This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
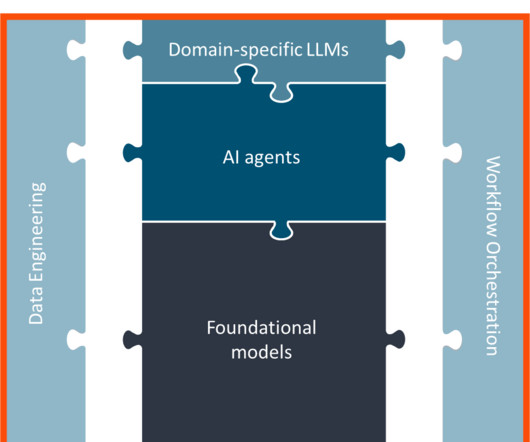
As many companies that have already adopted off-the-shelf GenAI models have found, getting these generic LLMs to work for highly specialized workflows requires a great deal of customization and integration of company-specific data. million on inference, grounding, and data integration for just proof-of-concept AI projects.
For example, because they generally use pre-trained large language models (LLMs), most organizations aren’t spending exorbitant amounts on infrastructure and the cost of training the models. And although AI talent is expensive , the use of pre-trained models also makes high-priced data-science talent unnecessary.
LLM customization Is the startup using a mostly off-the-shelf LLM — e.g., OpenAI ’s ChatGPT — or a meaningfully customized LLM? Different ways to customize an LLM include fine-tuning an off-the-shelf model or building a custom one using an open-source LLM like Meta ’s Llama. trillion to $4.4 trillion annually.
Many organizations have launched gen AI projects without cleaning up and organizing their internal data , he adds. We’re seeing a lot of the lack of success in generative AI coming down to something which, in 20/20 hindsight is obvious, which is bad data ,” he says. Access control is important, Clydesdale-Cotter adds.
One of them is Katherine Wetmur, CIO for cyber, data, risk, and resilience at Morgan Stanley. Wetmur says Morgan Stanley has been using modern data science, AI, and machine learning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space.
Industries of all types are embracing off-the-shelf AI solutions. That’s a far cry from what most online off-the-shelf AI services offer today. Most of the successful data presented by these providers is based on individual case studies, with problems involving limited data sets and limited, generic objectives.
Large language models (LLMs) are very good at spotting patterns in data of all types, and then creating artefacts in response to user prompts that match these patterns. This year saw the initial hype and excitement over AI settle down with more realistic expectations taking hold. But this isnt intelligence in any human sense.
The reasons include higher than expected costs, but also performance and latency issues; security, data privacy, and compliance concerns; and regional digital sovereignty regulations that affect where data can be located, transported, and processed. Increasingly, however, CIOs are reviewing and rationalizing those investments.
It makes sense as banks and insurance companies gather a ton of data and know a lot of information about their customers. They could use that data to train new models and roll out machine learning applications. They have developed their own models and they can see that their models work well when they run them on past data.
Here’s all that you need to make an informed choice on off the shelf vs custom software. While doing so, they have two choices – to buy a ready-made off-the-shelf solution created for the mass market or get a custom software designed and developed to serve their specific needs and requirements.
It’s a technology that utilizes RPA tools to carry out actions such as data modification, transaction processing, and computer communications, just to name a few. If workers are not trained, a business won’t be able to harness the benefits of this technology. However, any chosen RPA solution has obstacles to conquer.
25, 2021 — Appen Limited (ASX:APX), the leading provider of high-quality trainingdata for organizations that build effective AI systems at scale, today announced new off-the-shelf (OTS) datasets. The post New Off-the-Shelf (OTS) Datasets from Appen Accelerate AI Deployment appeared first on DevOps.com.
The trio had the idea to use drones to gather data — specifically data in warehouses, such as the number of items on a shelf and the locations of particular pallets. Arora co-founded Gather AI in 2019 with Daniel Maturana and Geetesh Dubey, graduate students at Carnegie Mellon’s Robotics Institute.
