This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Add to this the escalating costs of maintaining legacy systems, which often act as bottlenecks for scalability. The latter option had emerged as a compelling solution, offering the promise of enhanced agility, reduced operational costs, and seamless scalability. For instance: Regulatory compliance, security and data privacy.
In 2025, data management is no longer a backend operation. The evolution of cloud-first strategies, real-time integration and AI-driven automation has set a new benchmark for data systems and heightened concerns over data privacy, regulatory compliance and ethical AI governance demand advanced solutions that are both robust and adaptive.
This blog post discusses an end-to-end ML pipeline on AWS SageMaker that leverages serverless computing, event-trigger-based data processing, and external API integrations. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
As enterprises increasingly embrace serverless computing to build event-driven, scalable applications, the need for robust architectural patterns and operational best practices has become paramount. Enterprises and SMEs, all share a common objective for their cloud infra – reduced operational workloads and achieve greater scalability.
Amazon Web Services (AWS) provides an expansive suite of tools to help developers build and manage serverless applications with ease. In this article, we delve into serverless AI/ML on AWS, exploring best practices, implementation strategies, and an example to illustrate these concepts in action.
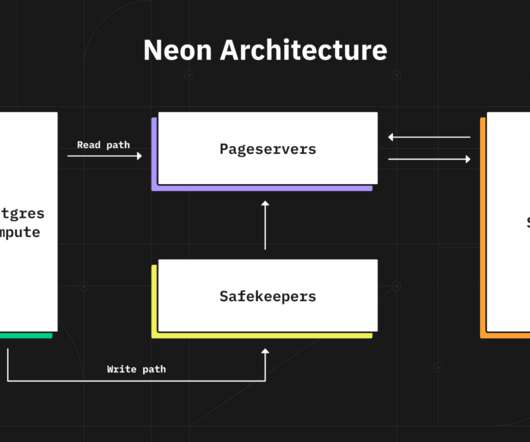
Neon , a startup providing developers with a serverless option for Postgres databases, today announced that it raised $30 million in a Series A-1 round led by GGV with participation from Khosla Ventures, General Catalyst, Founders Fund and angel investors. Many developers opt for a fully managed platform.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. This scalability allows for more frequent and comprehensive reviews. All data is encrypted in transit and at rest.
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional data integration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
AI agents , powered by large language models (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences.
Using Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. These potential vulnerabilities could be exploited by adversaries through various threat vectors.
As data volumes continue to grow, employees and customers are increasingly challenged to find the information they want. [ii] Flexible integration with multiple data types and sources Enterprise data is spread across a multitude of databases, internal applications, and software-as-a-service.
Leveraging Serverless and Generative AI for Image Captioning on GCP In today’s age of abundant data, especially visual data, it’s imperative to understand and categorize images efficiently. It’s efficient, scalable, and harnesses the best of cloud and AI! End result?
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for big data workloads has traditionally been a significant challenge, often requiring specialized expertise.
Amazon Bedrock Custom Model Import enables the import and use of your customized models alongside existing FMs through a single serverless, unified API. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.
Azure Key Vault Secrets integration with Azure Synapse Analytics enhances protection by securely storing and dealing with connection strings and credentials, permitting Azure Synapse to enter external data resources without exposing sensitive statistics. Data Lake Storage (Gen2): Select or create a Data Lake Storage Gen2 account.
Data Summit 2025 is just around the corner, and were excited to connect, learn, and share ideas with fellow leaders in the data and AI space. As the pace of innovation accelerates, events like this offer a unique opportunity to engage with peers, discover groundbreaking solutions, and discuss the future of data-driven transformation.
Limited scalability – As the volume of requests increased, the CCoE team couldn’t disseminate updated directives quickly enough. You add access control information to a document in an Amazon S3 data source using a metadata file associated with the document. Steven has been AWS Professionally certified for over 8 years.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. Security – Implementing strong access controls, encryption, and monitoring helps secure sensitive data used in your organization’s knowledge base and prevent misuse of generative AI.
million terabytes of data will be generated by humans over the web and across devices. That’s just one of the many ways to define the uncontrollable volume of data and the challenge it poses for enterprises if they don’t adhere to advanced integration tech. As well as why data in silos is a threat that demands a separate discussion.
PlanetScale , the serverless database company founded by the co-creators of the Vitess opensource project that powers YouTube, today announced that it has raised a $50 million Series C funding round led by Kleiner Perkins. ’ I think serverless is picking that up and it’s accelerating. .’
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
With the growth of the application modernization demands, monolithic applications were refactored to cloud-native microservices and serverless functions with lighter, faster, and smaller application portfolios for the past years.
The good news is that deploying these applications on a serverless architecture can make it easier to protect them. However, it can be challenging to protect cloud-native applications that leverage serverless functions like AWS Lambda, Google Cloud Functions, and Azure Functions and Azure App Service. What is serverless?
Unmanaged cloud resources, human error, misconfigurations and the increasing sophistication of cyber threats, including those from AI-powered applications, create vulnerabilities that can expose sensitive data and disrupt business operations. virtual machines, containers, Kubernetes, serverless applications and open-source software).
