This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? It’s often taken for granted by network specialists that there is a trade-off among these three facets. Resiliency.
Common monitoring metrics are latency, packet loss, and jitter. But these metrics usually are at an individual service level, like a particular internet gateway or loadbalancer. The outcome of having metrics and logging at the service level is the difficulty of tracing through the system.
Get the latest on the Hive RaaS threat; the importance of metrics and risk analysis; cloud security’s top threats; supply chain security advice for software buyers; and more! . But to truly map cybersecurity efforts to business objectives, you’ll need what CompTIA calls “an organizational risk approach to metrics.”. Product evaluation.
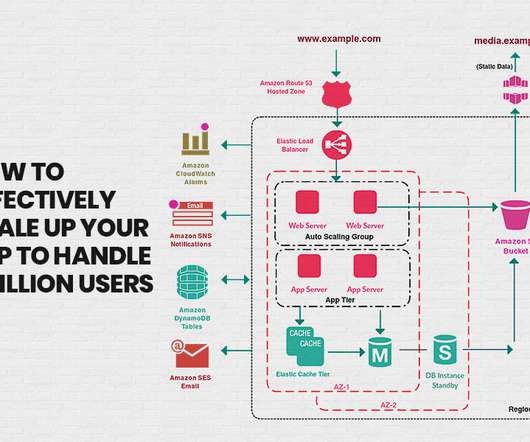
As your traffic rises and falls, you can set up auto-scaling on a specific metric (e.g., Therefore, you can bring the number of containers up or down in response to fluctuations in the selected metric. Loadbalancer (EC2 feature) . Task Definition. Create a new Task Definition. Before You Begin.
The data flow life cycle with Cloudera DataFlow for the Public Cloud (CDF-PC) Data flows in CDF-PC follow a bespoke life cycle that starts with either creating a new draft from scratch or by opening an existing flow definition from the Catalog.
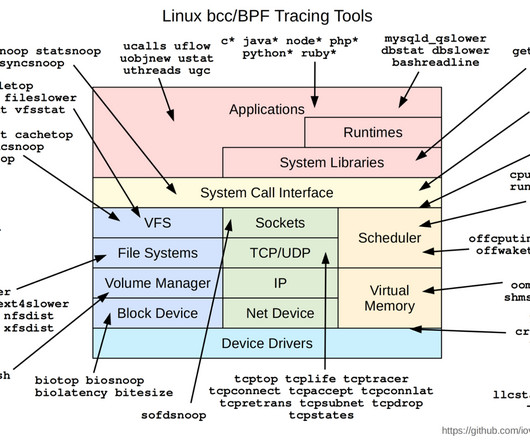
That’s the short definition. The longer definition will take some time to unpack. For example, to determine latency using traffic generated from probes or by analyzing packets, that traffic would likely pass through routers, firewalls, security appliances, loadbalancers, etc. What is eBPF?
And you find the balance of how much telemetry to sample, retaining the shape of important metrics and traces of all the errors, while dropping the rest to minimize costs. This does happen when loadbalancer configuration changes or services start using more HTTP codes. You build up alerts based on those errors.
Storing a file on an attached or even integrated disk is by definition a bottleneck. Another technique is to use a loadbalancer for dividing traffic among multiple running instances. They have services that implicitly use a loadbalancer while offering an explicit loadbalancer, too.
Network infrastructure includes everything from routers and switches to firewalls and loadbalancers, as well as the physical cables that connect all of these devices. Definition, Role, Benefits and Best Practices appeared first on Kaseya. For more information about our NOC service and to receive a quote, click here.
That said, the only way to get that 50% cost reduction is to install the AWS CloudWatch Agent on your instances and configure it to send memory metrics to CloudWatch. If you are not running the agent…then no memory metrics. We will definitely be trying these new instance types when they release in 2020!
They want to handle service communication in Layers 4 through 7 where they often implement functions like load-balancing, service discovery, encryption, metrics, application-level security and more. Application developers usually assume that the network below layer 4 “just works.” without developers needing to change their code.
We tend to explain observability with definitions from control theory, such as, “a measure of how well internal states of a system can be inferred from knowledge of its external outputs.” And one time extra using loadbalancermetrics. The big difference. An example at Honeycomb. Once for OTLP endpoints.
Once the decommissioning process is finished, stop the Cassandra service on the node: Restart the Cassandra service on the remaining nodes in the cluster to ensure data redistribution and replication: LoadBalancing Cassandra employs a token-based partitioning strategy, where data is distributed across nodes based on a token value.
NiFi is integrated with Schema Registry and it will automatically connect to it to retrieve the schema definition whenever needed throughout the flow. You can simply connect to the CDF console, upload the flow definition, and execute it. It requires setting up loadbalancers, DNS records, certificates, and keystore management. .
