This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the more tedious aspects of machinelearning is providing a set of labels to teach the machinelearning model what it needs to know. It also announced a new tool called Application Studio that provides a way to build common machinelearning applications using templates and predefined components.
Meet Taktile , a new startup that is working on a machinelearning platform for financial services companies. This isn’t the first company that wants to leverage machinelearning for financial products. They could use that data to train new models and roll out machinelearning applications.
We’re living in a phenomenal moment for machinelearning (ML), what Sonali Sambhus , head of developer and ML platform at Square, describes as “the democratization of ML.” When it comes to recruiting for ML, hire experts when you can, but also look into how training can help you meet your talent needs. ML recruiting strategy.
Tecton.ai , the startup founded by three former Uber engineers who wanted to bring the machinelearning feature store idea to the masses, announced a $35 million Series B today, just seven months after announcing their $20 million Series A. “We help organizations put machinelearning into production.
From customer service chatbots to marketing teams analyzing call center data, the majority of enterprises—about 90% according to recent data —have begun exploring AI. For companies investing in data science, realizing the return on these investments requires embedding AI deeply into business processes.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
While many organizations have already run a small number of successful proofs of concept to demonstrate the value of gen AI , scaling up those PoCs and applying the new technology to other parts of the business will never work until producing AI-ready data becomes standard practice. This tends to put the brakes on their AI aspirations.
Adam Oliner, co-founder and CEO of Graft used to run machinelearning at Slack, where he helped build the company’s internal artificial intelligence infrastructure. The market for synthetic data is bigger than you think. “We He says the beauty of the solution is that it provides everything you need to get started.
The data and AI industries are constantly evolving, and it’s been several years full of innovation. Yet, today’s data scientists and AI engineers are expected to move quickly and create value. Explainability is also still a serious issue in AI, and companies are overwhelmed by the volume and variety of data they must manage.
Called OpenBioML , the endeavor’s first projects will focus on machinelearning-based approaches to DNA sequencing, protein folding and computational biochemistry. Stability AI’s ethically questionable decisions to date aside, machinelearning in medicine is a minefield. Image Credits: OpenBioML.
In 2025, insurers face a data deluge driven by expanding third-party integrations and partnerships. Many still rely on legacy platforms , such as on-premises warehouses or siloed data systems. Step 1: Data ingestion Identify your data sources. First, list out all the insurance data sources.
In todays economy, as the saying goes, data is the new gold a valuable asset from a financial standpoint. A similar transformation has occurred with data. More than 20 years ago, data within organizations was like scattered rocks on early Earth.
Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. This approach reduces memory pressure and enables efficient training of large models.
While LLMs are trained on large amounts of information, they have expanded the attack surface for businesses. From prompt injections to poisoning trainingdata, these critical vulnerabilities are ripe for exploitation, potentially leading to increased security risks for businesses deploying GenAI.
Hes seeing the need for professionals who can not only navigate the technology itself, but also manage increasing complexities around its surrounding architectures, data sets, infrastructure, applications, and overall security. There are data scientists, but theyre expensive, he says.
Educate and train help desk analysts. Equip the team with the necessary training to work with AI tools. Prioritize high quality data Effective AI is dependent on high quality data. The number one help desk data issue is, without question, poorly documented resolutions,” says Taylor. Click here to find out more.
A Name That Matches the Moment For years, Clouderas platform has helped the worlds most innovative organizations turn data into action. Thats why were moving from Cloudera MachineLearning to Cloudera AI. But over the years, data teams and data scientists overcame these hurdles and AI became an engine of real-world innovation.
AI and machinelearning are poised to drive innovation across multiple sectors, particularly government, healthcare, and finance. Data sovereignty and the development of local cloud infrastructure will remain top priorities in the region, driven by national strategies aimed at ensuring data security and compliance.
We are happy to share our learnings and what works — and what doesn’t. The whole idea is that with the apprenticeship program coupled with our 100 Experiments program , we can train a lot more local talent to enter the AI field — a different pathway from traditional academic AI training. And why that role?
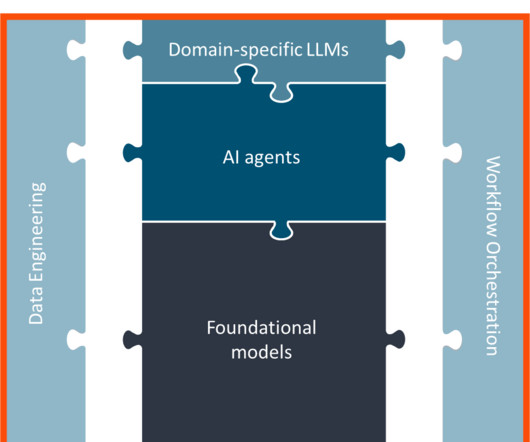
AI’s ability to automate repetitive tasks leads to significant time savings on processes related to content creation, data analysis, and customer experience, freeing employees to work on more complex, creative issues. Building a strong, modern, foundation But what goes into a modern data architecture?
Strong Compute , a Sydney, Australia-based startup that helps developers remove the bottlenecks in their machinelearningtraining pipelines, today announced that it has raised a $7.8 ” Strong Compute wants to speed up your ML model training. . ” Strong Compute wants to speed up your ML model training.
