This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Systemdesign can be a huge leap forward in your career both in terms of money and satisfaction you get from your job. But if your previous job was focused on working closely on one of the components of a system, it can be hard to switch to high-level thinking. Imagine switching from roofing to architectural design.
Systemdesign can be a huge leap forward in your career both in terms of money and satisfaction you get from your job. But if your previous job was focused on working closely on one of the components of a system, it can be hard to switch to high-level thinking. Imagine switching from roofing to architectural design.
Systemdesign interviews are an integral part of tech hiring and are conducted later in the interview process. Systemdesign interviews help you assess a candidate’s ability to design complex systems and understand their thought process for creating real-world products. What are systemdesign interviews? .
Systemdesign interviews are an integral part of a tech hiring process and are conducted later in the interview process. Systemdesign interviews are for assessing a candidate’s ability to design complex systems and understand their thought process for creating real-world products. to FaceCode.
For investors, the opportunity lies in looking beyond buzzwords and focusing on companies that deliver practical, scalable solutions to real-world problems. RAG is reshaping scalability and cost efficiency Daniel Marcous of April RAG, or retrieval-augmented generation, is emerging as a game-changer in AI.
In todays fast-paced digital landscape, the cloud has emerged as a cornerstone of modern business infrastructure, offering unparalleled scalability, agility, and cost-efficiency. As organizations increasingly migrate to the cloud, however, CIOs face the daunting challenge of navigating a complex and rapidly evolving cloud ecosystem.
Applying artificial intelligence (AI) to data analytics for deeper, better insights and automation is a growing enterprise IT priority. But the data repository options that have been around for a while tend to fall short in their ability to serve as the foundation for big data analytics powered by AI. Meet the data lakehouse.
This surge is driven by the rapid expansion of cloud computing and artificial intelligence, both of which are reshaping industries and enabling unprecedented scalability and innovation. For example, recent work by the University of Waterloo demonstrated that a small change in the Linux kernel could reduce data center power by as much as 30%.
Together at MIT, Marzoev and Gjengset spearheaded an open source project called Noria, a streaming data-flow systemdesigned to act as a fast storage backend for web apps. To take a step back, enterprises leverage several different kinds of databases to store, serve and analyze their app data.
Each distinct task type will likely require a separate LLM, which might also be fine-tuned with custom data. Multiple task complexity levels Some applications are designed to handle a single task type, such as text summarization or question answering. However, it also presents some trade-offs.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
These AI agents have demonstrated remarkable versatility, being able to perform tasks ranging from creative writing and code generation to data analysis and decision support. These systems are composed of multiple AI agents that converse with each other or execute complex tasks through a series of choreographed or orchestrated processes.
You might think that data collection in astronomy consists of a lone astronomer pointing a telescope at a single object in a static sky. While that may be true in some cases (I collected the data for my Ph.D. thesis this way), the field of astronomy is rapidly changing into a data-intensive science with real-time needs.
Join CodeSignal CEO Tigran Sloyan and Co-Founder Sophia Baik in Data-Drive Recruiting Episode #40 as they discuss how to conduct an effective systemdesign interview with a virtual whiteboard. Because a candidate is asked to draw the design on a whiteboard, it’s also widely known as a whiteboarding interview. more below).
Back then I was a dev-centric CIO working in a regulated Fortune 100 enterprise with strict controls on its data center infrastructure and deployment practices. Bill Murphy, director of security and compliance at LeanTaaS, says DevOps teams may not focus enough on data security.
Additionally, 72% of organizations express concerns about safeguarding sensitive data , highlighting the critical need for privately hosted AI-driven solutions to address these challenges. Integrating your Agents with Privately Hosted AI Models (LLMs) Deploying GenAI models in secure environments ensures data confidentiality.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks.
Store the data in an optimized, highly distributed datastore. Additionally, some collectors will instead poll our kafka queue for impressions data. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Time Travel to validate ahead oftime.
The experience underscored the critical need for innovative solutions that bridge the gap between newcomers and the support systemsdesigned to help them. How do we ensure that our business operations are resilient, scalable and adaptable to meet the evolving demands of our industry? Innovation.
Organizations of all sizes need a scalable solution that keeps pace with cloud initiatives, advanced attack campaigns, and digital transformation in order to thwart attacks before they have a chance to cause irreparable damage. As we venture into new territory, we must keep in mind that SOCs will always remain human at their core.
understanding what a voice is and isolating it without hyper-complex spectrum analysis, AI can make determinations like that with visual data incredibly fast and pass that on to the actual video compression part. Variable and intelligent allocation of data means the compression process can be very efficient without sacrificing image quality.
Apache Cassandra is a highly scalable and distributed NoSQL database management systemdesigned to handle massive amounts of data across multiple commodity servers. Its decentralized architecture and robust fault-tolerant mechanisms make it an ideal choice for handling large-scale data workloads.
Increased scalability and flexibility: Scalability is an essential cloud feature to handle the ever-growing amounts of enterprise data at your fingertips. Data backup and business continuity: Tools like Azure Backup are essential to protect the integrity and continuity of your business after data loss or disaster.
So as organizations face evolving challenges and digitally transform, they offer advantages to make complex business operations more efficient, including flexibility and scalability, as well as advanced automation, collaborative communication, analytics, security, and compliance features. A predominant pain point is the rider experience.
