This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both. Imagine that you’re a dataengineer. The data is spread out across your different storage systems, and you don’t know what is where. Through relentless innovation.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
The ease of access, while empowering, can lead to usage patterns that inadvertently inflate costsespecially when organizations lack a clear strategy for tracking and managing resource consumption. They provide unparalleled flexibility, allowing organizations to scale resources up or down based on real-time demands.
The ease of access, while empowering, can lead to usage patterns that inadvertently inflate costsespecially when organizations lack a clear strategy for tracking and managing resource consumption. They provide unparalleled flexibility, allowing organizations to scale resources up or down based on real-time demands.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
To that end, we’re collaborating with Amazon Web Services (AWS) to deliver a high-performance, energy-efficient, and cost-effective solution by supporting many data services on AWS Graviton. The net result is that queries are more efficient and run for shorter durations, while storage costs and energy consumption are reduced.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. It’s no longer driven by data volumes, but containerization, separation of storage and compute, and democratization of analytics.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage. Test Drive CDP Pubic Cloud.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
I know this because I used to be a dataengineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models.
Yet, it is the quality of the data that will determine how efficient and valuable GenAI initiatives will be for organizations. For these data to be utilized effectively, the right mix of skills, budget, and resources is necessary to derive the best outcomes.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever. Normally on-premises, one of the key challenges was how to allocate resources within a finite set of resources (i.e., fixed sized clusters).
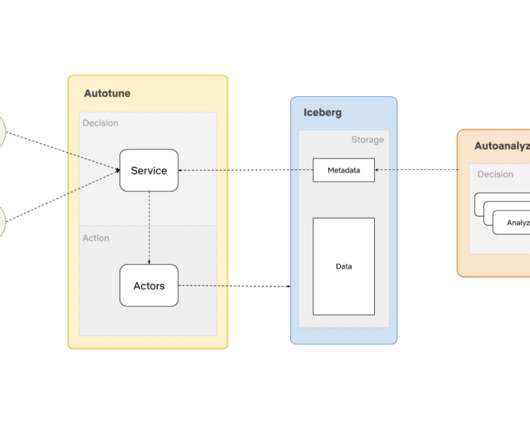
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Decades ago, software engineering was hard because you had to build everything from scratch and solve all these foundational problems. You need storage to build something to serve 1M concurrent users? Factories in the age of steam engines were built around power distribution from the almighty steam engines.
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. Data-obsessed individuals such as Sherlock Holmes knew full well the importance of inferencing in making predictions, or in his case, solving mysteries.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
Introduction: We often end up creating a problem while working on data. So, here are few best practices for dataengineering using snowflake: 1.Transform So, resist the temptation to periodically load data using other methods (such as querying external tables). Use it, but don’t use it for normal large data loads.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloud storage (S3 for AWS, ADLS-gen2 for Azure).
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A REST API is built directly into our VSP storage controllers.
That will include more remediation once problems are identified: that is, in addition to identifying issues, engineers will be able to start automatically fixing them, too. And as data workloads continue to grow in size and use, they continue to become ever more complex. Doing so manually can be time-consuming, if not impossible.
But implementing and maintaining the data pipelines necessary to keep AI systems from drifting to inaccuracy can require substantial technical resources. That’s where Flyte comes in — a platform for programming and processing concurrent AI and data analytics workflows.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
These network, security, and cloud changes allow us to shift resources and spend less on-prem and more in the cloud.” On-prem infrastructure will grow cold — with the exception of storage, Nardecchia says. Some storage will likely stay on-prem while more is pushed into the public cloud, he says.
The forecasting systems DTN had acquired were developed by different companies, on different technology stacks, with different storage, alerting systems, and visualization layers. Working with his new colleagues, he quickly identified rebuilding those five systems around a single forecast engine as a top priority.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
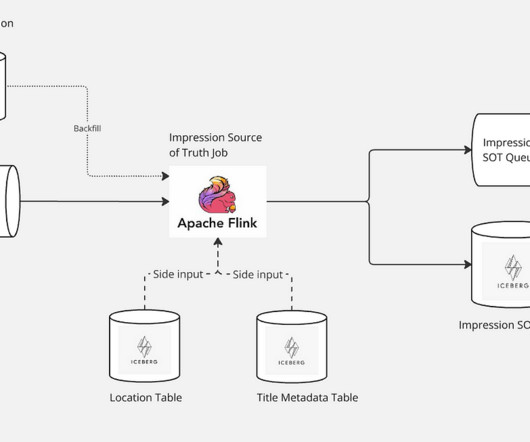
This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Everybody needs more data and more analytics, with so many different and sometimes often conflicting needs. Dataengineers need batch resources, while data scientists need to quickly onboard ephemeral users. Meanwhile, some workloads hog resources making others miss defined agreements.
I list a few examples from the media industry, but there are are numerous new startups that collect aerial imagery, weather data, in-game sports data , and logistics data, among other things. If you are an aspiring entrepreneur, note that you can build interesting and highly valued companies by focusing on data.
The customer interaction transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket. This shift enabled MaestroQA to channel their efforts into optimizing application performance rather than grappling with resource allocation. The following architecture diagram demonstrates the request flow for AskAI.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so?
Platform engineering teams work closely with both IT and business teams, fostering collaboration within the organization,” he says. AI is 100% disrupting platform engineering,” Srivastava says, so it’s important to have the skills in place to exploit that. “As
The first data source connected was an Amazon Simple Storage Service (Amazon S3) bucket, where a 100-page RFP manual was uploaded for natural language querying by users. The data source allowed accurate results to be returned based on indexed content. Joel Elscott is a Senior DataEngineer on the Principal AI Enablement team.
Few if any data management frameworks are business focused, to not only promote efficient use of data and allocation of resources, but also to curate the data to understand the meaning of the data as well as the technologies that are applied to the data so that dataengineers can move and transform the essential data that data consumers need.
First, it doesn’t fully (or, in most instances, at all) leverage the elastic capabilities of the cloud deployment model, i.e., the ability to scale up and down compute resources . that optimizes autoscaling for compute resources compared to the efficiency of VM-based scaling. . Storage costs. using list pricing of $0.72/hour
ADF is a Microsoft Azure tool widely utilized for data ingestion and orchestration tasks. A typical scenario for ADF involves retrieving data from a database and storing it as files in an online blob storage, which applications can utilize downstream. An Azure Key Vault is created to store any secrets.
When our dataengineering team was enlisted to work on Tenable One, we knew we needed a strong partner. When Tenable’s product engineering team came to us in dataengineering asking how we could build a data platform to power the product, we knew we had an incredible opportunity to modernize our data stack.
On-premises, traditional data and analytics clusters are monolithic deployments of tight coupled compute and storage, unable to cope with current business demands of fast and agile use case deployment with services that are statically provisioned to physical infrastructure. Move to more Data Services. Take the first step.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Supports Disaggregation of compute and storage.
An overview of data warehouse types. Optionally, you may study some basic terminology on dataengineering or watch our short video on the topic: What is dataengineering. What is data pipeline. This could be a transactional database or any other storage we take data from.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content