When it comes to AI, the secret to its success isn’t just in the sophistication of the algorithms — it’s in the quality of the data that powers them. AI has the potential to transform industries, but without reliable, relevant, and high-quality data, even the most advanced models will fall short.
LLMs deployed as internal enterprise-specific agents can help employees find internal documentation, data, and other company information to help organizations easily extract and summarize important internal content. Given some example data, LLMs can quickly learn new content that wasn’t available during the initial training of the base model.
Most artificial intelligence models are trained through supervised learning, meaning that humans must label raw data. Data labeling is a critical part of automating artificial intelligence and machinelearning model, but at the same time, it can be time-consuming and tedious work. ScreenShot | AIMMO website.
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. Companies can enrich these versatile tools with their own data using the RAG (retrieval-augmented generation) architecture.
These days Data Science is not anymore a new domain by any means. The time when Hardvard Business Review posted the Data Scientist to be the “Sexiest Job of the 21st Century” is more than a decade ago [1]. In 2019 alone the Data Scientist job postings on Indeed rose by 256% [2]. Why is that? That is massively useful.
As Artificial Intelligence (AI)-powered cyber threats surge, INE Security , a global leader in cybersecurity training and certification, is launching a new initiative to help organizations rethink cybersecurity training and workforce development.
The data landscape is constantly evolving, making it challenging to stay updated with emerging trends. That’s why we’ve decided to launch a blog that focuses on the data trends we expect to see in 2025. Poor data quality automatically results in poor decisions. That applies not only to GenAI but to all data products.
The implementation was a over-engineered custom Feast implementation using unsupported backend data stores. Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. This becomes more important when a company scales and runs more machinelearning models in production.
In the past, creating a new AI model required data scientists to custom-build systems from a frustrating parade of moving parts, but Z by HP has made it easy with tools like Data Science Stack Manager and AI Studio. In some cases, the data ingestion comes from cameras or recording devices connected to the model.
Modern Pay-As-You-Go Data Platforms: Easy to Start, Challenging to Control It’s Easier Than Ever to Start Getting Insights into Your Data The rapid evolution of data platforms has revolutionized the way businesses interact with their data. The result? Yet, this flexibility comes with risks.
The McKinsey 2023 State of AI Report identifies data management as a major obstacle to AI adoption and scaling. Enterprises generate massive volumes of unstructured data, from legal contracts to customer interactions, yet extracting meaningful insights remains a challenge.
Betterdata , a Singapore-based startup that uses programmable synthetic data to keep real data secure, announced today it has raised $1.55 Betterdata says it is different from traditional data sharing methods that use data anonymization to destroy data because it utilizes generative AI and privacy engineering instead.
Modern Pay-As-You-Go Data Platforms: Easy to Start, Challenging to Control It’s Easier Than Ever to Start Getting Insights into Your Data The rapid evolution of data platforms has revolutionized the way businesses interact with their data. The result? Yet, this flexibility comes with risks.
Re-platforming to reduce friction Marsh McLennan had been running several strategic data centers globally, with some workloads on the cloud that had sprung up organically. Several co-location centers host the remainder of the firm’s workloads, and Marsh McLennans big data centers will go away once all the workloads are moved, Beswick says.
About the NVIDIA Nemotron model family At the forefront of the NVIDIA Nemotron model family is Nemotron-4, as stated by NVIDIA, it is a powerful multilingual large language model (LLM) trained on an impressive 8 trillion text tokens, specifically optimized for English, multilingual, and coding tasks. You can find him on LinkedIn.
In these cases, the AI sometimes fabricated unrelated phrases, such as “Thank you for watching!” — likely due to its training on a large dataset of YouTube videos. Another machinelearning engineer reported hallucinations in about half of over 100 hours of transcriptions inspected.
Much of the AI work prior to agentic focused on large language models with a goal to give prompts to get knowledge out of the unstructured data. For example, in the digital identity field, a scientist could get a batch of data and a task to show verification results. So its a question-and-answer process. Agentic AI goes beyond that.
growth this year, with data center spending increasing by nearly 35% in 2024 in anticipation of generative AI infrastructure needs. Data center spending will increase again by 15.5% in 2025, but software spending — four times larger than the data center segment — will grow by 14% next year, to $1.24 trillion, Gartner projects.
The use of synthetic data to train AI models is about to skyrocket, as organizations look to fill in gaps in their internal data, build specialized capabilities, and protect customer privacy, experts predict. Gartner, for example, projects that by 2028, 80% of data used by AIs will be synthetic, up from 20% in 2024.
As many companies that have already adopted off-the-shelf GenAI models have found, getting these generic LLMs to work for highly specialized workflows requires a great deal of customization and integration of company-specific data. million on inference, grounding, and data integration for just proof-of-concept AI projects.
It lets you take advantage of the data science platform without going through a complicated setup process that involves a system administrator and your own infrastructure. In particular, Dataiku can be used by data scientists, but also business analysts and less technical people. There are two ways to use Dataiku.
Union AI , a Bellevue, Washington–based open source startup that helps businesses build and orchestrate their AI and data workflows with the help of a cloud-native automation platform, today announced that it has raised a $19.1 But there was always friction between the software engineers and machinelearning specialists.
These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is a complex and resource-intensive process, often requiring specialized expertise and significant computational resources.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content