This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
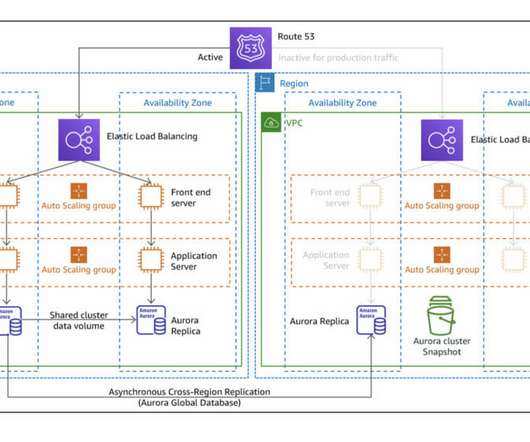
While AWS is responsible for the underlying hardware and infrastructure maintenance, it is the customer’s task to ensure that their Cloud configuration provides resilience against a partial or total failure, where performance may be significantly impaired or services are fully unavailable. Pilot Light strategy diagram. Backup and Restore.
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disasterrecovery. These steps are clearly marked in the following diagram.
QA engineers: Test functionality, security, and performance to deliver a high-quality SaaS platform. DevOps engineers: Optimize infrastructure, manage deployment pipelines, monitor security and performance. The team works towards improved performance and the integration of new functionality.
They also universally see the need for a high-performance private cloud to ensure that their mission-critical data and operations are backed up with a software-defined infrastructure that exceeds the most stringent requirements for resiliency, compliance, and performance. VCF addresses all of these needs.”
Deploy Secure Public Web Endpoints Welcome to Building Resilient Public Networking on AWS—our comprehensive blog series on advanced networking strategies tailored for regional evacuation, failover, and robust disasterrecovery. It’s important to note that, for the sake of clarity, we’ll be performing these actions manually.
But we’ve found that a lot of the complaints come from more subtle internet performance issues like packet loss or latency—problems that still read as a live internet connection, but that make phone calls sound awful or keep applications from working the way they’re supposed to. As MSPs, we think in terms of disasterrecovery and continuity.
PerformPerformance and Functional Testing at Scale. Trying to run MariaDB databases on non-database optimized hardware or those smaller than your Oracle environment can cause a performance bottleneck. Adding LoadBalancing Through MariaDB MaxScale. Test against a product size data set.
Step #1 Planning the workload before migration Evaluate existing infrastructure Perform a comprehensive evaluation of current systems, applications, and workloads. Establish objectives and performance indicators Establish clear, strategic objectives for the migration (e.g., lowering costs, enhancing scalability). Contact us Step #5.
This requires deploying changes into production environments, rapidly and safely, without interrupting users who may be performing critical tasks or relying on your systems for mission-critical processes. Multiple application nodes or containers distributed behind a loadbalancer. What is canary deployment?
Scalability: These services are highly scalable and help manage workload, ensuring the performance of the hardware and software. So, the current activity of one user will not affect the activities performed by another user. What are their security measures and disasterrecovery options?
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
As expected, this led to a growth of shadow IT among the more sophisticated user base, who needed more advanced functionality but were less able to manage licensing, security and disasterrecovery than the formal IT offering. You need to provide your own loadbalancing solution.
5) Configuring a loadbalancer The first requirement when deploying Kubernetes is configuring a loadbalancer. Without automation, admins must configure the loadbalancer manually on each pod that is hosting containers, which can be a very time-consuming process.
Your network gateways and loadbalancers. 1 Stack Overflow publishes their system architecture and performance stats at [link] , and Nick Craver has an in-depth series discussing their architecture at [Craver 2016]. Approximately the same thing again in a redundant data center (for disasterrecovery). They serve 1.3
Automated performance testing Another important factor to think about when it comes to being a competent mobile app developer is automated performance testing. Many times, performance issues are usually hidden till a point where you have to go into the actual production.
Infrastructure-as-a-service (IaaS) is a category that offers traditional IT services like compute, database, storage, network, loadbalancers, firewalls, etc. Monitoring and logging: collect performance and availability metrics as well as automate incident management and log aggregation.
Another reason is that with automatic scaling and loadbalancing VMware Cloud on AWS can adapt to the changing business needs across global regions. Add a Robust DisasterRecovery Service to Your Environment. Extend the Data Center to the Cloud with Your Existing Skillset.
