This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
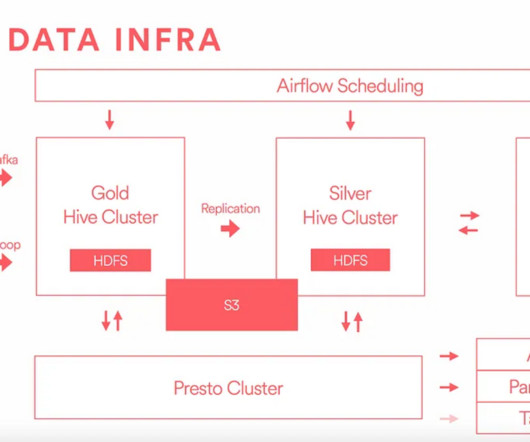
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Big data is tons of mixed, unstructured information that keeps piling up at high speed. That’s why traditional datatransportation methods can’t efficiently manage the big data flow. Big data fosters the development of new tools for transporting, storing, and analyzing vast amounts of unstructured data.
Dataengineer roles have gained significant popularity in recent years. Number of studies show that the number of dataengineering job listings has increased by 50% over the year. And data science provides us with methods to make use of this data. Who are dataengineers?
Supply chain With companies trying to stay lean with just-in-time practices, it’s important to understand real-time market conditions, delays in transportation, and raw supply delays, and adjust for them as the conditions are unfolding. It’s also used to deploy machine learning models, data streaming platforms, and databases.
Besides surgery, the hospital is also investing in robotics for the transportation and delivery of medications. Massive robots are being used in pharmacies to automate processes such as pulling pills, ointments, and creams, putting them into packs, sealing them, and transporting them to floors, he says.
Technologies that have expanded Big Data possibilities even further are cloud computing and graph databases. The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer?
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way.
Its weather-related services can be as simple as helping utilities predict short-term demand for energy, or as complex as advising maritime transporters on routing ocean-going cargo ships around developing storms. I am a firm believer in in-house resources.
They also launched a plan to train over a million data scientists and dataengineers on Spark. As data and analytics are embedded into the fabric of business and society –from popular apps to the Internet of Things (IoT) –Spark brings essential advances to large-scale data processing.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
This includes Apache Hadoop , an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable.
Supply chain practitioners and CEOs surveyed by 6river share that the main challenges of the industry are: keeping up with the rapidly changing customer demand, dealing with delays and disruptions, inefficient planning, lack of automation, rising costs (of transportation, labor, etc.), Analytics in logistics and transportation.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Use cases: moving data from on-premises to cloud or between cloud environments.
The DAG Model and the Misconception Data pipelines are commonly implemented as Directed Acyclic Graphs (DAGs), where data flows through a series of processing steps, with each step represented as a node and the dependencies between steps represented as edges. Let's take Uber as an example.
As a megacity Istanbul has turned to smart technologies to answer the challenges of urbanization, with more efficient delivery of city services and increasing the quality and accessibility of such services as transportation, energy, healthcare, and social services. This improved lead time from 2 days to less than 10 minutes.
The Innovation Centre suggests several working space alternatives for startups depending on their needs and scalability. MODEX 2020 will cover a broader spectrum of transportation, logistics, supply management, and fulfillment. CAPRE’s Annual Greater Atlanta Data Center and Cloud Infrastructure Summit 2020. Access and Pricing.
It’s represented in terms of batch reporting, near real-time/real-time processing, and data streaming. The best-case scenario is when the speed with which the data is produced meets the speed with which it is processed. Let’s take the transportation industry for example. Apache Kafka.
As a result, it became possible to provide real-time analytics by processing streamed data. Please note: this topic requires some general understanding of analytics and dataengineering, so we suggest you read the following articles if you’re new to the topic: Dataengineering overview.
The company offers a wide range of AI Development services, such as Generative AI services, Custom LLM development , AI App Development , DataEngineering , GPT Integration , and more. Over the last 15+ years, the company has worked with small to big businesses and startups worldwide and delivered scalable and reliable solutions.
