This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You diligently back up critical servers to your on-site appliance or to the cloud, but when an incident happens and you need it the most, the backup recovery fails. . Let’s take a look at why disasterrecovery fails and how you can avoid the factors that lead to this failure: . Configuration Issues .
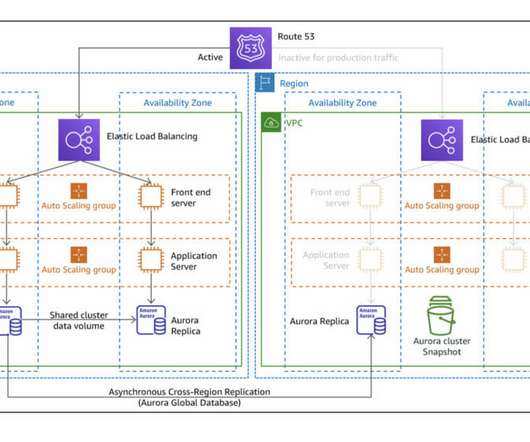
Regional failures are different from service disruptions in specific AZs , where a set of data centers physically close between them may suffer unexpected outages due to technical issues, human actions, or natural disasters. The project will generate a subset of the following diagram ( source: AWS DisasterRecovery Workloads ).
A robust business continuity and disasterrecovery (BCDR) plan is the key to having confidence in your ability to recover quickly with minimal disruption to the business. What Is Business Continuity and DisasterRecovery (BCDR) and Why Is It Important for Businesses? What Are the Objectives of a BCDR Plan?
When organizations buy a shiny new piece of software, attention is typically focused on the benefits: streamlined business processes, improved productivity, automation, better security, faster time-to-market, digital transformation. A full-blown TCO analysis can be complicated and time consuming.
It demands a blend of foresight, strategic prioritization, and having effective disasterrecovery plans in place. Adopt a protocol to test updates first Initial reports from Optus connected the outage to “changes to routing information from an international peering network” in the wake of a “routine software upgrade.”
In the same way as for other addictions, the addicted organization needs a continual fix without carrying out any duediligence. Develop comprehensive disasterrecovery plans: Ensure you have well-tested plans to recover from potential IT disasters. Assume unknown unknowns.
MSPs can also bundle in hardware, software, or cloud technology as part of their offerings. For example, an enterprise that has large investments in hardware and software can’t just reverse that investment during downturns.
In the wake of the Rogers outage, Canadian CIOs and IT executives and experts are reviewing their readiness to cope with such failures in the future. But their CIOs are determined experts accustomed to “accomplishing amazing feats using free software and donated hardware,” says Knight. Build redundancy. Sapper Labs.
These priorities are concretely influencing IT buying decisions: According to a global survey by Enterprise Strategy Group, 98% of IT decision-makers report that IT suppliers’ environmental, social, and governance (ESG) programs influence their IT purchasing decisions, and 85% have eliminated a potential technology supplier due to ESG concerns. [1]
But right now, that data likely spans edge, cloud, and core, and a good portion of it may be difficult to access and manage due to silos and complexity. Move to end-to-end, resilient data protection, including as-a-service hybrid cloud backup and disasterrecovery, for flexibility, rapid recovery, and ransomware protection.
Big enterprise customers have been buying software for a long time. Many started long before SaaS emerged as a smarter, better way to build, buy and sell software. That means they’ve got plenty of software they already depend on that needs to work with whatever your SaaS product can do for them. How do you respond?
This in light of the disparity of the environment and due to mounting cybersecurity, regulatory, and privacy challenges. The life cycle starts with HPE’s Zerto ransomware protection and disasterrecovery services and extends to hybrid cloud data protection with the HPE Backup and Recovery Service.
Some basic measures IT teams can undertake to keep their IT environments secure are: Automated Software Patching. Patching ensures that IT systems are up to date and protected from cyberattacks that exploit known software vulnerabilities. Backup and DisasterRecovery. Fundamental IT Security Measures. Conclusion.
