This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With serverless components, there is no need to manage infrastructure, and the inbuilt tracing, logging, monitoring and debugging make it easy to run these workloads in production and maintain service levels. Financial services unique challenges However, it is important to understand that serverless architecture is not a silver bullet.
How does Serverless help? How about security When the device sends its data, it also contains the identifier of the device itself. Conclusion Real-world examples help illustrate our options for serverless technology. The post Serverless, it can help you brew beer appeared first on Xebia.
In 2025, data management is no longer a backend operation. The evolution of cloud-first strategies, real-time integration and AI-driven automation has set a new benchmark for data systems and heightened concerns over data privacy, regulatory compliance and ethical AI governance demand advanced solutions that are both robust and adaptive.
As is commonly the case, data sets used inside companies almost always come from diverse sources and in different, unstructured formats. Tilo’s data infrastructure tool TiloRes says it helps companies match data points from different sources and formats, by being both serverless and doing it in near real-time and at scale, claims the company.
Speaker: Ahmad Jubran, Cloud Product Innovation Consultant
In this webinar, you will learn how to: Take advantage of serverless application architecture. Optimize serverless and managed data processing pipelines. Interpret and make decisions from a cloud data analytics infrastructure. Take your product a step further in the cloud with ML and AI services. And much more!
The company runs your database for you and turns it into an API so that you can query and update it from your serverless app. When you commit code changes, serverless platforms take care of deploying your application. Xata is focusing on databases and want to make it easier to integrate a database with your serverless app.
When it comes to data-intensive applications, setting up the infrastructure is expensive and time-consuming. That’s where serverless plays best — you only pay for the resources when you’re using them, not when they’re sitting idle. Serverless doesn’t mean there are no servers.
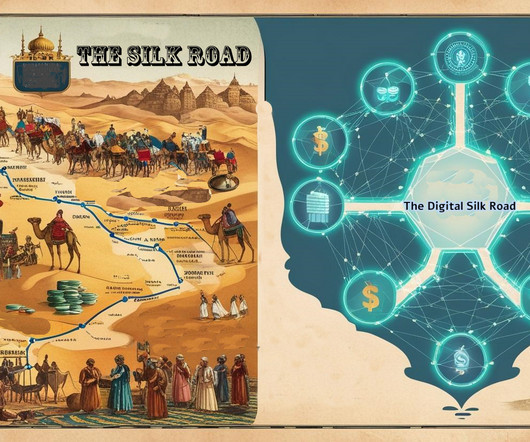
However, trade along the Silk Road was not just a matter of distance; it was shaped by numerous constraints much like todays data movement in cloud environments. Merchants had to navigate complex toll systems imposed by regional rulers, much as cloud providers impose egress fees that make it costly to move data between platforms.
As enterprises increasingly embrace serverless computing to build event-driven, scalable applications, the need for robust architectural patterns and operational best practices has become paramount. Each function should handle a specific task or domain, such as user authentication, data processing, or notification services.
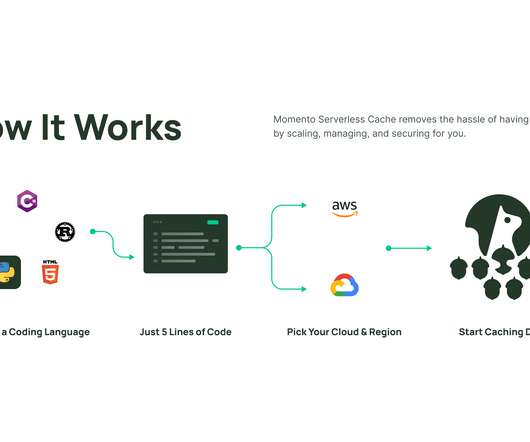
Not content to stop there, Shams and Miao left AWS to co-found Momento , a Seattle-based startup that’s today emerging from stealth with a “serverless cache” optimized for cloud computing. What’s a serverless cache, you ask?
The company focuses on data-processing workflows across multiple cloud providers. It hides many complexities using a serverless model. In order to mix-and-match those various providers, Koyeb provides the serverless glue that ties everything together. You can move and process data based on a fixed schedule or based on events.
