This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Disasterrecovery is more than just an IT issue. In fact, successful recovery from cyberattacks and other disasters hinges on an approach that integrates business impact assessments (BIA), business continuity planning (BCP), and disasterrecovery planning (DRP) including rigorous testing.
Let’s take a look at why disasterrecovery fails and how you can avoid the factors that lead to this failure: . Failure to Identify and Understand Recovery Dependencies . As a result, disasterrecovery will fail, data may be lost, and you may waste many hours troubleshooting the issues. Configuration Issues .
They also know that without a reliable disasterrecovery (DR) solution to protect business-critical applications, all their modernization efforts could be rendered moot in a matter of seconds. An IDC survey across North America and Western Europe highlights the need for effective disasterrecovery.
Manager : Hey team, management wants us to test our disasterrecovery plan. Team Member : We don’t even know if we can fail back if we perform one. Application Migration Service is an AWS service for disasterrecovery (DR), backup, and migrations. Problem 2: How do I document my disasterrecovery plan?
While AWS is responsible for the underlying hardware and infrastructure maintenance, it is the customer’s task to ensure that their Cloud configuration provides resilience against a partial or total failure, where performance may be significantly impaired or services are fully unavailable. Pilot Light strategy diagram. Backup and Restore.
11:11 Systems offers a wide array of connectivity services, including wide area networks and other internet access solutions that exceed the demanding requirements that a high-performance multi-cloud environment requires. We enable them to successfully address these realities head-on.”
Bailey expects there will soon be an AI transformation from personal assistant to digital colleague, with AI performing end-to-end automation tasks alongside the traditional workforce. Drafting and implementing a clear threat assessment and disasterrecovery plan will be critical.
While centralizing data can improve performance and security, it can also lead to inefficiencies, increased costs and limitations on cloud mobility. Those who manage it strategically, however, can turn data gravity into a competitive advantage, using it to enhance performance, security and agility across a distributed cloud infrastructure.
We lied when we said that The Exchange was done covering 2021 venture capital performance,” Anna Heim and Alex Wilhelm admit. Disasterrecovery can be an effective way to ease into the cloud. Before making the wholesale shift to digital, companies can start getting comfortable by using disasterrecovery as a service (DRaaS).
Retailers are working hard to attract and retain these employees via several methods, including: Enabling employees to use wearables or even their own mobile devices to perform scanning, mobile point of sale, clienteling, access to product information and location, and inventory and fulfillment information.
Alex Dalyac is the CEO and co-founder of Tractable , which develops artificial intelligence for accident and disasterrecovery. Alex Dalyac. Contributor. Share on Twitter. Today, Tractable is worth $1 billion. But an article in the tech press said the academic field was amid a resurgence.
Applications can be connected to powerful artificial intelligence (AI) and analytics cloud services, and, in some cases, putting workloads in the cloud moves them closer to the data they need in order to run, improving performance. Disasterrecovery. R elocating workloads.
Furthermore, supporting Epic Honor Roll requirements, purchasing cycles, and disasterrecovery places heavy demands on staff time, and recruiting, training, and retaining IT professionals can prove difficult. Implementing, maintaining, and scaling the solution can be slow, complicated, and costly.
Deploying data and workloads in this model offers the potential for incredible value, including improved agility, functionality, cost savings, performance, cloud security, compliance, sustainability, disasterrecovery—the list goes on.
A business continuity plan is not the same as a disasterrecovery plan , which focuses on restoring IT infrastructure and operations after a crisis. Because restoring IT is critical for most companies, numerous disasterrecovery solutions are available. You can rely on IT to implement those solutions.