IT teams in most organizations are familiar with disasterrecovery and business continuity processes. A BIA also identifies the most critical business functions, which allows you to create a business continuity plan that prioritizes recovery of these essential functions.
The cloud or cloud computing is a global network of distributed servers hosting software and infrastructure accessed over the internet. The virtual machines also efficiently use the hardware hosting them, giving a single server the ability to run many virtual servers. What is the cloud?
A few common causes of system downtime include hardware failure, human error, natural calamities, and of course, cyberattacks. 1. ” Have a strategy and schedule in place for making system upgrades to keep both hardware and software up to date. Incurring costs due to downtime is something they cannot afford.
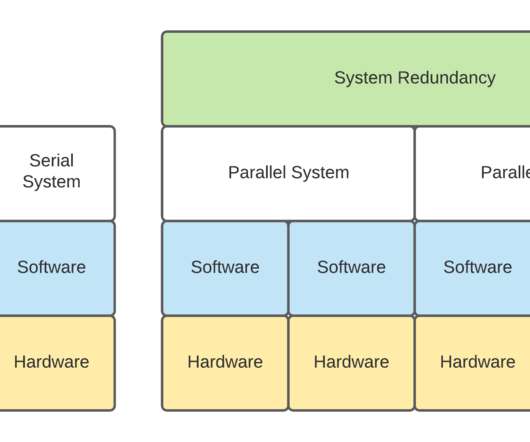
From very low levels, you can look at how the hardware itself is deployed, going higher you can look at the cluster deployment and beyond that you can get into systems that have cluster redundancy such as system disasterrecovery and come to different conclusions about the reliability at each layer. . Serial Systems Reliability.
A cloud service provider generally establishes public cloud platforms, manages private cloud platforms and/or offers on-demand cloud computing services such as: Infrastructure-as-a-Service (IaaS) Software-as-a-Service (SaaS) Platform-as-a-Service (PaaS) DisasterRecovery-as-a-Service (DRaaS). What Is a Public Cloud?
Colocation offers the advantage of complete control and customization of hardware and software, giving businesses the flexibility to meet their specific needs. On the other hand, cloud computing services provide scalability, cost-effectiveness, and better disasterrecovery options. What is the Cloud?
Colocation offers the advantage of complete control and customization of hardware and software, giving businesses the flexibility to meet their specific needs. On the other hand, cloud services provide scalability, cost-effectiveness, and better disasterrecovery options. What is the Cloud?
Private cloud architecture is crucial for businesses due to its numerous advantages. At its core, private cloud architecture is built on a virtualization layer that abstracts physical hardware resources into virtual machines. Why is Private Cloud Architecture important for Businesses?
Our support organization uses a custom case-tracking system built on our software to interact with customers. Secondly, we did not want to make the large capital outlay for an entirely new hardware platform. We were careful to follow the instructions diligently. The CDP Upgrade Advisor identified most of these for us.
Procediamo sempre con test A/B, ovvero presentando ai consumatori due esperienze diverse e valutiamo il risultato; di qui scegliamo l’una o l’altra e apportiamo eventuali modifiche all’experience del sito. Un piano solido di disasterrecovery è, inoltre, fondamentale”, sottolinea il manager.
Cloud-based Testing is simply defined as a type of software testing in which a software application is tested using Cloud computing. Throughout the software development and delivery process, each team plays a pivotal role in ensuring that the results are favorable. Why Cloud-based Software Testing.
These include workload reviews, testing and validation, managing service-level agreements (SLAs), and minimizing workload unavailability during the move. . users on either platform may still need to manually update code for compatibility with Spark 2 and Spark 3. Use existing hardware with very minimal new node additions (if required).
Refactoring — Significant changes to configurations or code during cloud migration to impact performance or behavior. Lift and shift is the single fastest way to get a workload on public cloud resources since you don’t dedicate time to optimization or code revisions. Avoiding expensive investments in hardware.
In this post, we’ll review the history of how we got here, why we’re so picky about Kafka software and hardware, and how we qualified and adopted the new AWS Graviton2-based storage instances. That EBS forced us to pay for even if we didn’t utilize the durability and persistence of volumes independent of instance hardware.