Last month, Google’s DeepMind robotics team showed off its own impressive work, in the form of RT-2 (Robotic Transformer 2). Passive learning in this instance is teaching a system to perform a task by showing it videos or training it on the aforementioned datasets. The past year, we’ve seen a large number of fascinating studies.
million (~$6.1M) funding round off the back of increased demand for its computer vision training platform. “Our custom training user interface is very simple to work with, and requires no prior technical knowledge on any level,” claims Appu Shaji, CEO and chief scientist. . Berlin-based Mobius Labs has closed a €5.2
The chief information and digital officer for the transportation agency moved the stack in his data centers to a best-of-breed multicloud platform approach and has been on a mission to squeeze as much data out of that platform as possible to create the best possible business outcomes. Data engine on wheels’. NJ Transit.
Data science teams are stymied by disorganization at their companies, impacting efforts to deploy timely AI and analytics projects. In a recent survey of “data executives” at U.S.-based ” The market for synthetic data is bigger than you think. These are ultimately organizational challenges.
For years grocery retailers have been using data driven forecasting to help them predict demand to figure out which products to reorder to keep shelves stocked. That’s nothing new. revenue boost. ” “And because that is the opinion … until now, for the most part, retailers have just relied upon people to do this part.”
Generative AI gives organizations the unique ability to glean fresh insights from existing data and produce results that go beyond the original input. Companies eager to harness these benefits can leverage ready-made, budget-friendly models and customize them with proprietary business data to quickly tap into the power of AI.
Among their biggest concerns: exposing intellectual property through publicly available generative AI models, revealing the personal data of users to third-party vendors or service providers, and securing the AI itself from criminal hackers. This type of AI assistant can be delivered through a pre-built, off-the-shelf AI solution.
Just some examples from things I've worked on or close to: Spotify built a whole P2P architecture in C++ in order to distribute streaming music to listeners, something which today is a trivial problem (put the data on a CDN). It's a popular attitude among developers to rant about our tools and how broken things are.
Data Scientist Cathy O’Neil has recently written an entire book filled with examples of poor interpretability as a dire warning of the potential social carnage from misunderstood models—e.g., There is also a trade off in balancing a model’s interpretability and its performance.
Online education tools continue to see a surge of interest boosted by major changes in work and learning practices in the midst of a global health pandemic. The funding will be used to continue investing in its platform to target more business customers. Now it’s time to build out a sales team to go after them.”
Instead, human cells being used now in these clinical trials are mostly being made by hand by scientists who are looking at cells and evaluating — using their many years of training and expertise — which cells are low quality and need to be removed. — could eventually democratize access to cell therapies.
The pro-code platform empowers responsible generative AI development, including the development of copilots, to support complex applications and tasks like content generation, data analysis, project management, automation of routine tasks, and more,” Jyoti said. At least that’s what analysts say. Azure AI Studio is a key component.
Many organizations know that commercially available, “off-the-shelf” generative AI models don’t work well in enterprise settings because of significant data access and security risks. Lesson 1: Don’t start from scratch to train your LLM model Massive amounts of data and computational resources are needed to train an LLM.
As an extension of the country’s Vision 2030, the Saudi Data and AI Authority (SDAIA) was established in 2019, followed by the release of the National Strategy for Data and AI in 2020. These are vision, people, process, technology, and data readiness. over the 2021–2025 period.
As an extension of the country’s Vision 2030, the Saudi Data and AI Authority (SDAIA) was established in 2019, followed by the release of the National Strategy for Data and AI in 2020. These are vision, people, process, technology, and data readiness. over the 2021–2025 period.
Second, the leaders in the generative AI arms race will be those who are able to get their data organized and accessible quickly. The challenge now, of course, is separating the hype from reality to move forward on a path that makes sense for real businesses. Where will the biggest transformation occur first?