Data integration and interoperability: consolidating data into a single view. Specialist responsible for the area: data architect, dataengineer, ETL developer. Extract, Transform, Load, or ETL process batches information and moves it from source systems to a data warehouse. Ensure data accessibility.
If we speak about end-to-end visibility, we mean that we should be able to have a granular view of all the main components of a supply chain: transportation – which entails control over the actual delivery process, tracking shipments , predicting ETA , etc.; to develop all the data architecture and analytics solutions.
During shipment, goods are carried using different types of transport: trucks, cranes, forklifts, trains, ships, etc. What’s more, the goods come in different sizes and shapes and have different transportation requirements. Then came standardized intermodal containers that revolutionized the transportation industry. Scalability.
In recent years, cloud-based data warehouses have revolutionized data processing with their advanced massively parallel processing (MPP) capabilities and SQL support. This development has paved the way for a suite of cloud-native data tools that are user-friendly, scalable, and affordable. What is a modern data stack?
With a high-level focus on scalability, security, and performance, G42 is transforming the AI space in the UAE. is one of the most popular AI companies in Dubai, and it emphasizes data-driven and cognitive AI solutions. Best For: National-scale enterprise AI solutions and generative AI innovation.
In addition to AI consulting, the company has expertise in delivering a wide range of AI development services , such as Generative AI services, Custom LLM development , AI App Development, DataEngineering, RAG As A Service , GPT Integration, and more. Founded: 2007 Location: India Employees: 250+ 10.
Data ingestion means taking data from several sources and moving it to a target system without any transformation. So it can be a part of data integration or a separate process aiming at transporting information in its initial form. For this task, you need a dedicated specialist — a dataengineer or ETL developer.
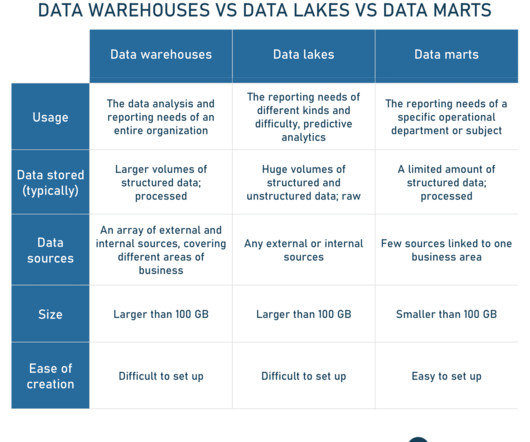
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for raw data; a tool for large-scale data integration ; and. a suitable technology to implement data lake architecture.
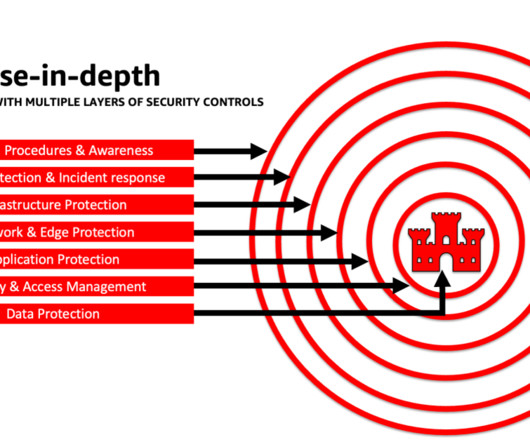
Conversely, the data in your model may be extremely sensitive and highly regulated, so deviation from AWS Key Management Service (AWS KMS) customer managed key (CMK) rotation and use of AWS Network Firewall to help enforce Transport Layer Security (TLS) for ingress and egress traffic to protect against data exfiltration may be an unacceptable risk.
AI and edge, hand in hand As edge computing is all about real-time data processing at the end-point where data is gathered and needs to be processed, AI becomes a clear ally, says Antonio Vázquez, CIO of software company Bizagi. “AI Operational gains make it worth considering as well. “AI
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and dataengineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG data integrity and fostering collaboration with sustainability teams.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content