This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You diligently back up critical servers to your on-site appliance or to the cloud, but when an incident happens and you need it the most, the backup recovery fails. . Let’s take a look at why disasterrecovery fails and how you can avoid the factors that lead to this failure: . Configuration Issues .
In the event of a disruption, businesses must be able to quickly recover mission-critical data, restore IT systems and smoothly resume operations. A robust business continuity and disasterrecovery (BCDR) plan is the key to having confidence in your ability to recover quickly with minimal disruption to the business.
Additionally, the cost of cyber disruption will increase next year as businesses experience downtime due to cyberattacks and scramble to implement defenses fit for the AI-enabled attacker era. This interdependence makes it difficult to track and mitigate risks, allowing a single flaw to potentially affect an entire software ecosystem.
Jeff Ready asserts that his company, Scale Computing , can help enterprises that aren’t sure where to start with edge computing via storage architecture and disasterrecovery technologies. Early on, Scale focused on selling servers loaded with custom storage software targeting small- and medium-sized businesses.
Capital One built Cloud Custodian initially to address the issue of dev/test systems left running with little utilization. Weve worked with multiple clients who have insisted on cross-region, active-active disasterrecovery implementations, only to pull back when faced with the cost. Overemphasis on tools, budgets and controls.
It’s common knowledge among CIOs that disasterrecovery investments are always de-prioritized by company boards — until disaster strikes. But disasterrecovery is just one example of projects that are of an important and preemptive nature that CIOs want to fund but find de-prioritized when it comes to budget approval.
Use discount code ECFriday to save 20% off a one- or two-year subscription. Yesterday, they reviewed a detailed report from NYC-based VC group Work-Bench on the city’s enterprise tech startups. Disasterrecovery can be an effective way to ease into the cloud. Full Extra Crunch articles are only available to members.
Cyber attacks and data breaches can wreak havoc on a business’ IT systems, resulting in massive costs to fix the damage and a long-lasting impact on customers that could hamper a company’s growth for years to come. Implement ICT security tools and processes: Any DORA-focused preparations need to take tools and processes into account.
When organizations buy a shiny new piece of software, attention is typically focused on the benefits: streamlined business processes, improved productivity, automation, better security, faster time-to-market, digital transformation. A full-blown TCO analysis can be complicated and time consuming.
As a leading provider of the EHR, Epic Systems (Epic) supports a growing number of hospital systems and integrated health networks striving for innovative delivery of mission-critical systems. Business resiliency, including greater access to consumption-based infrastructure, disasterrecovery, and business continuity services.
If this dirty data proliferates and propagates to other systems, we open Pandora’s box of unintended consequences. These data quality issues bring a new level of potential problems for real-time systems. The DataOps team will be at the forefront of figuring out if a problem is data or code related. Then there's real time.
The network outage, which shows the vulnerabilities in interconnected systems, provides a reminder that, despite sophisticated systems, things can, and will, go wrong, and it offers some important lessons for CIOs to take prudent action now. For CIOs, handling such incidents goes beyond just managing IT systems.
NGA joins GitHub, offers code to help disaster response. – The National Geospatial-Intelligence Agency this week joined GitHub, a popular social network that allows programmers to collaborate and share computer code between users. BenBalter : Awesome to see @ NGA_GEOINT pushing code publicly to @ github.
In the same way as for other addictions, the addicted organization needs a continual fix without carrying out any duediligence. This might involve consolidating systems, rationalizing licenses, and addressing technical debt. Implement rigorous QA processes, especially for updates to critical systems.
The paper is a proposal to enable oversight of third parties providing critical services to the UK financial system. The proposal would grant authority to classify a third party as “critical” to the financial stability and welfare of the UK financial system, and then provide governance in order to minimize the potential systemic risk.
In the wake of the Rogers outage, Canadian CIOs and IT executives and experts are reviewing their readiness to cope with such failures in the future. But their CIOs are determined experts accustomed to “accomplishing amazing feats using free software and donated hardware,” says Knight. Build redundancy. Sapper Labs. says Guthrie. “Do
Difficulty in maintaining consistent security controls and configurations: Security tool sprawl makes integrations challenging, and without effective integration, information sharing among systems can fail. She often writes about cybersecurity, disasterrecovery, storage, unified communications, and wireless technology.
