This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
Its a common skill for cloud engineers, DevOps engineers, solutions architects, dataengineers, cybersecurity analysts, software developers, network administrators, and many more IT roles. Job listings: 90,550 Year-over-year increase: 7% Total resumes: 32,773,163 3. As such, Oracle skills are perennially in-demand skill.
The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both. Imagine that you’re a dataengineer. The data is spread out across your different storage systems, and you don’t know what is where. Through relentless innovation.
“The fine art of dataengineering lies in maintaining the balance between data availability and system performance.” Even more perplexing: DuckDB , a lightweight single-node engine, outpaced Databricks on smaller subsets. Semi-Structured Storage : Measurement values have varying types (e.g.,
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
I know this because I used to be a dataengineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models.
The data preparation process should take place alongside a long-term strategy built around GenAI use cases, such as content creation, digital assistants, and code generation. Known as dataengineering, this involves setting up a data lake or lakehouse, with their data integrated with GenAI models.
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. Inferencing funneled through RAG must be efficient, scalable, and optimized to make GenAI applications useful. Inferencing and… Sherlock Holmes???
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever.
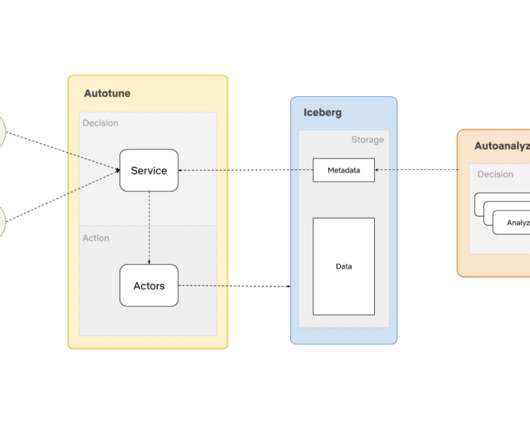
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. Ensuring compliant data deletion is a critical challenge for dataengineering teams, especially in industries like healthcare, finance, and government. This could provide both cost savings and performance improvements.
The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machine learning models and addition of new features. All AWS services are high-performing, secure, scalable, and purpose-built.
Platform engineering: purpose and popularity Platform engineering teams are responsible for creating and running self-service platforms for internal software developers to use. AI is 100% disrupting platform engineering,” Srivastava says, so it’s important to have the skills in place to exploit that. “As
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. It’s also used to deploy machine learning models, data streaming platforms, and databases. The features can be raw data that has been processed or analyzed or derived.
Technologies that have expanded Big Data possibilities even further are cloud computing and graph databases. The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer?
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so?
On-prem infrastructure will grow cold — with the exception of storage, Nardecchia says. Some storage will likely stay on-prem while more is pushed into the public cloud, he says. Fleschut says he will also hire more IT personnel this year, especially data scientists, architects, and security and risk professionals.
The forecasting systems DTN had acquired were developed by different companies, on different technology stacks, with different storage, alerting systems, and visualization layers. Working with his new colleagues, he quickly identified rebuilding those five systems around a single forecast engine as a top priority.
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way.
Start with storage. Before you can even think about analyzing exabytes worth of data, ensure you have the infrastructure to store more than 1000 petabytes! Going from 250 PB to even a single exabyte means multiplying storage capabilities four times. Focus on scalability. So, how do we achieve scalability?
Amazon Bedrocks broad choice of FMs from leading AI companies, along with its scalability and security features, made it an ideal solution for MaestroQA. The customer interaction transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket. The following architecture diagram demonstrates the request flow for AskAI.
In the finance industry, software engineers are often tasked with assisting in the technical front-end strategy, writing code, contributing to open-source projects, and helping the company deliver customer-facing services. Dataengineer.
In the finance industry, software engineers are often tasked with assisting in the technical front-end strategy, writing code, contributing to open-source projects, and helping the company deliver customer-facing services. Dataengineer.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Supports Disaggregation of compute and storage.
Data intake A user uploads photos into Mixbook. The raw photos are stored in Amazon Simple Storage Service (Amazon S3). The data intake process involves three macro components: Amazon Aurora MySQL-Compatible Edition , Amazon S3, and AWS Fargate for Amazon ECS. DJ Charles is the CTO at Mixbook.
Data Modelers: They design and create conceptual, logical, and physical data models that organize and structure data for best performance, scalability, and ease of access. In the 1990s, data modeling was a specialized role. Data Users: These are analysts and BI developers who use data within the organization.
Cloudera Private Cloud Data Services is a comprehensive platform that empowers organizations to deliver trusted enterprise data at scale in order to deliver fast, actionable insights and trusted AI. This means you can expect simpler data management and drastically improved productivity for your business users.
This post was co-written with Vishal Singh, DataEngineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
In this blog post, we want to tell you about our recent effort to do metadata-driven data masking in a way that is scalable, consistent and reproducible. Using dbt to define and document data classifications and Databricks to enforce dynamic masking, we ensure that access is controlled automatically based on metadata.
This includes Apache Hadoop , an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable.
The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for data ingestion. The objective is to automate data integration from various sensor manufacturers for Accra, Ghana, paving the way for scalability across West Africa.
Please join us on March 24 for Future of Data meetup where we do a deep dive into Iceberg with CDP . Apache Iceberg is a high-performance, open table format, born-in-the cloud that scales to petabytes independent of the underlying storage layer and the access engine layer. What is Apache Iceberg? 1: Multi-function analytics .
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a dataengineer? By the way, we have a video dedicated to the dataengineering working principles.
This table can be massively scaled to any use-case and this is why HBase is superior in this application as it’s a distributed, scalable, big data store. In order to use this data, I built a very simple demo using the popular Flask framework for building web applications. Serving The Model . GitHub Repo Link.
In the first article in this series, I explained the five components necessary to prevent a Data Lake from Becoming a Data Swamp. Data lakes work on the concept of load first and use later, which means the data stored in the repository doesn’t necessarily have to be used immediately for a specific purpose.
At its core, CDP Private Cloud Data Services (“the platform”) is an end-to-end cloud native platform that provides a private open data lakehouse. It offers features such as data ingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content