can start getting comfortable by using disasterrecovery as a service (DRaaS).
As a leading provider of the EHR, Epic Systems (Epic) supports a growing number of hospital systems and integrated health networks striving for innovative delivery of mission-critical systems. Business resiliency, including greater access to consumption-based infrastructure, disasterrecovery, and business continuity services.
A business continuity plan is not the same as a disasterrecovery plan , which focuses on restoring IT infrastructure and operations after a crisis. Because restoring IT is critical for most companies, numerous disasterrecovery solutions are available. You can rely on IT to implement those solutions.
The network outage, which shows the vulnerabilities in interconnected systems, provides a reminder that, despite sophisticated systems, things can, and will, go wrong, and it offers some important lessons for CIOs to take prudent action now. For CIOs, handling such incidents goes beyond just managing IT systems.
When these frameworks are fine-tuned for an organization’s specific needs, they can improve technological consistency and more easily facilitate the integration of new technologies, processes, and systems like agile computing and AI. An architecture review board can also streamline the review process, which can reduce overall project time.
If this dirty data proliferates and propagates to other systems, we open Pandora’s box of unintended consequences. These data quality issues bring a new level of potential problems for real-time systems. I wouldn't let 99% of data engineers I’ve met near a production system. With batch systems, you generally aren't losing data.
Traditionally, if you want to migrate or set up disasterrecovery (DR) for applications or databases on-premise, Google, AWS, etc. Additional CloudEndure nearly provides zero Recovery Point Objective (RPO) and minutes for Recovery Time Objective (RTO). Let’s get started. Contact us to learn more.
Difficulty in maintaining consistent security controls and configurations: Security tool sprawl makes integrations challenging, and without effective integration, information sharing among systems can fail. She often writes about cybersecurity, disasterrecovery, storage, unified communications, and wireless technology.
Apache Cassandra is a distributed database management system where data is replicated amongst multiple nodes and can span across multiple data centers. Recovery time is dependent on the amount of data. This could be due to rolling restart, cloud availability zone outage, or a number of other general errors. human error).
As per the survey, MSPs earned an average of 30 percent of their revenue from providing traditional managed services, while other service revenues, such as professional services, backup and disasterrecovery services or cloud services, lag among MSPs. Backup and DisasterRecovery Services. Whatever the reason may be?—whether
As organizations increasingly rely on cloud-based services and cybersecurity solutions to protect their digital assets, the incident serves as a stark reminder of the vulnerabilities inherent in even the most robust systems. CIOs should plan accordingly by assessing business impacts, focusing on the most critical systems.
We thrive on delivering infrastructure that enables seamless communications between the systems within the customer’s own environment, in our dedicated or multi-tenant private clouds, in the public cloud, and beyond. “Our approach to solving the business challenges enterprises face today begins with our FlexAnywhere® Platform,” says Ochoa.
Emerging companies such as Olive AI, developer of an administrative task automation system for health centers, or Plastiq, an online payment platform, obtained important rounds of financing, only then to declare bankruptcy. Plus, regular vendor audits and contract reviews can be conducted.
In the same way as for other addictions, the addicted organization needs a continual fix without carrying out any duediligence. This might involve consolidating systems, rationalizing licenses, and addressing technical debt. Implement rigorous QA processes, especially for updates to critical systems.
The paper is a proposal to enable oversight of third parties providing critical services to the UK financial system. The proposal would grant authority to classify a third party as “critical” to the financial stability and welfare of the UK financial system, and then provide governance in order to minimize the potential systemic risk.
In the wake of the Rogers outage, Canadian CIOs and IT executives and experts are reviewing their readiness to cope with such failures in the future. Peavey Mart is equally diligent about checking for vulnerabilities in its data supply chain. “We It is the very definition of a high-availability system. Build redundancy.
SAP disasterrecovery solutions protect companies in the case of a system outage, security breach, or other unplanned event that causes downtime. In the sections that follow, we’ll explore why you need an SAP disaster discovery solution, plus how to choose one that’s right for your organization. Why is this important?