Catholic Health’s IT systems and those of its partners were crashing, with one of its radiology vendors being among the first to experience technical difficulties. For many CIOs, being prepared, having disasterrecovery and business continuity plans in place, and constant communication with stakeholders lessened the impact of the outage. “We
As per the survey, MSPs earned an average of 30 percent of their revenue from providing traditional managed services, while other service revenues, such as professional services, backup and disasterrecovery services or cloud services, lag among MSPs. Backup and DisasterRecovery Services. Whatever the reason may be?—whether
Involve Security in architecture and design Understanding who needs access to your data can influence how a system is designed and implemented. If you choose to use a third party to analyse and store your data, duediligence is best done before you engage in a contract with them. Only make public what is necessary.
MSPs can also bundle in hardware, software, or cloud technology as part of their offerings. As long as the managed service provider meets those metrics, it doesn’t matter whether it uses dedicated staff, automation, or some other system to handle calls for that customer; the MSP decides. Take, for example, legacy systems.
These widespread system crashes in turn rendered many applications inaccessible and significant amounts of data unavailable in the wake of the outage. To this end, the agency is in contact with CrowdStrike, Microsoft, and other software companies. On average, a third of their PCs and half of their servers failed.
And get the latest on AI-system inventories, the APT29 nation-state attacker and digital identity security! Most schools faced astronomical recovery costs as they tried to restore computers, recover data, and shore up their systems to prevent future attacks,” reads a Comparitech blog about the research published this week.
In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs. . Serial and Parallel Systems Reliability . Serial Systems Reliability. Serial Systems Reliability.
With cloud consulting, businesses gain access to a team of experts who possess in-depth knowledge of cloud computing and can guide them through the complex process of migrating their systems to the cloud. Additionally, these companies help in migrating existing systems and applications to the cloud, ensuring a smooth and seamless transition.
And because the incumbent companies have been around for so long, many are running IT systems with some elements that are years or decades old. Honestly, it’s a wonder the system works at all. Probably the worst IT airline disaster of 2023 came on the government side, however.
Deploy Secure Public Web Endpoints Welcome to Building Resilient Public Networking on AWS—our comprehensive blog series on advanced networking strategies tailored for regional evacuation, failover, and robust disasterrecovery. You can find the corresponding code for this blog post here.
Everyone knows information security is important: from tuning web application firewalls, to ensuring we have a disasterrecovery plan, to deploying vulnerability scanning. Phase 1: DueDiligence and Discovery. Duediligence comes first but has its origins in other engagements Modus has conducted over the years.
Similar to disasterrecovery, business continuity, and information security, data strategy needs to be well thought out and defined to inform the rest, while providing a foundation from which to build a strong business.” Overlooking these data resources is a big mistake. It will not be something they can ignore.
Why Multi-Cloud Security Matters The more moving parts in a system, the more likely it is to fail. Understanding and Overcoming Multi-Cloud Security Challenges Before we discuss benefits and best practices, let’s take a moment to review some of the specific security challenges you’ll need to overcome. Increased uptime.
In today’s digital world, businesses cannot afford system downtime. Although system downtime can sometimes be unavoidable, having mature IT processes to maintain uptime is of utmost importance. A few common causes of system downtime include hardware failure, human error, natural calamities, and of course, cyberattacks.
As one of Veeam’s strategic technology partners, Infinidat has carved out a uniquely strong position in the Veeam integration ecosystem to advance data protection not only in disasterrecovery, but also across cyber recovery. Let me be clear: No other vendor can show Veeam dataset recovery in 12 minutes.
Big enterprise customers have been buying software for a long time. Many started long before SaaS emerged as a smarter, better way to build, buy and sell software. That means they’ve got plenty of software they already depend on that needs to work with whatever your SaaS product can do for them. How do you respond?
In this second segment, we’ll review the important “get right” technical elements of cloud adoption, which we refer to as “Cloud Foundations.” In our first blog , we discussed the importance of a Program Model and the key elements that should be considered for successful implementation.
We pretty much ran on a major production environment, and then we had a hot standby disasterrecovery environment, which was far out of support and had come to end of life. We had everything from our big ERP systems to smaller, bespoke systems running in the cloud. This brings its own risks to the table.
To share your thoughts, join the AoAD2 open review mailing list. Evolutionary System Architecture. What about your system architecture? By system architecture, I mean all the components that make up your deployed system. When you do, you get evolutionary system architecture. Your feedback is appreciated!
