This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
Cloudera sees success in terms of two very simple outputs or results – building enterprise agility and enterprise scalability. Contrast this with the skills honed over decades for gaining access, building data warehouses, performing ETL, creating reports and/or applications using structured query language (SQL). A rare breed.
Software projects of all sizes and complexities have a common challenge: building a scalable solution for search. For this reason and others as well, many projects start using their database for everything, and over time they might move to a search engine like Elasticsearch or Solr. You might be wondering, is this a good solution?
Designed with a serverless, cost-optimized architecture, the platform provisions SageMaker endpoints dynamically, providing efficient resource utilization while maintaining scalability. Cost and Performance The solution achieves remarkable throughput by processing 100,000 documents within a 12-hour window.
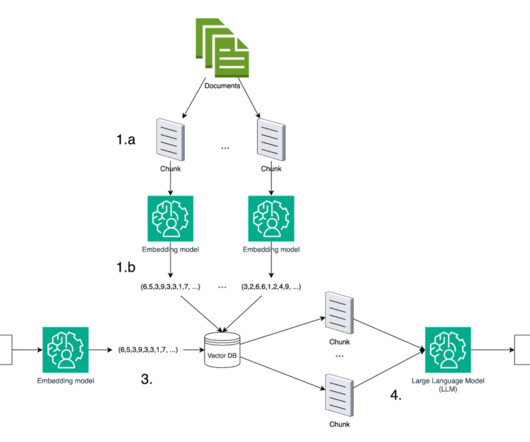
As long as the LookML file doesn’t exceed the context window of the LLM used to generate the final response, we don’t split the file into chunks and instead pass the file in its entirety to the embeddings model. The two subsets of LookML metadata provide distinct types of information about the data lake.
This will open a new window. A new window will open. A new window will open, where we can search for our Service Principal and add the permission Can Use. We will first navigate to the Data page, select the appropriate catalog (default is hive_metastore ), select the Permissions tab and click on Grant.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support AI, BI, ML, and dataengineering on a single platform.” According to Gartner, Inc.
Right now, I see a lot of companies out there using vendor consolidation as a slash and burn technique, where they simply make one top-down decision about which vendor they are going to go with, and give all engineering teams a time window in which to comply. These are, after all, data problems.
also delivers endpoint detection and response (EDR)-level protection for cloud assets, including Windows and Linux virtual machines and Kubernetes containers. Cortex XDR’s Third-Party DataEngine Now Delivers the Ability to Ingest, Normalize, Correlate, Query and Analyze Data from Virtually Any Source. With Cortex XDR 3.0
Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational. Data Accuracy: Late arriving data causes datasets processed in the past to become incomplete and as a result inaccurate.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Use cases: moving data from on-premises to cloud or between cloud environments.
This is the stage where scalability becomes a reality, adapting to growing data and user demands while continuously fortifying security measures. Moreover, it is a period of dynamic adaptation, where documentation and operational protocols will adapt as your data and technology landscape change.
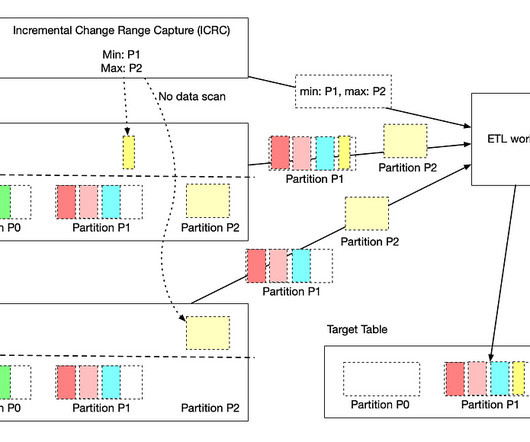
Sometimes you know that there is always a time element to the data events and to the analysis, and you know in advance the types of queries your users will run. By doing so the benefits to ingest speed, query latency, and scalability can be huge. cleansing, feature engineering, CDC reconciliation) or for stream analytics (e.g.
ETL jobs and staging of data often often require large amounts of resources. ETL is a dataengineering task and should be offloaded onto a scale-out and more cost effective solution. . Similarly, operational data stores take up resources on a data warehouse. Scalability. Data Exploration.
Apache NiFi empowers dataengineers to orchestrate data collection, distribution, and transformation of streaming data with capacities of over 1 billion events per second. . Apache Kafka helps data administrators and streaming app developers to buffer high volumes of streaming data for high scalability.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io's bestselling new 4-course learning track: Scalability and System Design for Developers. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io's bestselling new 4-course learning track: Scalability and System Design for Developers. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io's bestselling new 4-course learning track: Scalability and System Design for Developers. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Core business fails if data and compute services aren’t available fast, reliable, and scalable. Requests for IT resources for data and compute services can’t be delayed three to six months, which is how long the typical procurement cycle, machine configuration, and software installation takes. Introduction to CDW video.
Created by former senior-level AWS engineers of 15 years. Learn to balance architecture trade-offs and design scalable enterprise-level software. Check out Educative.io 's bestselling new 4-course learning track: Scalability and System Design for Developers. Learn the Good Parts of AWS. Join more than 300,000 other learners.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
OCI Data Integration. Linux or Windows. Fully Control Scalability Dynamically. Data Lakehouse based implementations. Leverage data for AI/ML Data Science/ Big Data use cases. The following should be taken care prior to beginning the implementation steps to set up Data Integration below.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Unstructured content lacks a predefined data model; it must first undergo text extraction, classification, and enrichment to provide intelligence. the client needed an approach to: Simplify data hub ingestion, especially for large volumes of unstructured content. Aspire as a Cloudera Parcel, available in the latest 3.2
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
And companies that have completed it emphasize gained advantages like accessibility, scalability, cost-effectiveness, etc. . However, back in 2008, Microsoft hadn’t even imagined the impact building the new software platform, Windows Azure, would have made on the company’s future and its services. Read the article.
As a rule, good data integration products have. easy-to-use interfaces; capabilities to examine, clean, and transform data; native connectors for different data integration use cases; scalability and elasticity to fit the changing landscape of data; and. Data profiling and cleansing. high security.
This clearly isn’t a scalable approach though, we were only able to do this because our document set is small enough (<1k tokens per document) to easily fit within the 100k token context length. Claude V2 is perfectly capable of coping with larger chunk sizes, since its context window can be as large as 100k tokens.
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional dataengineering and machine learning life cycles.
After the success with Linux, Docker partnered with Microsoft bringing containers and their functionality to Windows Server. Scalability. Containers are highly scalable and can be expanded relatively easily. Now the software is available for macOS, too. Also, containers take up less memory and reuse components thanks to images.
Decomposing a complex monolith into a complex set of microservices is a challenging task and certainly one that can’t be underestimated: developers are trading one kind of complexity for another in the hope of achieving increased flexibility and scalability long-term. Dataengineering was the dominant topic by far, growing 35% year over year.
dbt connects to a plethora of data platforms , so it’s not tied to a specific data platform. In this case, the client had already picked Snowflake as their data platform. While these modern tools offer advantages like scalability and version control, they’re ultimately just that: tools.
Databricks is a powerful Data + AI platform that enables companies to efficiently build data pipelines, perform large-scale analytics, and deploy machine learning models. Organizations turn to Databricks for its ability to unify dataengineering, data science, and business analytics, simplifying collaboration and driving innovation.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content