This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
Dataengineering is one of these new disciplines that has gone from buzzword to mission critical in just a few years. As data has exploded, so has their challenge of doing this key work, which is why a new set of tools has arrived to make dataengineering easier, faster and better than ever.
Prophecy , a low-code platform for dataengineering, today announced that it has raised a $25 million Series A round led by Insight Partners. And since many enterprises are still using legacy tools, Prophecy also built a transpiler that allows businesses to modernize their existing ETL workflows.
The proposed model illustrates the data management practice through five functional pillars: Data platform; dataengineering; analytics and reporting; data science and AI; and data governance. Operational errors because of manual management of data platforms can be extremely costly in the long run.
Speaker: Dave Mariani, Co-founder & Chief Technology Officer, AtScale; Bob Kelly, Director of Education and Enablement, AtScale
Check out this new instructor-led training workshop series to help advance your organization's data & analytics maturity. It includes on-demand video modules and a free assessment tool for prescriptive guidance on how to further improve your capabilities. Workshop video modules include: Breaking down data silos.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines that convert raw data into formats usable by data scientists, data-centric applications, and other data consumers.
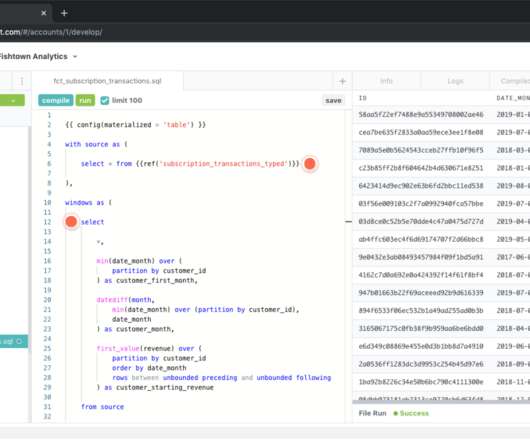
Fishtown Analytics , the Philadelphia-based company behind the dbt open-source dataengineeringtool, today announced that it has raised a $29.5 The company is building a platform that allows data analysts to more easily create and disseminate organizational knowledge. Fishtown Analytics raises $12.9M
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
It shows in his reluctance to run his own servers but it’s perhaps most obvious in his attitude to dataengineering, where he’s nearing the end of a five-year journey to automate or outsource much of the mundane maintenance work and focus internal resources on data analysis. It’s not a good use of our time either.”
It's a popular attitude among developers to rant about our tools and how broken things are. I had my first job as a software engineer in 1999, and in the last two decades I've seen software engineering changing in ways that have made us orders of magnitude more productive. The insatiable demand for software.
Gen AI-related job listings were particularly common in roles such as data scientists and dataengineers, and in software development. Were building a department of AI engineering, mostly by bringing in people from dataengineering and training them to work with gen AI and AI in general, says Daniel Avancini, Indiciums CDO.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
After the launch of CDP DataEngineering (CDE) on AWS a few months ago, we are thrilled to announce that CDE, the only cloud-native service purpose built for enterprise dataengineers, is now available on Microsoft Azure. . Prerequisites for deploying CDP DataEngineering on Azure can be found here.
There are three core roles involved in ML modeling, but each one has different motivations and incentives: Dataengineers: Trained engineers excel at gleaning data from multiple sources, cleaning it and storing it in the right formats so that analysis can be performed. The proliferation of ML tools.
Seventy percent of those IT pros spend one to four hours a day remediating data issues, while 14% spend more than four hours each day, according to the survey. Theres a perspective that well just throw a bunch of data at the AI, and itll solve all of our problems, he says.
Mage , developing an artificial intelligence tool for product developers to build and integrate AI into apps, brought in $6.3 Founder Tommy Dang started the company at the end of 2020 after working together to build internal low-code tools at Airbnb. million in seed funding led by Gradient Ventures. Shirazi found that in Mage.
People : To implement a successful Operational AI strategy, an organization needs a dedicated ML platform team to manage the tools and processes required to operationalize AI models. The team should be structured similarly to traditional IT or dataengineering teams.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community! In this video, Sr.
This creates the opportunity for combining lightweight tools like DuckDB with Unity Catalog. To get similar notebook integration, we have built a solution using Jupyter notebooks, a web-based tool for interactive computing. Dbt is a popular tool for transforming data in a data warehouse or data lake.
The raw data can be streamed using a variety of methods, either batch or streaming (using a message broker such as Kafka). Platforms like Databricks offer built-in tools like autoloader to make this ingestion process seamless. Next, clean and organize the raw data. Silver layer: Clean and standardize.
DevOps continues to get a lot of attention as a wave of companies develop more sophisticated tools to help developers manage increasingly complex architectures and workloads. “Users didn’t know how to organize their tools and systems to produce reliable data products.”