CIOs have a long history of managing incidents and disasters through established IT practices, guided by frameworks such as ITIL for incident management and disasterrecovery. Tools such as incident management software and collaborative platforms facilitate real-time communication and coordination.
IT teams in most organizations are familiar with disasterrecovery and business continuity processes. A BIA also identifies the most critical business functions, which allows you to create a business continuity plan that prioritizes recovery of these essential functions. Dependencies. Are There BIA Standards?
Quest’anno, a rafforzare la spinta verso la sicurezza informatica c’è anche la Direttiva NIS2 (“Network and information system security”) dell’UE, che andrà a sostituire la precedente NIS, aggiornando le misure per un elevato livello di cybersicurezza in tutta l’Unione Europea. E, come sappiamo, sono solo gli incidenti “riportati”.
School closures due to COVID-19 have exposed issues like fragmented systems that don’t share data, hybrid schedule and attendance obstacles when juggling both in-class and online learning, adjustments to grading configurations mid-term, and more. What is a student information system and why is it important?
Data is in constant flux, due to exponential growth, varied formats and structure, and the velocity at which it is being generated. Data is also highly distributed across centralized on-premises data warehouses, cloud-based data lakes, and long-standing mission-critical business systems such as for enterprise resource planning (ERP).
Some basic measures IT teams can undertake to keep their IT environments secure are: Automated Software Patching. While three-fourths of IT Practitioners worldwide regularly scan their servers and workstations for operating system patches, only 58 percent apply critical operating system patches within 30 days of release.
Di lì è derivata l’accettazione; anzi, alcuni colleghi hanno finito col suggerire modifiche e miglioramenti del prodotto e si è innescato uno scambio a due sensi, una collaborazione IT-Operation, che è sempre molto proficua”. In questo modo, laddove non arriva il budget, interviene lo sviluppo software in-house.
Our flagship product, HireSystems, was the leading Applicant Tracking System delivered as a service to our large enterprise customers. Better CybeSecurity and DisasterRecovery. Vendor lock-in: It is much harder to migrate away from a SAAS product than from a legacy system. Key Evaluation Criteria - Software.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















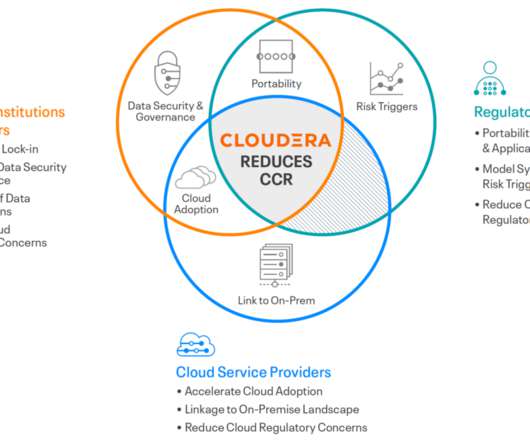

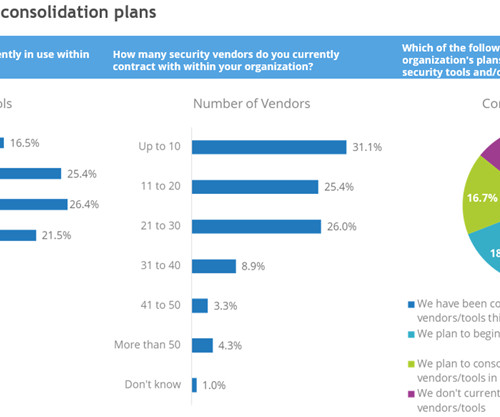






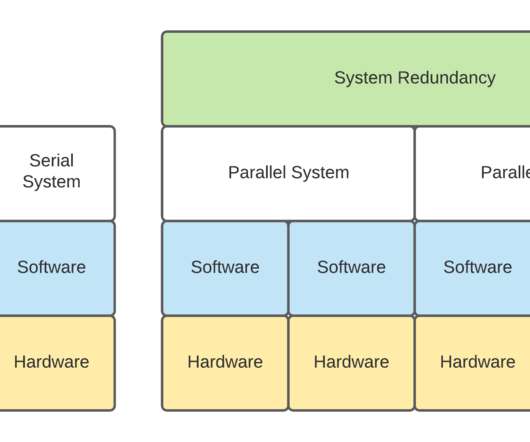




























Let's personalize your content