Serverless and function as a service (FaaS) are hot terms in the software architecture world these days. All three major cloud service providers, or CSPs (Amazon, Microsoft, and Google), are heavily invested in serverless.
Cloud security startup Monad, which offers a platform for extracting and connecting data from various security tools, has launched from stealth with $17 million in Series A funding led by Index Ventures. . “Security is fundamentally a big data problem,” said Christian Almenar, CEO and co-founder of Monad.
Dataloop , a Tel Aviv-based startup that specializes in helping businesses manage the entire data life cycle for their AI projects, including helping them annotate their data sets, today announced that it has now raised a total of $16 million. ” Image Credits: Dataloop. . ” Image Credits: Dataloop. Image Credits: Dataloop.
In 2011, the Apache Software Foundation released Flink, a high-throughput, low-latency engine for streaming various data types. ” Temme acknowledges that there are other cloud services for Apache Flink, like Amazon Web Services’ (AWS) Kinesis Data Analytics and Aiven’s fully managed Apache Flink service. .
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. In this article, we delve into serverless AI/ML on AWS, exploring best practices, implementation strategies, and an example to illustrate these concepts in action.
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. An Amazon OpenSearch Serverless collection. The GitHub repo cloned to the Amazon SageMaker Studio instance.
When Pinecone launched last year, the company’s message was around building a serverless vector database designed specifically for the needs of data scientists. The system is organized into pods, which are sets of resources designed to process the data in the Pinecone database.
This blog post discusses an end-to-end ML pipeline on AWS SageMaker that leverages serverless computing, event-trigger-based data processing, and external API integrations. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
AI agents , powered by large language models (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences.
Vendia , a blockchain-based platform that makes it easier for businesses to share their code and data with partners across applications, platforms and clouds, today announced that it has raised a $30 million Series B round led by NewView Capital. for its multicloud serverless platform. Image Credits: Vendia. Vendia raises $5.1M
Use StepFunctions to simplify your serverless applications AWS StepFunctions is a great orchestrating tool for your serverless applications. A lambda function can then be used to read this object and perform some business logic on this data. You only need to do the action on the data that you receive.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. Cloud Storage Bucket: GCP’s unified object storage, allowing worldwide storage and retrieval of any amount of data.
BPM as a driver of IT success Making a significant contribution to Norma’s digital transformation, a BPM team was initiated in 2020 and its managers support all business areas to improve and harmonize the understanding of applications and processes, as well as data quality.
This article describes the implementation of RESTful API on AWS serverless architecture. It provides a detailed overview of the architecture, data flow, and AWS services that can be used. This article also describes the benefits of the serverless architecture over the traditional approach. What Is Serverless Architecture?
Businesses generate data constantly. Stream processing in the serverless cloud solves this. Gartner predicts that by 2025, over 75% of enterprise data will be processed outside traditional data centers. Confluent states that stream processing lets companies act on data as it's created. Information moves fast.
Here's a theory I have about cloud vendors (AWS, Azure, GCP): Cloud vendors 1 will increasingly focus on the lowest layers in the stack: basically leasing capacity in their data centers through an API. Redshift is a data warehouse (aka OLAP database) offered by AWS. Other pure-software providers will build all the stuff on top of it.
Macrometa , the edge computing cloud and global data network for app developers, announced today it has raised a $20 million Series A. Macrometa also made its self-service platform available to developers, who can try its serverless database, pub/sug, event processing and stateful compute runtime for free.
The company started with a focus on distributed tracing for serverless platforms like AWS’ API Gateway, DynamoDB, S3 and Lambda. “Most other Observability platforms have just tacked serverless features onto what were essentially legacy products,” said Lumigo CEO Erez Berkner. Image Credits: Lumigo.
PlanetScale , the serverless database company founded by the co-creators of the Vitess opensource project that powers YouTube, today announced that it has raised a $50 million Series C funding round led by Kleiner Perkins. ’ I think serverless is picking that up and it’s accelerating. .’
The good news is that deploying these applications on a serverless architecture can make it easier to protect them. However, it can be challenging to protect cloud-native applications that leverage serverless functions like AWS Lambda, Google Cloud Functions, and Azure Functions and Azure App Service. What is serverless?
