This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
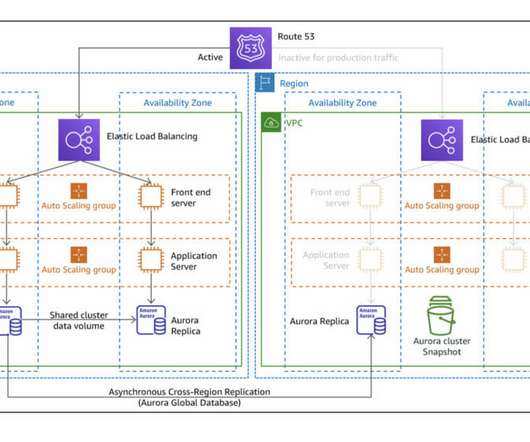
This post explores a proof-of-concept (PoC) written in Terraform , where one region is provisioned with a basic auto-scaled and load-balanced HTTP * basic service, and another recovery region is configured to serve as a plan B by using different strategies recommended by AWS. Pilot Light strategy diagram. Backup and Restore.
Region Evacuation with static anycast IP approach Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disasterrecovery. These steps are clearly marked in the following diagram.
Deploy Secure Public Web Endpoints Welcome to Building Resilient Public Networking on AWS—our comprehensive blog series on advanced networking strategies tailored for regional evacuation, failover, and robust disasterrecovery. Public Application LoadBalancer (ALB): Establishes an ALB, integrating the previous certificate.
Deploying and operating physical firewalls, physical loadbalancing, and many other tasks that extend across the on-premises environment and virtual domain all require different teams and quickly become difficult and expensive. Many organizations moved to the cloud but still must manage innumerable tasks,” he says.
As MSPs, we think in terms of disasterrecovery and continuity. You now need to think about internet links and what your disasterrecovery and continuity plans are for those. And if you have two, you need to think about things like load-balancing and instant failover. You need two connections or more.
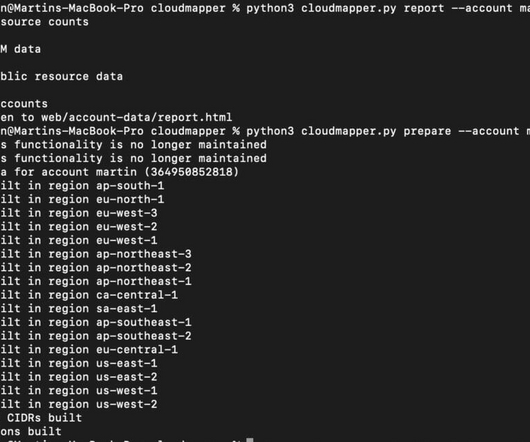
One for my DisasterRecovery blog post ( vpc_demo ) depicting an ASG and two loadbalancers on different AZs. Also, you can see that the loadbalancers are exposed to the Internet. python cloudmapper.py report --account <my_account> python cloudmapper.py
Performance testing and loadbalancing Quality assurance isn’t completed without evaluating the SaaS platform’s stability and speed. It must be tested under different conditions so it is prepared to perform well even in peak loads. It usually focuses on some testing scenarios that automation could miss.
Everything from loadbalancer, firewall and router, to reverse proxy and monitory systems, is completely redundant at both network as well as application level, guaranteeing the highest level of service availability. Implement network loadbalancing. High Availability vs. DisasterRecovery.
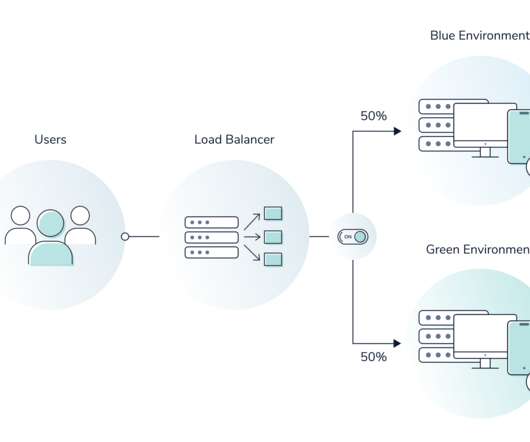
Multiple application nodes or containers distributed behind a loadbalancer. This enables you to serve the current application on one half of your environment (the blue environment) using your loadbalancer to direct traffic. There are many other benefits to setting up your application environment this way.