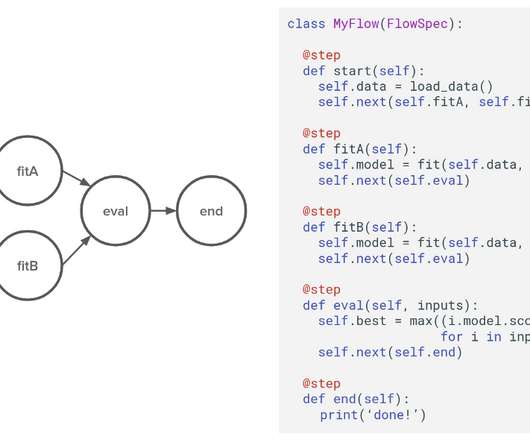
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. Why: Data Makes It Different. The new category is often called MLOps. The new category is often called MLOps. However, the concept is quite abstract.
Many customers find the sweet spot in combining them with similar low code/no code tools for data integration and management to quickly automate standard tasks, and experiment with new services. So there’s a lot in the plus column, but there are reasons to be cautious, too. It’s for speed to market,” says CTO Vikram Ramani.
From infrastructure to tools to training, Ben Lorica looks at what’s ahead for data. Whether you’re a business leader or a practitioner, here are key data trends to watch and explore in the months ahead. Increasing focus on building data culture, organization, and training. Cloud for data infrastructure.
As OpenAI’s exclusive cloud provider it will see additional revenue for its Azure services, as one of OpenAI’s biggest costs is providing the computing capacity to train and run its AI models. Microsoft stands to benefit from its investment in three ways. The deal, announced by OpenAI and Microsoft on Jan.
Over the years, they’ve created a virtual make-up try-on tool using augmented reality, played around with intelligent mirrors, and used AI to build their personalization engine, which intelligently mines customer data to give product recommendations. The goal is to experiment quickly and identify solutions that appeal to customers.
With AI, quote turnaround can go from 12 hours to 20 minutes , training time drops by 90%, and sales productivity goes through the roof. This goes beyond the lift and shift integration of data from the legacy system to the new platform. This goes beyond the lift and shift integration of data from the legacy system to the new platform.
But unlike Amazon Go stores, which use cameras and sensors to monitor the shopper as they walk in and out without scanning or paying at checkout, this New Zealand-based company thinks the only images that should be captured and analyzed are those of products going into a shopping cart. Chomley says Imagr has raised a total of $12.5
However, CIOs looking for computing power needed to train AIs for specific uses, or to run huge AI projects will likely see value in the Blackwell project. They basically have a comprehensive solution from the chip all the way to data centers at this point,” he says. Thus, the need for Blackwell should be strong.”
Examples include GitHub Copilot, an off-the-shelf solution to generate code, or Adobe Firefly, which assists designers with image generation and editing. It does not allow for integration of proprietary data and offers the fewest privacy and IP protections. There are two common approaches for Shapers.
Large language models (LLMs) are hard to beat when it comes to instantly parsing reams of publicly available data to generate responses to general knowledge queries. Moreover, challenges around data privacy and recognition of intellectual property often require a level of transparency that simply does not exist in many off-the-shelf models.
The surprise wasnt so much that DeepSeek managed to build a good modelalthough, at least in the United States, many technologists havent taken seriously the abilities of Chinas technology sectorbut the estimate that the training cost for R1 was only about $5 million. Thats roughly 1/10th what it cost to train OpenAIs most recent models.
We don’t want to just go off to the next shiny object,” she says. “We Leveraging expertise at software developer Palantir Technologies, Redmond’s team developed a model that consolidated and cleansed the data from those systems, then analyzed it to provide insights — and fairly sophisticated recommendations — to decision makers.
Valence , a growing teamwork platform, today announced that it raised $25 million in a Series A round led by Insight Partners. Co-founder and CEO Parker Mitchell said that the tranche will be used to triple the size of the company’s team to 75, expand its sales footprint (particularly in Europe), and build out Valence’s product team.
Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. Data scientists at Netflix relish our culture that empowers them to work autonomously and use their judgment to solve problems independently. How could we improve the quality of life for data scientists?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content