This is the second post in a two-part series exploring the world of Serverless and Edge Runtime. In the previous post, we got familiar with serverless; the main focus of this post will be the Edge Runtime, where it can be useful, and what its caveats are. Starting with the pros: No cold starts whatsoever.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for big data workloads has traditionally been a significant challenge, often requiring specialized expertise.
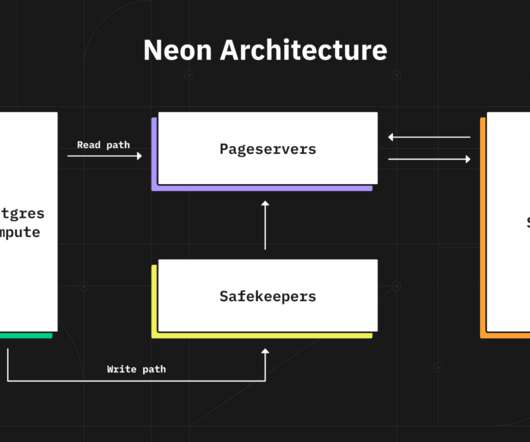
Neon , a startup providing developers with a serverless option for Postgres databases, today announced that it raised $30 million in a Series A-1 round led by GGV with participation from Khosla Ventures, General Catalyst, Founders Fund and angel investors. Many developers opt for a fully managed platform.
million terabytes of data will be generated by humans over the web and across devices. That’s just one of the many ways to define the uncontrollable volume of data and the challenge it poses for enterprises if they don’t adhere to advanced integration tech. As well as why data in silos is a threat that demands a separate discussion.
How they use data to identify friction points, and constantly experiment with changes to make things easier. Truly serverless. Serverless doesn't mean it's a burstable VM that saves its instance state to disk during periods of idle. I'm dreaming of a world where things are truly serverless. Can't wait.
Azure Key Vault Secrets integration with Azure Synapse Analytics enhances protection by securely storing and dealing with connection strings and credentials, permitting Azure Synapse to enter external data resources without exposing sensitive statistics. Data Lake Storage (Gen2): Select or create a Data Lake Storage Gen2 account.
Amazon Bedrock Custom Model Import enables the import and use of your customized models alongside existing FMs through a single serverless, unified API. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.
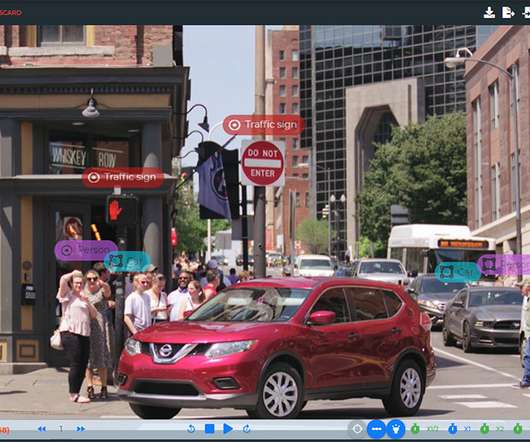
In this blog post, you will learn how to build a Serverless solution to process images using Amazon Rekognition , AWS Lambda and the Go programming language.
Ethan Batraski is a partner at Venrock and focuses on data infrastructure, open source and developer tools. Thanks to the cloud, the amount of data being generated and stored has exploded in scale and volume. As a result, enterprises, on average, store data across seven or more different databases.
Unmanaged cloud resources, human error, misconfigurations and the increasing sophistication of cyber threats, including those from AI-powered applications, create vulnerabilities that can expose sensitive data and disrupt business operations. virtual machines, containers, Kubernetes, serverless applications and open-source software).
Combine them with AWS Lambda for a serverless, cost-effective, data pipeline. Freight Clusters are ideal for high-throughput, relaxed latency workloads like telemetry and logging.
Imagine a web app that needs to authenticate users, store user data, and send emails. A Serverless approach for this would be to implement each functionality/API as a separate Lambda function. Using AWS Lambda Go runtime , you can use Go to build AWS Lambda functions.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content