Architecting a multi-tenant generative AI environment on AWS A multi-tenant, generative AI solution for your enterprise needs to address the unique requirements of generative AI workloads and responsible AI governance while maintaining adherence to corporate policies, tenant and data isolation, access management, and cost control.
How they use data to identify friction points, and constantly experiment with changes to make things easier. Truly serverless. Serverless doesn't mean it's a burstable VM that saves its instance state to disk during periods of idle. I'm dreaming of a world where things are truly serverless. Can't wait.
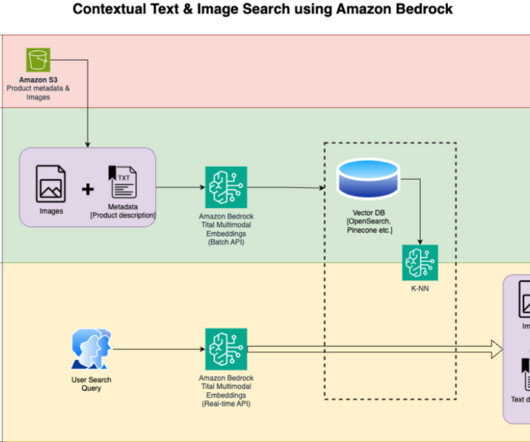
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model , available in Amazon Bedrock , with Amazon OpenSearch Serverless. The solution design consists of two parts: data indexing and contextual search.
With serverless being all the rage, it brings with it a tidal change of innovation. or invest in a vendor-agnostic layer like the serverless framework ? or invest in a vendor-agnostic layer like the serverless framework ? FaaS functions only solve the compute part, but where is data stored and managed, and how is it accessed?
Archival data in research institutions and national laboratories represents a vast repository of historical knowledge, yet much of it remains inaccessible due to factors like limited metadata and inconsistent labeling. Each bucket serves a specific purpose in the pipeline, providing organized data management and simplified access control.
DeltaStream provides a serverless streaming database to manage, secure and process data streams. “Serverless” refers to the way DeltaStream abstracts away infrastructure, allowing developers to interact with databases without having to think about servers.
Many companies across various industries prioritize modernization in the cloud for several reasons, such as greater agility, scalability, reliability, and cost efficiency, enabling them to innovate faster and stay competitive in today’s rapidly evolving digital landscape.
An open source package that grew into a distributed platform, Ngrok aims to collapse various networking technologies into a unified layer, letting developers deliver apps the same way regardless of whether they’re deployed to the public cloud, serverless platforms, their own data center or internet of things devices.
Buckle Up, Buttercup According to Unit 42 research, it can be inferred that by 2025, cloud threats will increase by 188% based on data they have observed over the past three years. This alarming upward trend highlights the urgent need for robust cloud security measures. Therefore, it'll be easier. It's definitely a misconception.
LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts. While LOBs drive their AI use cases, the central team governs guardrails, model risk management, data privacy, and compliance posture. This enables agile LOB innovation while providing centralized oversight on governance areas.
However, customer interaction data such as call center recordings, chat messages, and emails are highly unstructured and require advanced processing techniques in order to accurately and automatically extract insights. MaestroQA integrated Amazon Bedrock into their existing architecture using Amazon Elastic Container Service (Amazon ECS).
Each distinct task type will likely require a separate LLM, which might also be fine-tuned with custom data. The Pro tier, however, would require a highly customized LLM that has been trained on specific data and terminology, enabling it to assist with intricate tasks like drafting complex legal documents.
AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model. A distinguishing feature of Pixtral Large is its expansive context window of 128,000 tokens, enabling it to simultaneously process multiple images alongside extensive textual data.
The Jamstack ecosystem is brimming with serverlessdata layer options. Netlify is the glue that holds Jamstack components together, but it doesn’t provide a data layer. These partners make it easy to process and query your data, talk to a database just like any other API, whether in GraphQL or via a function.
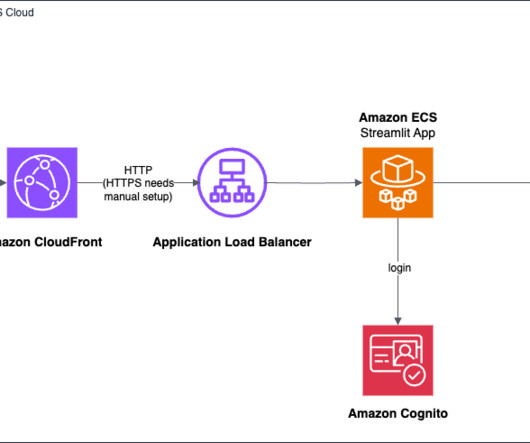
However, as exciting as these advancements are, data scientists often face challenges when it comes to developing UIs and to prototyping and interacting with their business users. Streamlit allows data scientists to create interactive web applications using Python, using their existing skills and knowledge.
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. For more details about pricing, refer to Amazon Bedrock pricing.
Companies of all sizes face mounting pressure to operate efficiently as they manage growing volumes of data, systems, and customer interactions. SageMaker Unified Studio, using Amazon DataZone , provides a comprehensive data management solution through its integrated services.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and quickly integrate and deploy them into your applications using AWS tools without having to manage the infrastructure. Fine-tuning Train the FM on data relevant to the task.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content