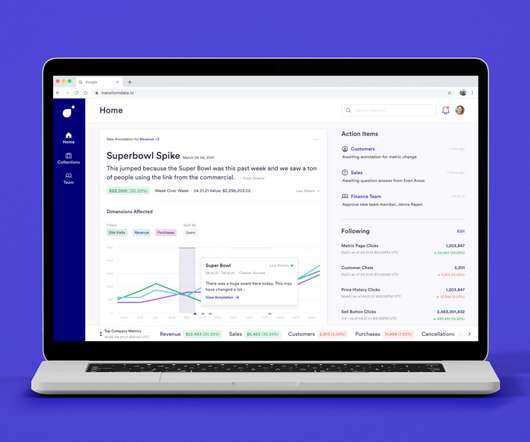
Now, three alums that worked with data in the world of Big Tech have founded a startup that aims to build a “metrics store” so that the rest of the enterprise world — much of which lacks the resources to build tools like this from scratch — can easily use metrics to figure things out like this, too.
Provide user interfaces for consuming data. Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Choose the right tools and technologies.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Data pipelines are composed of multiple steps with dependencies and triggers. New in 2021.
By early 2024, according to a report from Microsoft , 75% of employees reported using AI at work, with 80% of that population using tools not sanctioned by their employers. People feel overwhelmed; they need solutions fast, and if we dont give them the right tools, theyll find their own.
At the same time, the scale of observability data generated from multiple tools exceeds human capacity to manage. With situational insights, IT operations, SREs, DevOps, and platform engineering teams can reduce time to remediation and quickly restore services with a pre-built set of automations.
The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows. The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both.
This is a use case thats been rolled out widely, he says, though not all tools are available to all employees. With these paid versions, our data remains secure within our own tenant, he says. Today, all customer service representatives use the gen AI tool, which is over 40,000 people.
For example, events such as Twitters rebranding to X, and PySparks rise in the dataengineering realm over Spark have all contributed to this decline. In my opinion, sbt (Simple Build Tool) is a perfect example of this evolution. Various business decisions have altered its public perception.
to GPT-o1, the list keeps growing, along with a legion of new tools and platforms used for developing and customizing these models for specific use cases. To integrate AI into enterprise workflows, we must first do the foundation work to get our clients data estate optimized, structured, and migrated to the cloud. From Llama3.1
Job titles like dataengineer, machine learning engineer, and AI product manager have supplanted traditional software developers near the top of the heap as companies rush to adopt AI and cybersecurity professionals remain in high demand. Theres real hand-holding that needs to be done.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
And since the latest hot topic is gen AI, employees are told that as long as they don’t use proprietary information or customer code, they should explore new tools to help develop software. These tools help people gain theoretical knowledge,” says Raj Biswas, global VP of industry solutions.
The development- and operations world differ in various aspects: Development ML teams are focused on innovation and speed Dev ML teams have roles like Data Scientists, DataEngineers, Business owners. Cloud providers have answered the market need for better tooling in the Machine Learning space. That is massively useful.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
They also use tools like Amazon Web Services and Microsoft Azure. Big DataEngineer. Another highest-paying job skill in the IT sector is big dataengineering. And as a big dataengineer, you need to work around the big data sets of the applications. AI or Artificial Intelligence Engineer.
dbt (data build tool) has seen increasing use in recent years as a tool to transform data in data warehouses. of the repository, while other times this is in an external tool like Confluence or Notion. As with any new tool, one question that is commonly asked is about its speed. But what about dbt?
Dataengineers have a big problem. Almost every team in their business needs access to analytics and other information that can be gleaned from their data warehouses, but only a few have technical backgrounds. The New York-based startup announced today that it has raised $7.6
introduces available tools and platforms to automate MLOps steps. It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in dataengineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development.
MLOps, or Machine Learning Operations, is a set of practices that combine machine learning (ML), dataengineering, and DevOps to streamline and automate the end-to-end ML model lifecycle. MLOps is an essential aspect of the current data science workflows.
But building data pipelines to generate these features is hard, requires significant dataengineering manpower, and can add weeks or months to project delivery times,” Del Balso told TechCrunch in an email interview. Systems use features to make their predictions. This is a difficult transition for enterprises.
CloudQuery CEO and co-founder Yevgeny Pats helped launch the startup because he needed a tool to give him visibility into his cloud infrastructure resources, and he couldn’t find one on the open market. He built his own SQL-based tool to help understand exactly what resources he was using, based on dataengineering best practices.
Modern Pay-As-You-Go Data Platforms: Easy to Start, Challenging to Control It’s Easier Than Ever to Start Getting Insights into Your Data The rapid evolution of data platforms has revolutionized the way businesses interact with their data.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content