This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re living in a phenomenal moment for machinelearning (ML), what Sonali Sambhus , head of developer and ML platform at Square, describes as “the democratization of ML.” It’s become the foundation of business and growth acceleration because of the incredible pace of change and development in this space.
Meet Taktile , a new startup that is working on a machinelearning platform for financial services companies. This isn’t the first company that wants to leverage machinelearning for financial products. They could use that data to train new models and roll out machinelearning applications.
One of the more tedious aspects of machinelearning is providing a set of labels to teach the machinelearning model what it needs to know. It also announced a new tool called Application Studio that provides a way to build common machinelearning applications using templates and predefined components.
Due to the success of this libary, Hugging Face quickly became the main repository for all things related to machinelearning models — not just natural language processing. Essentially, Hugging Face is building the GitHub of machinelearning. It’s a community-driven platform with a ton of repositories.
Training a frontier model is highly compute-intensive, requiring a distributed system of hundreds, or thousands, of accelerated instances running for several weeks or months to complete a single job. For example, pre-training the Llama 3 70B model with 15 trillion training tokens took 6.5 During the training of Llama 3.1
It seems like only yesterday when software developers were on top of the world, and anyone with basic coding experience could get multiple job offers. This yesterday, however, was five to six years ago, and developers are no longer the kings and queens of the IT employment hill. An example of the new reality comes from Salesforce.
As a result, employers no longer have to invest large sums to develop their own foundational models. Data scientists and AI engineers have so many variables to consider across the machinelearning (ML) lifecycle to prevent models from degrading over time. However, the road to AI victory can be bumpy.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. “ Stability looks to develop and democratize AI, and through OpenBioML, we see an opportunity to advance the state of the art in sciences, health and medicine.”
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. Although these advancements offer remarkable capabilities, they also present significant challenges.
Along the way, we’ve created capability development programs like the AI Apprenticeship Programme (AIAP) and LearnAI , our online learning platform for AI. We are happy to share our learnings and what works — and what doesn’t. So, based on a hunch, we created the AI Apprenticeship Programme. And why that role?
Gen AI-related job listings were particularly common in roles such as data scientists and data engineers, and in software development. To help address the problem, he says, companies are doing a lot of outsourcing, depending on vendors and their client engagement engineers, or sending their own people to training programs.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
Strong Compute , a Sydney, Australia-based startup that helps developers remove the bottlenecks in their machinelearningtraining pipelines, today announced that it has raised a $7.8 ” Strong Compute wants to speed up your ML model training. . ” Strong Compute wants to speed up your ML model training.
Thats why were moving from Cloudera MachineLearning to Cloudera AI. Thats a future where AI isnt a nice-to-haveits the backbone of decision-making, product development, and customer experiences. Why AI Matters More Than ML Machinelearning (ML) is a crucial piece of the puzzle, but its just one piece.
AI and machinelearning are poised to drive innovation across multiple sectors, particularly government, healthcare, and finance. Data sovereignty and the development of local cloud infrastructure will remain top priorities in the region, driven by national strategies aimed at ensuring data security and compliance.
But it’s important to understand that AI is an extremely broad field and to expect non-experts to be able to assist in machinelearning, computer vision, and ethical considerations simultaneously is just ridiculous.” Tkhir calls on organizations to invest in AI training.
LLMs deployed as code assistants accelerate developer efficiency within an organization, ensuring that code meets standards and coding best practices. Fine tuning involves another round of training for a specific model to help guide the output of LLMs to meet specific standards of an organization. Increase Productivity.
While LLMs are trained on large amounts of information, they have expanded the attack surface for businesses. From prompt injections to poisoning training data, these critical vulnerabilities are ripe for exploitation, potentially leading to increased security risks for businesses deploying GenAI.
As Artificial Intelligence (AI)-powered cyber threats surge, INE Security , a global leader in cybersecurity training and certification, is launching a new initiative to help organizations rethink cybersecurity training and workforce development. The concern isnt that AI is making cybersecurity easier, said Wallace.
Generative artificial intelligence ( genAI ) and in particular large language models ( LLMs ) are changing the way companies develop and deliver software. The chatbot wave: A short-term trend Companies are currently focusing on developing chatbots and customized GPTs for various problems. An overview.
Gartner reported that on average only 54% of AI models move from pilot to production: Many AI models developed never even reach production. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available. First let’s throw in a statistic. … that is not an awful lot.
Until recently, discussion of this technology was prospective; experts merely developed theories about what AI might be able to do in the future. When considering how to work AI into your existing business practices and what solution to use, you must determine whether your goal is to develop, deploy, or consume AI technology.
Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. Prevent repeated feature development work Software engineering best practice tells us Dont Repeat Yourself ( DRY ). Features developed by one team can be reused by another. This drives computation costs.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
In the competitive world of game development, staying ahead of technological advancements is crucial. Its improved architecture, based on the Multimodal Diffusion Transformer (MMDiT), combines multiple pre-trained text encoders for enhanced text understanding and uses QK-normalization to improve training stability. Large (SD3.5
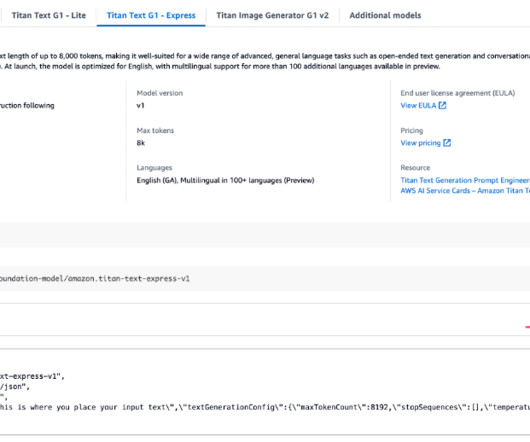
It provides developers and organizations access to an extensive catalog of over 100 popular, emerging, and specialized FMs, complementing the existing selection of industry-leading models in Amazon Bedrock. About the authors James Park is a Solutions Architect at Amazon Web Services. You can find him on LinkedIn.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
The gap between emerging technological capabilities and workforce skills is widening, and traditional approaches such as hiring specialized professionals or offering occasional training are no longer sufficient as they often lack the scalability and adaptability needed for long-term success.
The Kingdom has committed significant resources to developing a robust cybersecurity ecosystem, encompassing threat detection systems, incident response frameworks, and cutting-edge defense mechanisms powered by artificial intelligence and machinelearning. Another critical focus area is the development of human capital.
Wetmur says Morgan Stanley has been using modern data science, AI, and machinelearning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space. I firmly believe continuous learning and experimentation are essential for progress.
The pressure is on for CIOs to deliver value from AI, but pressing ahead with AI implementations without the necessary workforce training in place is a recipe for falling short of their goals. For many IT leaders, being central to organization-wide training initiatives may be new territory. “At And many CIOs are stepping up.
With AI models demanding vast amounts of structured and unstructured data for training, data lakehouses offer a highly flexible approach that is ideally suited to support them at scale. Then there’s the data lakehouse—an analytics system that allows data to be processed, analyzed, and stored in both structured and unstructured forms.
As part of MMTech’s unifying strategy, Beswick chose to retire the data centers and form an “enterprisewide architecture organization” with a set of standards and base layers to develop applications and workloads that would run on the cloud, with AWS as the firm’s primary cloud provider.
The Austin, Texas-based startup has developed a platform that uses artificial intelligence and machinelearningtrained on ransomware to reverse the effects of a ransomware attack — making sure businesses’ operations are never actually impacted by an attack.
However, today’s startups need to reconsider the MVP model as artificial intelligence (AI) and machinelearning (ML) become ubiquitous in tech products and the market grows increasingly conscious of the ethical implications of AI augmenting or replacing humans in the decision-making process. These algorithms have already been trained.
The company has post-trained its new Llama Nemotron family of reasoning models to improve multistep math, coding, reasoning, and complex decision-making. The enhancements aim to provide developers and enterprises with a business-ready foundation for creating AI agents that can work independently or as part of connected teams.
to GPT-o1, the list keeps growing, along with a legion of new tools and platforms used for developing and customizing these models for specific use cases. Our LLM was built on EXLs 25 years of experience in the insurance industry and was trained on more than a decade of proprietary claims-related data. From Llama3.1
As businesses and developers increasingly seek to optimize their language models for specific tasks, the decision between model customization and Retrieval Augmented Generation (RAG) becomes critical. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
Whether in process automation, data analysis or the development of new services AI holds enormous potential. The spectrum is broad, ranging from process automation using machinelearning models to setting up chatbots and performing complex analyses using deep learning methods. Strategy development and consulting.
Training large language models (LLMs) models has become a significant expense for businesses. PEFT is a set of techniques designed to adapt pre-trained LLMs to specific tasks while minimizing the number of parameters that need to be updated. You can also customize your distributed training.
French biotech company WhiteLab Genomics has raised $10 million in funding for an AI platform designed to aid the discovery and development of genomic therapies. However, such therapies are typically costly to develop with no guarantee that they’ll work. Show me the data.
This, of course, is where machinelearning come into play. “We That makes us the best for non-developers in small and medium-sized businesses that want to automate previously non automatable processes in the most straightforward way.
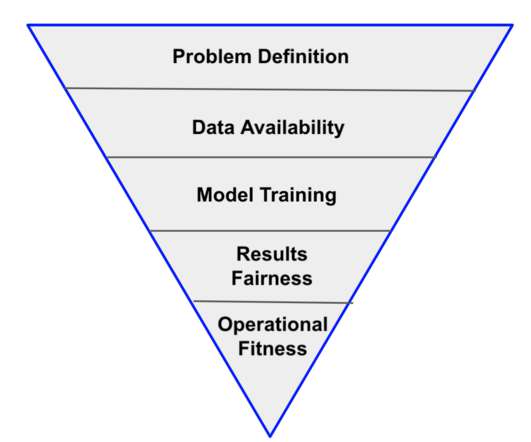
They have a lot more unknowns: availability of right datasets, model training to meet required accuracy threshold, fairness and robustness of recommendations in production, and many more. AI projects require significant investments not just during initial development but ongoing monitoring and refinement. This is the top of the funnel.
But that’s exactly the kind of data you want to include when training an AI to give photography tips. Conversely, some of the other inappropriate advice found in Google searches might have been avoided if the origin of content from obviously satirical sites had been retained in the training set.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content