Catholic Health’s IT systems and those of its partners were crashing, with one of its radiology vendors being among the first to experience technical difficulties. For many CIOs, being prepared, having disasterrecovery and business continuity plans in place, and constant communication with stakeholders lessened the impact of the outage. “We
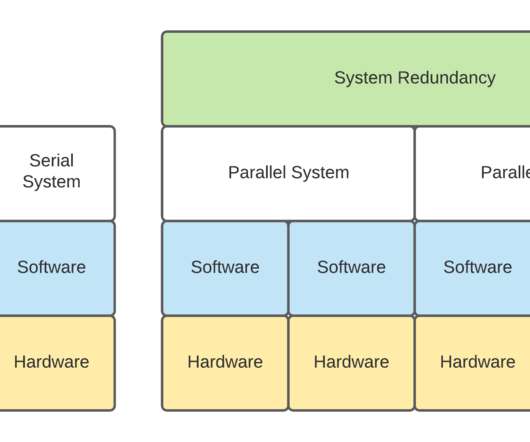
In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs. . Serial and Parallel Systems Reliability . Serial Systems Reliability. Serial Systems Reliability.
A TCO review can also help make sure a software implementation performs as expected and delivers the benefits you were looking for. Configuration and cutover: How much configuration is required to set up the software to run smoothly in my environment, and will there be any downtime associated with the cutover from the old system to the new?
In today’s digital world, businesses cannot afford system downtime. Although system downtime can sometimes be unavoidable, having mature IT processes to maintain uptime is of utmost importance. A few common causes of system downtime include hardware failure, human error, natural calamities, and of course, cyberattacks.
United Airlines took to the cloud to modernize its Revenue Management system to reduce costs, but also to land on a platform that didn’t limit its ability to apply modern revenue management processes. United’s Revenue Management Modernization Takes Flight. Next stop: Migrating a complex forecasting module planned for later in 2022.
The core of KBA’s success is effective communication with all stakeholders, both directly within the school and indirectly using technologies such as audio, video, and messaging systems, and employing these functions to enable better outcomes. As a cloud-powered platform, Avaya Cloud Office requires no manual firmware updates.
With cloud consulting, businesses gain access to a team of experts who possess in-depth knowledge of cloud computing and can guide them through the complex process of migrating their systems to the cloud. Additionally, these companies help in migrating existing systems and applications to the cloud, ensuring a smooth and seamless transition.
MSP’s business models are typically defined by the following commonalities: Service delivery: MSPs assume responsibility for specific IT systems and functions on behalf of their clients, managing them proactively, either remotely via the cloud or onsite. Take, for example, legacy systems.
In our previous blogs, we discussed at length about business impact analysis and business continuity and disasterrecovery , and how these concepts are a part of business continuity in general. It details the processes and the systems that must be sustained and maintained to allow business continuity in the event of a disruption.
As one of Veeam’s strategic technology partners, Infinidat has carved out a uniquely strong position in the Veeam integration ecosystem to advance data protection not only in disasterrecovery, but also across cyber recovery. Let me be clear: No other vendor can show Veeam dataset recovery in 12 minutes.
In this second segment, we’ll review the important “get right” technical elements of cloud adoption, which we refer to as “Cloud Foundations.” In our first blog , we discussed the importance of a Program Model and the key elements that should be considered for successful implementation.
We all know the expected benefits: reduction in CAPEX, better utilization of resources, improved system availability, better disasterrecovery, and flexibility of compute and storage resources. It also reviews several key questions we help clients think through on any cloud journey.
To share your thoughts, join the AoAD2 open review mailing list. Evolutionary System Architecture. What about your system architecture? By system architecture, I mean all the components that make up your deployed system. When you do, you get evolutionary system architecture. Your feedback is appreciated!
CIOs have a long history of managing incidents and disasters through established IT practices, guided by frameworks such as ITIL for incident management and disasterrecovery. Security orchestration tools can coordinate actions between teams and systems automatically.
They’ll be covering most of that bill themselves, Parametrix said: “The portion of the loss covered under cyber insurance policies is likely to be no more than 10% to 20%, due to many companies’ large risk retentions, and to low policy limits relative to the potential outage loss.” 700 million for remediation alone According to a study by J.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content