Helm is a quick way to get it running in Kubernetes; it encapsulates all the YAML object definitions that you need. If extra ports are open, that can confuse health checks and stop a loadbalancer from seeing your collector pods. You’ll definitely want to define some pipelines and exporters. Check on open ports.
The lack of common definitions and metrics makes it challenging to conduct comparative analyses. This speaks to the rapid pace of development and evolution happening continuously. This last category was particularly eye-opening. It turns out a significant portion of Meta's services (over 60% on some days!)
Analytics and Insights: ChatBOTs provide analytics and insights into user interactions, engagement metrics, frequently asked questions, and areas for improvement, enabling organizations to optimize their ChatBOT strategy. Let’s add a pipeline, Definition will be Pipeline Script. You must add this inside job like the below image.
We definitely need a solution that stops a redundant EC2 instance or modifies its instance type to a lower price type. AWS provides a few native tools that can help you gather cost data and system metrics to identify cost-related inefficiencies in your setup: AWS Cost Explorer. Then, you can delete these loadbalancers to reduce costs.
Figure 1: NMDB DataStore semantics We have chosen the namespace portion of a DS definition to correspond to an LDAP group name. At the time of the DS definition, a client application could define a set of (name, value) pairs against which all of the Media Document instances would be stored in that DS. This is depicted in Figure 1.
Another wrinkle for complex enterprises is that over time they’ve often acquired a variety of Internet-edge facing devices, including edge routers, switches, and loadbalancers. with BGP, GeoIP, SNMP, and performance metrics from packet capture.
Moving away from hardware-based loadbalancers and other edge appliances towards the software-based “programmable edge” provided by Envoy clearly has many benefits, particularly in regard to dynamism and automation. we didn’t need much control in the way of releasing our application?
Manage The Load of Users: If you maintain the user experience in your app, then definitely the number of users will rapidly increase. But, if the number of active users are really high on your app, then it will ultimately put an immense load on your backend system.
However, the common theme was that there is most definitely a need for specialists that work on the operational Kubernetes front lines who are responsible for keeping the platforms running. KEDA also serves as a Kubernetes Metrics Server and allows users to define autoscaling rules using a dedicated Kubernetes custom resource definition. ??News
For example, Tinder had implemented their own service mesh using Envoy proxy, Walmart created their own fleet management control plane, and several organisations had created their own continuous delivery pipelines and logging and metrics capture platforms. Welcome back to Twitter.
That is, a table may be defined using the definition of another table or a function may take a table definition as input and provide a different table definition as output. This rather unique implementation follows through to using built in data types as basis for your own custom data types, as well as constraint definitions.
So, the location is definitely appropriate for a conference about large scale software. Cassandra Prometheus Exporter, exporter for Cassandra metrics, fast (134ms!), bypasses JMX (which is slow), easy to use, knows about Cassandra specific metrics, and follows Prometheus guidelines for metrics naming, get it here: [link].
These are the most critical metrics to prioritizing risk. SAST Is Unable to Find Vulnerabilities Caused by Intermediary Components Websites can be an incredibly complex collection of Web servers, Web applications, application servers, databases, loadbalancers, caching proxies, Web application firewalls, CDNs, and more.
So, the location is definitely appropriate for a conference about large scale software. Cassandra Prometheus Exporter , exporter for Cassandra metrics, fast (134ms!), bypasses JMX (which is slow), easy to use, knows about Cassandra specific metrics, and follows Prometheus guidelines for metrics naming, get it here: [link].
Camille offers a holistic definition of platform engineering: “ a product approach to developing internal platforms that create leverage by abstracting away complexity , being operated to provide reliable and scalable foundations , and by enabling application engineers to focus on delivering great products and user experiences.”
Service Definition and Monitoring Administrators will be able to define a service or application as a collection of components (containers, virtual machines, databases, storage arrays, loadbalancers, etc.) So, to be meta, “dependencies” are a dependency for the rest of AIOps. and define SLAs, scheduled downtime, etc.
But for your database or for your loadbalancers or other parts of your system. The firewalls you rely on, the loadbalancers and things like that. In the metrics you use matter because those metrics are what you’re going to be explaining to your user base about what’s going on. To your users?
DevOps teams should: Treat Agent Definitions as Code : Store agent definitions, skills, and configurations in a version-controlled repository to track changes and ensure consistent deployments. performance: Agent Performance Metrics : Track reasoning accuracy, response times, and user engagement to identify areas for improvement.
LoadBalancers / Reverse Proxy. There are many unique things but the storage layer, event-based sync is definitely worth learning, here are more details on it Egnyte object store and Egnyte Canonical File System. How do you handle loadbalancing? Egnyte Object Store. Application Servers. Elasticsearch. Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content