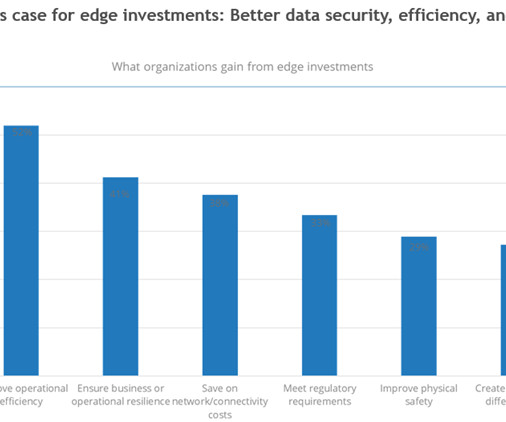
On the surface, the cost argument for deploying edge infrastructure is fairly straightforward: By processing data closer to where it is generated, organizations can reduce spending on network and connectivity while improving performance. Yet the scale and scope of edge projects can quickly escalate costs.
To always keep the platform active, we moved to a dual cloud setup, which is backed up for disasterrecovery and prepped for multi-region performance. Nikhil adds, To stay a step ahead of even the most unforeseen attacks, we perform Vulnerability Assessment and Penetration Testing.
By emphasizing immediate cost-cutting, FinOps often encourages behaviors that compromise long-term goals such as performance, availability, scalability and sustainability. Weve worked with multiple clients who have insisted on cross-region, active-active disasterrecovery implementations, only to pull back when faced with the cost.
Many of these tools also include customizable dashboards that can show key performance indicators, strategic alignment, risk assessments, and progress on initiatives. Schwartz is an adjunct research advisor with IDC’s IT Executive Programs (IEP), focusing on IT business, digital business, disasterrecovery, and data management.
CIO.com: Can you detail the Bin Dasmal Group’s digital transformation process and how changes have helped improve business performance? The key objective was to host the application securely in the cloud, with no or limited public exposure, while keeping optimal performance, infrastructure resiliency, and data redundancy.
Prior to co-launching Vic.ai, Hagerup founded the Online Backup Company, a European backup and disasterrecovery service provider. uses the invoices that it processes for customers to improve the performance of its algorithms. .” Vic.ai was founded in 2017 by Hagerup and Kristoffer Roil, both Norwegian entrepreneurs.
It involves modifying hardware, software, or settings to improve performance, enhance security, or support new business requirements. Impact Analysis: Assessing the potential effects on network performance, security, and business operations. Rollback Plan: Preparing for quick recovery in case the change fails or causes issues.
Cloud optimization is the process of improving the performance, cost-effectiveness, and reliability of cloud computing resources and services. The goal of cloud optimization is to maximize the benefits of […] The post 5 Technologies Powering Cloud Optimization appeared first on DevOps.com.
If you’re performing prompt engineering, you should persist your prompts to a reliable data store. That will safeguard your prompts in case of accidental loss or as part of your overall disasterrecovery strategy. High availability and disasterrecovery – Embedding vectors are valuable data, and recreating them can be expensive.
Specifically designed to address critical performance challenges across various workloads and applications, Flexential’s platform methodology achieves proximity acceleration to significantly reduce latency and improve application performance by shortening the physical distance between users and workloads.
A TCO review can also help make sure a software implementation performs as expected and delivers the benefits you were looking for. When performing a TCO analysis, it’s important to try to accurately estimate how many licenses you need today, as well as how many licenses you might need down the road.
The platform, which performed flawlessly with 100% uptime, is all the more impressive for its extreme scale. At its peak, the high-performance system handled almost 700,000 user sessions per second while simultaneously thwarting numerous cyberattacks, including warnings involving state-actor led attacks.
For the evolution of its enterprise storage infrastructure, Petco had stringent requirements to significantly improve speed, performance, reliability, and cost efficiency. Salem Five ended up banking on Infinidat for its storage because InfiniBox is an extremely reliable platform that self-optimizes performance.
