This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, trade along the Silk Road was not just a matter of distance; it was shaped by numerous constraints much like todays data movement in cloud environments. Merchants had to navigate complex toll systems imposed by regional rulers, much as cloud providers impose egress fees that make it costly to move data between platforms.
When it comes to data-intensive applications, setting up the infrastructure is expensive and time-consuming. That’s where serverless plays best — you only pay for the resources when you’re using them, not when they’re sitting idle. Serverless doesn’t mean there are no servers.
The company focuses on data-processing workflows across multiple cloud providers. It hides many complexities using a serverless model. Koyeb believes that companies will take advantage of the best cloud-native APIs and storage services going forward. You can move and process data based on a fixed schedule or based on events.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. An Amazon OpenSearch Serverless collection. The GitHub repo cloned to the Amazon SageMaker Studio instance.
AI agents , powered by large language models (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences.
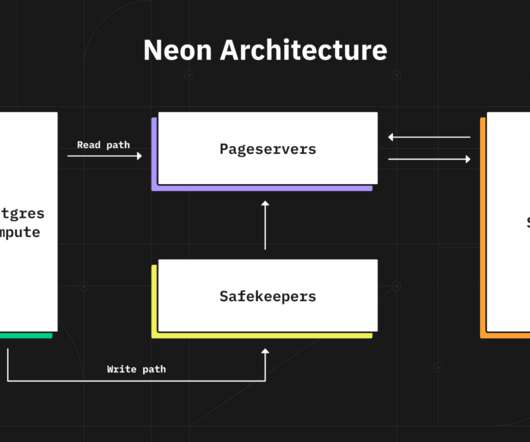
Neon , a startup providing developers with a serverless option for Postgres databases, today announced that it raised $30 million in a Series A-1 round led by GGV with participation from Khosla Ventures, General Catalyst, Founders Fund and angel investors. Many developers opt for a fully managed platform.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
A crucial question that plagues cloud application developers is, “What kind of storage should we use for our app?” Unlike other choices like compute runtimes—Lambda/serverless, containers or virtual machines—datastorage choice is highly sticky and makes future application improvements and migrations much harder.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. These potential vulnerabilities could be exploited by adversaries through various threat vectors.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. Cloud Storage Bucket: GCP’s unified object storage, allowing worldwide storage and retrieval of any amount of data.
Amazon Bedrock Custom Model Import enables the import and use of your customized models alongside existing FMs through a single serverless, unified API. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability. An S3 bucket prepared to store the custom model.
Introduction With an ever-expanding digital universe, datastorage has become a crucial aspect of every organization’s IT strategy. The cloud, particularly Amazon Web Services (AWS), has made storing vast amounts of data more uncomplicated than ever before. The following table gives you an overview of AWS storage costs.
This article describes the implementation of RESTful API on AWS serverless architecture. It provides a detailed overview of the architecture, data flow, and AWS services that can be used. This article also describes the benefits of the serverless architecture over the traditional approach. What Is Serverless Architecture?
As the digital age progresses, the need for efficient and secure data governance practices becomes more crucial than ever. This article delves into the concept of User Data Governance and its implementation using serverless streaming.
With the growth of the application modernization demands, monolithic applications were refactored to cloud-native microservices and serverless functions with lighter, faster, and smaller application portfolios for the past years.
The Hazelcast Serverless means that Hazelcast manages the cloud infrastructure for you. Each Viridian Serverless cluster is an independent deployment of the Hazelcast Platform in a Kubernetes container. Viridian Serverless clusters come in two types:1) Development: Capped storage.
Data privacy and network security With Amazon Bedrock, you are in control of your data, and all your inputs and customizations remain private to your AWS account. Your data remains in the AWS Region where the API call is processed. All data is encrypted in transit and at rest.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for big data workloads has traditionally been a significant challenge, often requiring specialized expertise.
DeltaStream provides a serverless streaming database to manage, secure and process data streams. “Serverless” refers to the way DeltaStream abstracts away infrastructure, allowing developers to interact with databases without having to think about servers.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
million terabytes of data will be generated by humans over the web and across devices. That’s just one of the many ways to define the uncontrollable volume of data and the challenge it poses for enterprises if they don’t adhere to advanced integration tech. As well as why data in silos is a threat that demands a separate discussion.
Why I migrated my dynamic sites to a serverless architecture. Like most web developers these days, I’ve heard of serverless applications and Jamstack for a while. The idea of serverless for a tool that is mostly static content is appealing. Not the usual serverless migration. So, should I migrate at all?
In this blog post, you will learn how to build a Serverless solution to process images using Amazon Rekognition , AWS Lambda and the Go programming language.
Architecting a multi-tenant generative AI environment on AWS A multi-tenant, generative AI solution for your enterprise needs to address the unique requirements of generative AI workloads and responsible AI governance while maintaining adherence to corporate policies, tenant and data isolation, access management, and cost control.
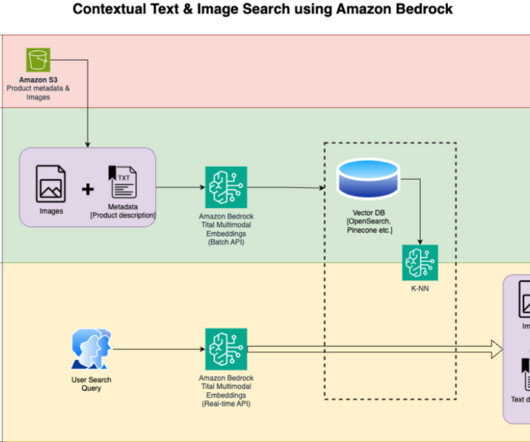
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. The solution design consists of two parts: data indexing and contextual search. Review and prepare the dataset.