An end-to-end RAG solution involves several components, including a knowledge base, a retrieval system, and a generation system. Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models. Choose Sync to initiate the data ingestion job.
Redis in a Nutshell Redis, short for Remote Dictionary Server, is an open-source, in-memory data structure store. By keeping data in memory, Redis allows lightning-quick read and write operations, making it ideal for scenarios where speed is crucial. In this article, we’ll look at how to use Redis with Node.js
Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled. By providing an expected outcome to measure against, ground truth data unlocks the ability to deterministically evaluate system quality.
However, deploying customized FMs to support generative AI applications in a secure and scalable manner isn’t a trivial task. This is the first in a series of posts about model customization scenarios that can be imported into Amazon Bedrock to simplify the process of building scalable and secure generative AI applications.
The following is the data flow diagram of the caption generation process., The following is the data flow diagram of the caption generation process., Data intake A user uploads photos into Mixbook. S3, in turn, provides efficient, scalable, and secure storage for the media file objects themselves.
Traditional approaches rely on training machine learning models, requiring labeled data and iterative fine-tuning. These metrics help pinpoint weaknesses in individual classifiers, which can then be addressed through retraining, hyperparameter tuning, or data augmentation.
Here are three inflection points—the need for scale, a more reliable system, and a more powerful system—when a technology team might consider using a distributed system. Horizontal Scalability. Continue reading Distributed systems: A quick and simple definition.
Point solutions are still used every day in many enterprise systems, but as IT continues to evolve, the platform approach beats point solutions in almost every use case. A few years ago, there were several choices of data deduplication apps for storage, and now, it’s a standard function in every system.
The complexity of developing and deploying an end-to-end RAG solution involves several components, including a knowledge base, retrieval system, and generative language model. Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models.
FaaS functions only solve the compute part, but where is data stored and managed, and how is it accessed? The key to event-first systemsdesign is understanding that a series of events captures behavior. data written to Amazon S3). or invest in a vendor-agnostic layer like the serverless framework ?
That’s to say that when data silos develop in your organization, it causes problems. Centralizing your data with an ERP software solution is an excellent way to resolve this. This kind of tool allows you to store all your information in a secure database that links up your systems.
Prospecting, opportunity progression, and customer engagement present exciting opportunities to utilize generative AI, using historical data, to drive efficiency and effectiveness. Use case overview Using generative AI, we built Account Summaries by seamlessly integrating both structured and unstructured data from diverse sources.
It provides a powerful and scalable platform for executing large-scale batch jobs with minimal setup and management overhead. This enables you to build end-to-end workflows that leverage the full range of AWS capabilities for data processing, storage, and analytics. AWS has two services to support your HPC workload.
The same organizations building in the cloud often struggle to ensure their cloud is secure, comply with regulatory standards, and protect themselves and their customers from data breaches or disruption. Critical resources and sensitive data that were once buried beneath layers of infrastructure are now directly accessible from the internet.
When it comes to financial technology, data engineers are the most important architects. As fintech continues to change the way standard financial services are done, the data engineer’s job becomes more and more important in shaping the future of the industry. Knowledge of Scala or R can also be advantageous.
Knowledge Bases for Amazon Bedrock is a fully managed service that helps you implement the entire Retrieval Augmented Generation (RAG) workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows, pushing the boundaries for what you can do in your RAG workflows.
Amazon Simple Storage Service (S3) : for documents and processed data caching. In step 5, the lambda function triggers the Amazon Textract to parse and extract data from pdf documents. The extracted data is stored in an S3 bucket and then used as in input to the LLM in the prompts, as shown in steps 6 and 7.
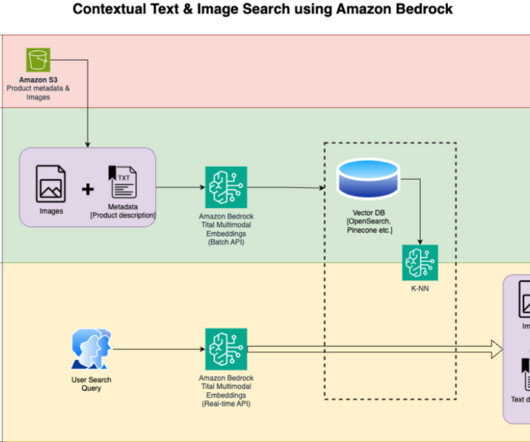
ML practitioners can perform all ML development steps—from preparing your data to building, training, and deploying ML models. The solution design consists of two parts: data indexing and contextual search. Run the solution Open the file titan_mm_embed_search_blog.ipynb and use the Data Science Python 3 kernel.
In the realm of distributed databases, Apache Cassandra has established itself as a robust, scalable, and highly available solution. Understanding Apache Cassandra Apache Cassandra is a free and open-source distributed database management systemdesigned to handle large amounts of data across multiple commodity servers.
Fundamentals of Machine Learning and Data Analytics , July 10-11. Essential Machine Learning and Exploratory Data Analysis with Python and Jupyter Notebook , July 11-12. Spotlight on Data: Improving Uber’s Customer Support with Natural Language Processing and Deep Learning with Piero Molino , July 2. Data science and data tools.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content