This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Some techniques we used were: 1.
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. Window functions . Window functions are very useful if you want to run a calculation on a set of rows that are related in some way (ie.
Image Credits: Kuzma (opens in a new window) / Getty Images. Is the modern data stack just old wine in a new bottle? Image Credits: Mikhail Dmitriev (opens in a new window) / Getty Images. “Our statistics team then used the clean, updated data to model the best offer for each household.”
” The tool Airbnb built was Minerva , optimised specifically for the kinds of questions Airbnb might typically have for its own data. ” Image Credits: Transform (opens in a new window). ” Instead, we now embrace — as Mayfield put it — “If you can’t measure it, you can’t move it.”
Microsoft Certified: Windows Server Hybrid Administrator Associate?Microsoft 31?????????????????????????????????????????????Azure?Power Power Platform?Fundamentals?????Security, Fundamentals?????Security, Security, Compliance and Identity??????????????????? ?11/20????????????Microsoft 11/20????????????Microsoft The post Microsoft????31????????Azure??
Microsoft Windows Codecs Library. Windows Hyper-V. Tablet Windows User Interface. Windows Account Control. Windows Active Directory. Windows AppContracts API Server. Windows Application Model. Windows BackupKey Remote Protocol. Windows Bind Filter Driver. Windows Certificates.
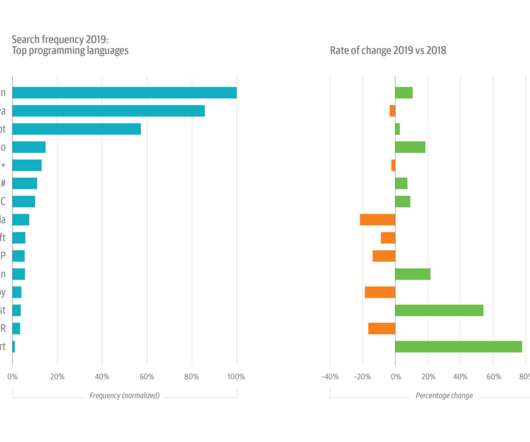
The results for data-related topics are both predictable and—there’s no other way to put it—confusing. Starting with dataengineering, the backbone of all data work (the category includes titles covering data management, i.e., relational databases, Spark, Hadoop, SQL, NoSQL, etc.). This follows a 3% drop in 2018.
Image Credits: V7 Labs (opens in a new window). Investors think that the framework that V7 is building might potentially change how data is ingested by those enterprises in the future. “This is where V7’s AI DataEngine shines. “We are instead working for actual applications,” he said.
Today it’s Prophecy raising $25 million for its “low-code dataengineering platform.”. Image Credits: DigtialStorm (opens in a new window) / Getty Images. When TechCrunch covered the Softr round the other day , we asked internally what had happened to all the no-code rounds. Well, here they are.
This includes high-demand roles like Full stack- Django/React, Full stack- Django/Angular, Full stack- Django/Spring/ React, Full stack- Django/Spring/Angular, Dataengineer, and DevOps engineer. We have 20 pre-defined roles available now, and we intend to add more to the stack.
Data is a key component when it comes to making accurate and timely recommendations and decisions in real time, particularly when organizations try to implement real-time artificial intelligence. Real-time AI involves processing data for making decisions within a given time frame.
Everybody needs more data and more analytics, with so many different and sometimes often conflicting needs. Dataengineers need batch resources, while data scientists need to quickly onboard ephemeral users. Meanwhile, some workloads hog resources making others miss defined agreements.
During development we use interactive notebooks and query historical data stored on a data lake or warehouse. All data is available, so creating stateful features using window functions is straight forward. We convert this logic to a batch pipelines when moving to production.
In the data layer its portfolio company Revifi is a copilot for dataengineers. Chaddha ran Windows Media and was a peer of Microsoft’s CEO Satya Nadella. An investor since 2004, he witnessed the social, mobile and cloud computing waves that engineered new companies. In model safety it has invested in Securiti.