For comparable architectures to Oracle RAC, MariaDB Galera Cluster provides multi-master clustering, which can combine with Replication to the disasterrecovery site. Adding LoadBalancing Through MariaDB MaxScale.
This includes services for: Monitoring Logging Security Backup and restore applications Certificate management Policy agent Ingress and loadbalancer DKP can extend automatically the deployment of this stack of Day 2 applications to any clusters that DKP manages. Catalog Applications.
What are their security measures and disasterrecovery options? Infrastructure components are servers, storage, automation, monitoring, security, loadbalancing, storage resiliency, networking, etc. DisasterRecovery options: Cloud services come with the best disasterrecovery options.
Summary : Migrate as-is Oracle E-Business Suite ERP, Oracle Apex, and SplashBI environments from parent company corporate data center to Oracle Cloud Infrastructure Multiple migration iterations (production, disasterrecovery, and various development and testing) Implement loadbalancing, disasterrecovery and internet-facing application servers in (..)
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
All of your MariaDB data is replicated automatically as part of the disasterrecovery functionality. Azure Database for MariaDB scales seamlessly to handle workloads, with managed loadbalancing. In the event of a server failure, your MariaDB database has a transparent fail-over in place.
As expected, this led to a growth of shadow IT among the more sophisticated user base, who needed more advanced functionality but were less able to manage licensing, security and disasterrecovery than the formal IT offering. You need to provide your own loadbalancing solution.
5) Configuring a loadbalancer The first requirement when deploying Kubernetes is configuring a loadbalancer. Without automation, admins must configure the loadbalancer manually on each pod that is hosting containers, which can be a very time-consuming process.
Choosing the right cloud and data migration strategies Design cloud architecture Create a cloud-native framework that includes redundancy, fault tolerance, and disasterrecovery. Configure loadbalancers, establish auto-scaling policies, and perform tests to verify functionality. Contact us Step #5.
Another reason is that with automatic scaling and loadbalancing VMware Cloud on AWS can adapt to the changing business needs across global regions. Add a Robust DisasterRecovery Service to Your Environment.
Infrastructure-as-a-service (IaaS) is a category that offers traditional IT services like compute, database, storage, network, loadbalancers, firewalls, etc. Migration, backup, and DR: enable data protection, disasterrecovery, and data mobility via snapshots and/or data replication.
PostgreSQL obliterates this objection through high availability features that are on-par with Oracle’s offerings, such as multi-master, hot standbys, load-balanced clusters, and log shipping. Many decision-makers overlook open-source databases due to the assumption that they fail to offer the necessary availability.
Your network gateways and loadbalancers. Approximately the same thing again in a redundant data center (for disasterrecovery). By system architecture, I mean all the components that make up your deployed system. The applications and services built by your team, and the way they interact. Even third-party services.
Imagine seamless online data mobility between the different members of the AZ to facilitate loadbalancing and non-disruptive infrastructure refreshes, and the ability to have servers see a 100% continuously available AZ FOREVER, even as the technology within the AZ changes over many years.
The cloud provides built-in redundancy, failover mechanisms, and disasterrecovery options. Additionally, Kubernetes provides built-in features for loadbalancing, self-healing, and service discovery, making it an invaluable tool for ensuring the reliability and efficiency of cloud-based applications.
Replatforming also migrates the application to the cloud; however, limited code changes are made to leverage cloud services such as databases, messaging, loadbalancing, etc. Replatforming provides greater benefits than simply rehosting. Talent Acquisition and Retention.
Network LoadBalancer now supports TLS 1.3 – Network LoadBalancer (NLB) now supports version 1.3 Network LoadBalancer now supports TLS 1.3 – Network LoadBalancer (NLB) now supports version 1.3 Networking.