While it is impossible to completely rule out the possibility of downtime, IT teams can implement strategies to minimize the risk of business interruptions due to system unavailability. Fostering customer relationships – Frequent business disruptions due to downtime can lead to unsatisfied customers. What Is High Availability?
The last decade has seen a lot of evolution in the Software Testing and Offshore Software Development industry. It is, therefore, essential to ensure the effective functioning of the Software Development Life Cycle and that the application runs without failure. What is Software Testing? Software Testing Life Cycle (STLC).
When reviewing BI tools , we described several data warehouse tools. In this article, we’ll take a closer look at the top cloud warehouse software, including Snowflake, BigQuery, and Redshift. We’ll review all the important aspects of their architecture, deployment, and performance so you can make an informed decision.
This considering the disparity of the environment and due to mounting cybersecurity, regulatory, and privacy challenges. The life cycle starts with HPE’s Zerto ransomware protection and disasterrecovery services and extends to hybrid cloud data protection with the HPE Backup and Recovery Service.
CloudBank started their business writing custom software for private banks running mainframes. They operated as software consultants hired to work side by side with banks, helping them with project implementation and ensuring code best practices. Journey from mainframe to cloud.
The hardware layer includes everything you can touch — servers, data centers, storage devices, and personal computers. The networking layer is a combination of hardware and software elements and services like protocols and IP addressing that enable communications between computing devices.
To share your thoughts, join the AoAD2 open review mailing list. It’s particularly apparent in the way fluent Delivering teams approach evolutionary design: they start with the simplest possible design, layer on more capabilities using incremental design, and constantly refine and improve their code using reflective design.
ISA 8000 series hardware appliance now available for order. Today we are proud to announce availability of the ISA 8000 series hardware appliance. The ISA 8000 boasts massive performance boosts over the PSA 7000 series, has double the RAM and features a TPM chip on-board to ensure software and operating system integrity.
You can monitor all infrastructure components, performance metrics (CPU, memory, disk space, uptime), processes and services, event logs, application and hardware changes, and more. Organizations accomplish endpoint management by deploying software solutions that help them discover and manage all the devices in their IT environment.
For example, it may use network management software to monitor traffic levels and identify potential problems, system monitoring tools to monitor endpoint and server performance and resource utilization, and application monitoring tools to track response times and identify errors. What is the role of a NOC?
If using Infrastructure as Code, you get to enjoy increased benefits like; automation, version control, cost regulation, rapid disasterrecovery and shortened replicable provisioning times. Disasterrecovery is slower and more expensive. Disasterrecovery is slower and more expensive.
In this article I’ll discuss the PaaS phenomenon, and review nine services from leading cloud providers, which can make a major impact for many organizations. These offerings are intended to provide fully managed business infrastructure, including IT infrastructure, software, and additional elements such as backup and disasterrecovery.
Human errors, such as accidental data deletion, can also lead to severe consequences, especially without proper backup and disasterrecovery measures. Also, one of the most common threats is pushing AWS access keys into code management repositories, such as GitHub.
Transitioning to new innovations in software development often feels like taking a leap of faith. SimScale is a computer-aided engineering software product that provides simulation tools to over 100,00 users. Had they used their own hardware, they would have required a complete team of people to run their system.
When selecting cloud storage solutions, be sure to do duediligence when researching and evaluating your options. There are no upfront software or hardware costs, minimum commitments, or additional fees. Key Features: DisasterRecovery as a service. Key Features: Seamless access to your data. AWS integrated.
Failover performance is greatly improved with Pacemaker over TSA, which can reduce mean time to recovery (MTTR) in many applications. When combined with disasterrecovery (DR), Pacemaker can manage both primary and DR site clusters of servers in one resource model. What is Pacemaker? Cloud-ready for both AWS and Azure.
This domain of cybersecurity focuses on restoring business operations after a catastrophic event, such as a natural disaster. This includes disasterrecovery and business continuity plans and procedures. Of course, we should also make sure we’re periodically reviewing these plans as well as testing them.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content