In today’s competitive marketplace, companies must offer robust and performant applications that deliver a best-in-class user experience on browsers and mobile devices. A performance bottleneck in a single area necessitates complex refactoring or the acquisition of additional infrastructure to bolster the entire system.
By leveraging the wide variety of benefits of AWS’s robust and powerful infrastructure and solutions, your business can substantially improve performance, reduce cost expenditure, and much more. This scalability can improve performance, flexibility, and reliability.
GHz, offer up to 15% better compute price performance over C5 instances for a wide variety of workloads, and always-on memory encryption using Intel Total Memory Encryption (TME). GHz, offer up to 15% better compute price performance over R5 instances, and always-on memory encryption using Intel Total Memory Encryption (TME).
GHz, offer up to 15% better compute price performance over C5 instances for a wide variety of workloads, and always-on memory encryption using Intel Total Memory Encryption (TME). GHz, offer up to 15% better compute price performance over R5 instances, and always-on memory encryption using Intel Total Memory Encryption (TME).
For example, it may use network management software to monitor traffic levels and identify potential problems, system monitoring tools to monitor endpoint and server performance and resource utilization, and application monitoring tools to track response times and identify errors. What is meant by network operations?
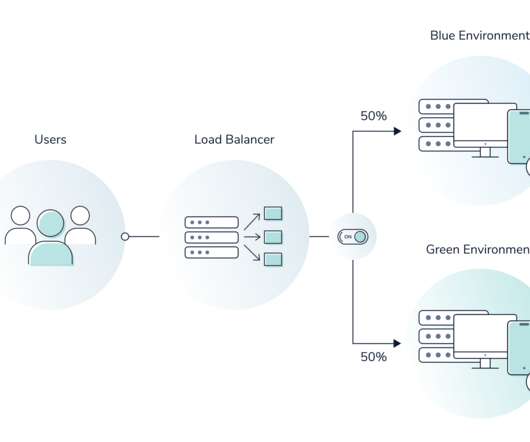
This deployment process involves creating two identical instances of a production app behind a loadbalancer. When your team wants to release new features, you switch the route on your loadbalancer from the old version of your app to the new version. Here’s a general overview of a blue-green deployment.
The speed of your transfer process will affect how quickly and efficiently work is performed and updates are made. It also can be the system on which your contractors and other workers can perform their tasks without having direct access to the air-gapped environment. For disasterrecovery, it becomes your first line of defense.
The ultimate goal of such a specialist is to design highly available and safe networks with disasterrecovery options. They also design and implement a detailed disasterrecovery plan to ensure that all infrastructure elements (data and systems) have efficient backup solutions. Infrastructure monitoring and logging.
GAD provides non-disruptive, high availability (HA), disasterrecovery (DR), and rapid data center migration services. In addition, it enables painless virtual machine storage motion where the location of the storage underlying virtual machines is moved between storage environments for loadbalancing or maintenance.
Trusted Advisor (charged as a percentage of total AWS spend) makes recommendations to reduce cost, including identifying target EC2 instances to convert to RIs, underutilized EC2 resources such as instances, loadbalancers, EBS volumes and Elastic IP addresses. For security management, AWS Trusted Advisor plays a double role.
Trusted Advisor (charged as a percentage of total AWS spend) makes recommendations to reduce cost, including identifying target EC2 instances to convert to RIs, underutilized EC2 resources such as instances, loadbalancers, EBS volumes and Elastic IP addresses. For security management, AWS Trusted Advisor plays a double role.
In order to perform this critical function of data storage and protection, database administration has grown to include many tasks: Security of data in flight and at rest. It is actually several services working together to perform storage, retrieval, user management, caching, temporary storage, and several other tasks.
Instead, this introduction will help us to understand many concepts (that we can go into more detail in future posts) about Backup as a Service (BaaS) and DisasterRecovery as a Service (DRaaS). You can also easily scale them by simply duplicating the application and running it behind a loadbalancer. Authentication.
How do you reconcile the two and do you think the problem-solving questions give you a good idea of their future performance? Monica Bajaj is an engineering leader with a wide variety of experience around building high performing globally distributed Engineering teams aligning with product delivery and customer satisfaction.
Unlike the poor canaries of the past, obviously no users are physically hurt during a software release, but negative results from a canary release can be inferred from telemetry and metrics in relation to key performance indicators (KPIs). This includes the ability to observe and comprehend both technical metrics (e.g.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content