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate. Check out Windows Server On Linux Academy Cloud Playground if you haven’t already!
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support AI, BI, ML, and dataengineering on a single platform.” According to Gartner, Inc.
This will open a new window. A new window will open. A new window will open, where we can search for our Service Principal and add the permission Can Use. We will first navigate to the Data page, select the appropriate catalog (default is hive_metastore ), select the Permissions tab and click on Grant.
As long as the LookML file doesn’t exceed the context window of the LLM used to generate the final response, we don’t split the file into chunks and instead pass the file in its entirety to the embeddings model. The two subsets of LookML metadata provide distinct types of information about the data lake.
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate. Check out Windows Server On Linux Academy Cloud Playground if you haven’t already!
This project approach means that students first start with the building blocks of streams and tables and then proceed onto advanced KSQL areas, such as topic rekeying, data encoding (CSV, JSON, and Avro), stream merging, and time-based windowing.
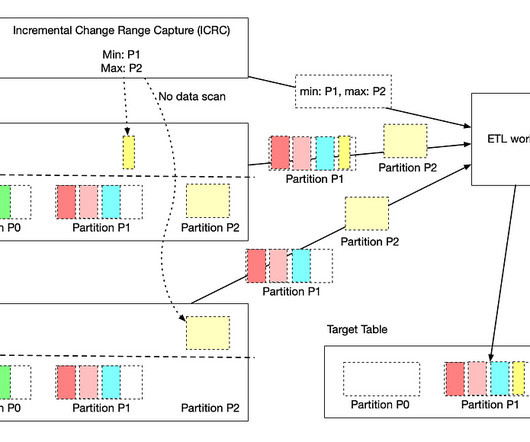
Data Accuracy: Late arriving data causes datasets processed in the past to become incomplete and as a result inaccurate. To compensate for that, ETL workflows often use a lookback window, based on which they reprocess the data in that certain time window. data arrives too late to be useful).
The organization now has dataengineers, data scientists, and is investing in cutting-edge technologies like quantum computing. “In That was a big change for the organization because we are a seasonal business and our opportunity to generate revenue is limited in a window. That was a large move.
also delivers endpoint detection and response (EDR)-level protection for cloud assets, including Windows and Linux virtual machines and Kubernetes containers. Cortex XDR’s Third-Party DataEngine Now Delivers the Ability to Ingest, Normalize, Correlate, Query and Analyze Data from Virtually Any Source. With Cortex XDR 3.0
. # Select first column value at the top and bottom of the dataset: head -n2 ~/Downloads/Open_Data_RDW_* | tail -n1 | cut -d, -f1 tail -n1 ~/Downloads/Open_Data_RDW_* | cut -d, -f1 # Output: # first: MR56LN # last: MR56LG Load the dataset in a spark session and create a temporary view to query the dataset. getOrCreate() print(spark.version) # 4.0.0-preview
As businesses are moving more and more towards real-time data movement instead of hourly/daily batches, data bursts become more visible and less predictable mainly due to two reasons: Once the hourly/daily batch windows are removed, there’s nothing left that aggregates and averages out lows and peaks. Democratization of Data.
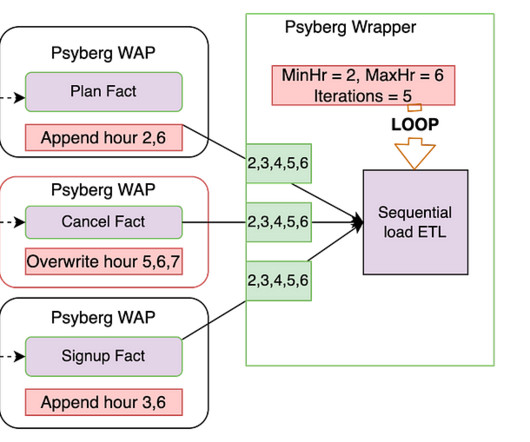
Since this ETL operates in stateful mode, the data in the target table from hours 5 to 7 will be overwritten with the new data. By focusing solely on updates and avoiding reprocessing of data based on a fixed lookback window, both Stateless and Stateful Data Processing maintain a minimal change footprint.