Network LoadBalancer now supports TLS 1.3 – Network LoadBalancer (NLB) now supports version 1.3 Network LoadBalancer now supports TLS 1.3 – Network LoadBalancer (NLB) now supports version 1.3 Networking.
This deployment process involves creating two identical instances of a production app behind a loadbalancer. When your team wants to release new features, you switch the route on your loadbalancer from the old version of your app to the new version. Here’s a general overview of a blue-green deployment.
Your business can also leverage AWS’s global infrastructure and availability to facilitate disasterrecovery capabilities and better availability. This depends on factors such as disasterrecovery requirements, performance preferences, volume of data, and more.
Network infrastructure includes everything from routers and switches to firewalls and loadbalancers, as well as the physical cables that connect all of these devices. Disasterrecovery: Disasterrecovery is the process of restoring your systems and data in the event of a major outage or disaster.
You can spin up virtual machines (VMs) , Kubernetes clusters , domain name system (DNS) services, storage, queues, networks, loadbalancers, and plenty of other services without lugging another giant server to your datacenter. Data backup and disasterrecovery. This makes disasterrecovery fast and cost effective.
GAD provides non-disruptive, high availability (HA), disasterrecovery (DR), and rapid data center migration services. In addition, it enables painless virtual machine storage motion where the location of the storage underlying virtual machines is moved between storage environments for loadbalancing or maintenance.
For disasterrecovery, it becomes your first line of defense. There are various schemes that can be employed, including ways to mimic the loadbalancing and limited ingress of a cloud-native environment. Data Processing Once you have your data in your air-gapped system, how are you processing it?
Common architectures for multicloud services include: Containerized applications or services deployed across providers and behind loadbalancers to enable an “always-on” environment. These compliance requirements can cover data privacy or sovereignty concerns, including disasterrecovery and mitigation specifications.
The ultimate goal of such a specialist is to design highly available and safe networks with disasterrecovery options. They also design and implement a detailed disasterrecovery plan to ensure that all infrastructure elements (data and systems) have efficient backup solutions.
Imagine seamless online data mobility between the different members of the AZ to facilitate loadbalancing and non-disruptive infrastructure refreshes, and the ability to have servers see a 100% continuously available AZ FOREVER, even as the technology within the AZ changes over many years.
Trusted Advisor (charged as a percentage of total AWS spend) makes recommendations to reduce cost, including identifying target EC2 instances to convert to RIs, underutilized EC2 resources such as instances, loadbalancers, EBS volumes and Elastic IP addresses. For security management, AWS Trusted Advisor plays a double role.
Trusted Advisor (charged as a percentage of total AWS spend) makes recommendations to reduce cost, including identifying target EC2 instances to convert to RIs, underutilized EC2 resources such as instances, loadbalancers, EBS volumes and Elastic IP addresses. For security management, AWS Trusted Advisor plays a double role.
They liked the idea of having disasterrecovery/business continuity (DR/BC) plans that allowed for the failover of one cloud’s workloads to another, but admitted in reality this wasn’t really viable at the moment, primarily from a cost of multiples in learning, implementation, and maintenance.
Loadbalancing, connection pooling, connection concentrators, DNS, caching, etc.? A “one-man-show” might want to keep the disasterrecovery and high availability plans as simple as possible. With one administrator or with several? Are the database administrators going to be separated by service or by skills?
Instead, this introduction will help us to understand many concepts (that we can go into more detail in future posts) about Backup as a Service (BaaS) and DisasterRecovery as a Service (DRaaS). You can also easily scale them by simply duplicating the application and running it behind a loadbalancer. Authentication.
Modern Marvel of Cloud engineering where you don’t have to worry about maintaining the infrastructure, worry about the scale and other services such as monitoring, security, logging, disasterrecovery, loadbalancing, backup, etc.
The experiment would require the modification of backend data (or the data store schema) in a way that is not compatible with the current service requirements Structure/Implementation Typically canary releases are implemented via a proxy like Envoy or HAProxy , smart router, or configurable loadbalancer.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content