Archival data in research institutions and national laboratories represents a vast repository of historical knowledge, yet much of it remains inaccessible due to factors like limited metadata and inconsistent labeling. Multiple specialized Amazon Simple Storage Service Buckets (Amazon S3 Bucket) store different types of outputs.
With serverless being all the rage, it brings with it a tidal change of innovation. or invest in a vendor-agnostic layer like the serverless framework ? or invest in a vendor-agnostic layer like the serverless framework ? FaaS functions only solve the compute part, but where is data stored and managed, and how is it accessed?
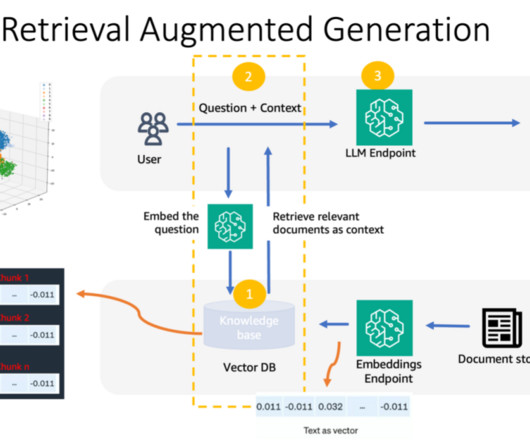
Using Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources.
The tools include sophisticated pipelines for gathering data from across the enterprise, add layers of statistical analysis and machine learning to make projections about the future, and distill these insights into useful summaries so that business users can act on them. Visual IDE for data pipelines; RPA for rote tasks. Open Source.
Because Amazon Bedrock is serverless, you dont have to manage infrastructure to securely integrate and deploy generative AI capabilities into your application, handle spiky traffic patterns, and enable new features like cross-Region inference, which helps provide scalability and reliability across AWS Regions.
The financial service (FinServ) industry has unique generative AI requirements related to domain-specific data, data security, regulatory controls, and industry compliance standards. Data security – Ensuring the security of inference payload data is paramount.
Data source curation and authorization – The CCoE team created several Amazon Simple Storage Service (Amazon S3) buckets to store their curated content, including cloud governance best practices, patterns, and guidance. With the Amazon Q Business S3 connector, the CCoE team was able to sync and index their data in just a few clicks.
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. For more details about pricing, refer to Amazon Bedrock pricing.
With Serverless, it’s not the technology that’s hard, it’s understanding the language of a new culture and operational model. Serverless architecture has coined some new terms and, more confusingly, re-used a few older terms with new meanings. Once you have real users you’ll store their data in another database. Environment.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the AWS tools without having to manage any infrastructure. We must also account for limitations in the data that we ask Anthropics Claude to analyze.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
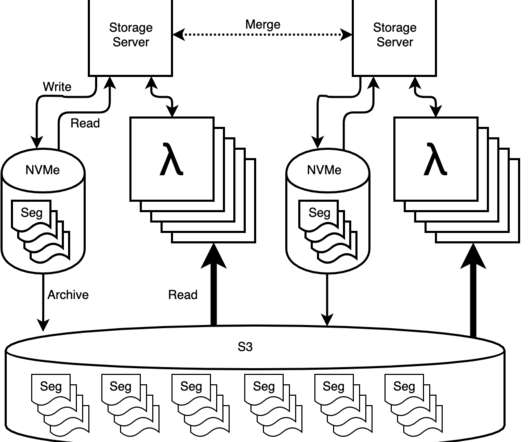
When we introduced Secondary Storage two years ago, it was a deliberate compromise between economy and performance. Compared to Honeycomb’s primary NVMe storage attached to dedicated servers, secondary storage let customers keep more data for less money. Today things look very different. Today things look very different.
Financial analysts and research analysts in capital markets distill business insights from financial and non-financial data, such as public filings, earnings call recordings, market research publications, and economic reports, using a variety of tools for data mining.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure.
Other top concerns are data privacy and security challenges (31%) and lack of cloud security and cloud expertise (24%). After some time, people have understood the storage needs better based on usage and preventing data extract fees.” He went with cloud provider Wasabi for those storage needs. “We
However, customer interaction data such as call center recordings, chat messages, and emails are highly unstructured and require advanced processing techniques in order to accurately and automatically extract insights. The customer interaction transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket.
It's primarily meant for data teams. Most of my career has been in data. I then spent six years as a CTO, although I managed the data team directly for a long time and would occasionally write some data code. Data 1 strikes me a a discipline that deserves a bit more love. Data as its own discipline.
Cloud Run is a fully managed service for running containerized applications in a scalable, serverless environment. It manages the infrastructure, scaling and execution environment, allowing you to run your application in a serverless manner without having to worry about the underlying systems.
We explore how to build a fully serverless, voice-based contextual chatbot tailored for individuals who need it. The aim of this post is to provide a comprehensive understanding of how to build a voice-based, contextual chatbot that uses the latest advancements in AI and serverless computing. We discuss this later in the post.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content