On the other hand, a business that needs efficiency to scale may be better served by a central team that provides functions like data governance, platform engineering, architecture, and dataengineering to all areas of the business. Heavily regulated industries tend to centralize.
It should look something like the following: [link] Choose Generate SQL query to open the chat window. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and dataengineering. Count of orders placed from India last month?
The Confluent Platform is an amazing toolbox, which every architect and dataengineer should know of and utilize. Why does on-chain data matter? When forks happen, we usually see two forks, but sometimes up to four forks in a six-confirmation time window. He’s familiar with batch processing tasks in Spark and Flink.
It unifies self-service data science and dataengineering in a single, portable service as part of an enterprise data cloud for multi-function analytics on data anywhere. Navigate to Runtime/Engine tab. Cloudera Machine Learning (CML) is a cloud-native and hybrid-friendly machine learning platform.
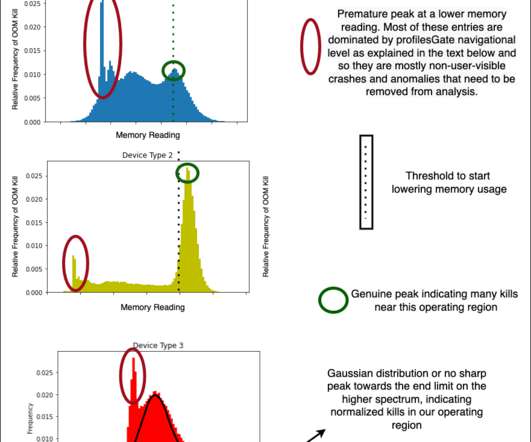
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers.
However, arriving at specs for other aspects of network performance requires extensive monitoring, dashboarding, and dataengineering to unify this data and help make it meaningful. Direct business demands like SLAs (service level agreements) help define firm boundaries for network performance.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
Moreover, it is a period of dynamic adaptation, where documentation and operational protocols will adapt as your data and technology landscape change. This functionality allows our customers to run periodic backups or as needed during business hours and maintenance windows. How does Cloudera support Day 2 operations?
AWS Amplify is a good choice as a development platform when: Your team is proficient with building applications on AWS with DevOps, Cloud Services and DataEngineers. You’re developing a greenfield application that doesn’t require any external data or auth systems. You have existing backend services developed on AWS.
AWS Amplify is a good choice as a development platform when: Your team is proficient with building applications on AWS with DevOps, Cloud Services and DataEngineers. You’re developing a greenfield application that doesn’t require any external data or auth systems. You have existing backend services developed on AWS.
AWS Amplify is a good choice as a development platform when: Your team is proficient with building applications on AWS with DevOps, Cloud Services and DataEngineers. You’re developing a greenfield application that doesn’t require any external data or auth systems. You have existing backend services developed on AWS.
Apache NiFi empowers dataengineers to orchestrate data collection, distribution, and transformation of streaming data with capacities of over 1 billion events per second. . Apache Kafka helps data administrators and streaming app developers to buffer high volumes of streaming data for high scalability.
cleansing, feature engineering, CDC reconciliation) or for stream analytics (e.g. alert when threshold exceeded over a rolling window of statistics on the data, score the event data against a predictive model to decide which action to take next). Data Hub – . Data Hub – .
ETL jobs and staging of data often often require large amounts of resources. ETL is a dataengineering task and should be offloaded onto a scale-out and more cost effective solution. . Similarly, operational data stores take up resources on a data warehouse. They too can be moved to a more cost effective platform.
It’ll make using of Python better for sure (and not just on Windows),” promised the Dutch programmer in his tweet. Python is platform-agnostic: You can run the same source code across operating systems, be it macOS, Windows, or Linux. There are options for Windows, Linux/UNIX, macOS, and other platforms.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content