As per the survey, MSPs earned an average of 30 percent of their revenue from providing traditional managed services, while other service revenues, such as professional services, backup and disasterrecovery services or cloud services, lag among MSPs. Backup and DisasterRecovery Services. Whatever the reason may be?—whether
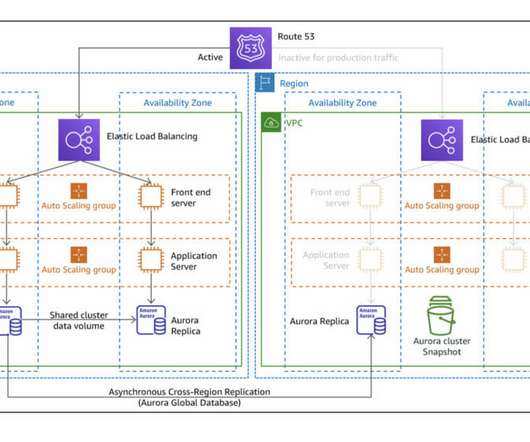
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disasterrecovery.
They can troubleshoot and resolve any issue, come up with any new module you might need for integrating software, organize and manage data, and perform delicate background systems functions and tunings that produce enormous impact for IT projects. But there is often a flip side to managing these elite IT pros.
These agents perform critical services like discovery service mapping, capacity optimization, and more, acting as a copilot for teams managing DORA compliance. These systems are crucial to DORA’s mandate, yet many organizations lag in disasterrecovery, relying on outdated strategies.
Whether that means implementing cloud-based policies, deploying patches and updates, or analyzing network performance, these IT pros are skilled at navigating virtualized environments. Cloud systems administrator Cloud systems administrators are charged with overseeing the general maintenance and management of cloud infrastructure.
Best-in-class cloud storage providers are equipped with world-class regional data centers that help ensure data security, high performance and availability, as well as business continuity/disasterrecovery. Default to cloud-based storage.
Today’s networks are often evaluated for baseline trends and performance, typical traffic patterns and flows, and similar metrics defining “normal” behavior. From an IT security perspective, dashboards of the past were traditionally used to indicate metrics like system status (i.e.,
However, opting for the VMs can save some of its capital expenditure by providing similar performance. Benefit of Fast DisasterRecovery. The disasterrecovery in the VM can be made quickly with no time. Can Have to Sacrifice With Performance. Better in Terms of Security. Issue of Efficiency in The Result.
The platform performs cryptographic operations using fragments of an encryption key that reside across different regions and cloud providers. Akeyless’s solution is centralizing secrets through plug-ins for existing IT, dev, and security tools and capabilities like disasterrecovery, Hareven continued. billion by 2025.
Commvault offers high-performance that, when combined with InfiniBox and InfiniGuard, provides SLAs that these customers demand for their next-generation data protection environment. For this reason, Commvault is awarded the Enterprise Data Protection Solution of the Year recognition.
With their new performance and cyber storage recovery guarantees, Infinidat is breaking new ground in these areas in ways that drive meaningful value for their enterprise customers.”. This was part of announcement that also included the company’s announcing a new performance guarantee across its InfiniBox ® platforms.
“[The new regions] helps us optimize our performance for customers and channel partners internationally who are dealing with specific concerns like data sovereignty and thus need their data to be stored close by. “We’ve grown headcount and our partner network to support our presence in these regions.”
Traditional benefits of duplicating IT infrastructure were least important, with greater resiliency or performance cited by 23% of respondents, and redundancy or disasterrecovery capabilities by just 21%. But there are still many factors holding back multicloud adoption in the enterprise.
It’s critical to get these areas right for security, manageability, performance and expansion – and to avoid costly rework down the road. The Elements of Cloud Foundations This phase of your cloud adoption journey provides a trusted cloud baseline to inspire migration and innovation.
Lintasarta Cloudeka’s wide array of cloud solutions and services includes robust public, private, and multi-cloud offerings and an extensive portfolio of managed services, from full Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) to Backup and DisasterRecovery-as-a-Service, cloud object storage, and everything in between.
Velero is an open source tool to safely back up and restore, performdisasterrecovery, and migrate Kubernetes cluster resources and persistent volumes. What Is Velero? Velero consists of:
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content