This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I had my first job as a softwareengineer in 1999, and in the last two decades I've seen softwareengineering changing in ways that have made us orders of magnitude more productive. Because someone made the economic decision that the cost of building that software was too high. Supply-demand of softwareengineers.
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
Both softwareengineers and computer scientists are concerned with computer programs and software improvement and various related fields. What is SoftwareEngineering? Software is more than just program code. The final result of softwareengineering is an effective and reliable software program.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
The team noted at the time that the current process for interviewing softwareengineers didn’t really work for measuring how well someone would do in a day-to-day engineering job. A group of experienced engineers review and rate the interviews.
The idea behind using synthetic data sets is that it lets an organization remove the risk of data leaking that might contain personal information or other kinds of sensitive data. “But now we are running into the bottleneck of the data. . The germination for Gretel.ai military and over the years. ”
“Typically, most companies are bottlenecked by data science resources, meaning product and analyst teams are blocked by a scarce and expensive resource. With Predibase, we’ve seen engineers and analysts build and operationalize models directly.” tech company, a large national bank and large U.S.
Now, three alums that worked with data in the world of Big Tech have founded a startup that aims to build a “metrics store” so that the rest of the enterprise world — much of which lacks the resources to build tools like this from scratch — can easily use metrics to figure things out like this, too.
In a recent MuleSoft survey , 84% of organizations said that data and app integration challenges were hindering their digital transformations and, by extension, their adoption of cloud platforms. “Moreover, many of the tools need experienced dataengineers and a lot of time in order for companies to get the right value from the tool.
The demand for specialized skills has boosted salaries in cybersecurity, data, engineering, development, and program management. The CIO typically ranks the highest in an IT department, responsible for managing the organization’s IT strategy, resources, operations, and overall goals. increase from 2021.
But implementing and maintaining the data pipelines necessary to keep AI systems from drifting to inaccuracy can require substantial technical resources. That’s where Flyte comes in — a platform for programming and processing concurrent AI and data analytics workflows.
Digital solutions and data analytics are changing the world of sports entertainment at a rapid clip. From how players train, to how teams make strategic decisions during games, to how venues operate and fans engage, sports organizations are turning to softwareengineers and data scientists to help transform the sport experience.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
I'm extremely determined that I want to start my own thing (meaning, don't try to hire me, it's probably a waste of time), and it's highly likely it will be something in the dataengineering/science tools/infra space. I've spent most of my career working in data in some shape or form. At Spotify, I was entirely focused on it.
Fast-forward five years and Merola is now a senior softwareengineer, writing code, promoting agile practices, and working with business partners to advance The Hartford’s digital agenda. “The MSC is also looking at the veteran community as an under-tapped resource. John Hill, SVP and CDIO, MSC Industrial Supply Co.
A Brave New (Generative) World – The future of generative softwareengineering Keith Glendon 26 Mar 2024 Facebook Twitter Linkedin Disclaimer : This blog article explores potential futures in softwareengineering based on current advancements in generative AI.
Key survey results: The C-suite is engaged with data quality. Data scientists and analysts, dataengineers, and the people who manage them comprise 40% of the audience; developers and their managers, about 22%. Data quality might get worse before it gets better. Can AI be a catalyst for improved data quality?
And, in fact, McKinsey research argues the future could indeed be dazzling, with gen AI improving productivity in customer support by up to 40%, in softwareengineering by 20% to 30%, and in marketing by 10%. Hardly a day goes by without some new business-busting development on generative AI surfacing in the media.
Why this works: Before using the automated screening method, the company relied on manual screening of applications which was a time-consuming process and led the company to exhaust its resources. emphasizes the gender diversity of softwareengineers where women represent only 21% of the workforce in softwareengineering.
Current challenges Afri-SET currently merges data from numerous sources, employing a bespoke approach for each of the sensor manufacturers. This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration.
Everything concerning your business past and recent state is recorded as bits of data. Marketing numbers, human resources, company budgeting, sales volumes — you name it. The number of business domains the data comes from can be large. Thanks to Earth there is a software for everything. Softwareengineering skills.
Seamless integration with SageMaker – As a built-in feature of the SageMaker platform, the EMR Serverless integration provides a unified and intuitive experience for data scientists and engineers. This flexibility helps optimize performance and minimize the risk of bottlenecks or resource constraints.
dbt is a data transformation tool that allows data folks to combine modular SQL with softwareengineering best practices to make data transformations that are reliable, iterative, and fast. Why is dbt useful in dataengineering and analysis? What is dbt?
In recent years, it’s getting more common to see organizations looking for a mysterious analytics engineer. As you may guess from the name, this role sits somewhere in the middle of a data analyst and dataengineer, but it’s really neither one nor the other. Here’s the video explaining how dataengineers work.
That said, similar resources sometimes can’t be quite comparable for having additional or lacking features, which may influence (not to say compromise) design and entail vendor lock-in. As a result, we must work around these limitations in the code and use cloud resources only to some extent.
Analytics maturity model is a sequence of steps or stages that represent the evolution of the company in its ability to manage its internal and external data and use this data to inform business decisions. These models assess and describe how effectively companies use their resources to get value out of data.
Tech Conferences Compass Tech Summit – October 5-6 Compass Tech Summit is a remarkable 5-in-1 tech conference, encompassing topics such as engineering leadership, AI, product management, UX, and dataengineering that will take place on October 5-6 at the Hungarian Railway Museum in Budapest, Hungary.
The diverse group included softwareengineers, data analysts, dataengineers, a business analyst with a background in marketing, and even a data scientist who, in his spare time, is coding his own space-themed resource management game using Python.
Investigating and debugging issues was also cumbersome and lacked flexibility, impeding the engineering team’s ability to efficiently navigate and trace system problems. “Getting the insights we needed with New Relic was a growing challenge,” explained Pawel Malon, Principal SoftwareEngineer at Phorest.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
dataengineering pipelines, machine learning models). On the other hand, Cloudera has decades of deep expertise in the open source projects included in the Cloudera runtime and the necessary resources to help clients pinpoint and resolve platform issues regardless of complexity right down to the actual code level.
It entails collecting data from internal and external sources, preprocessing, storing, analyzing it to get insights about people oh whose competence and commitment an organization performance depends. Dataengineer builds interfaces and infrastructure to enable access to data. So, dataengineers make data pipelines work.
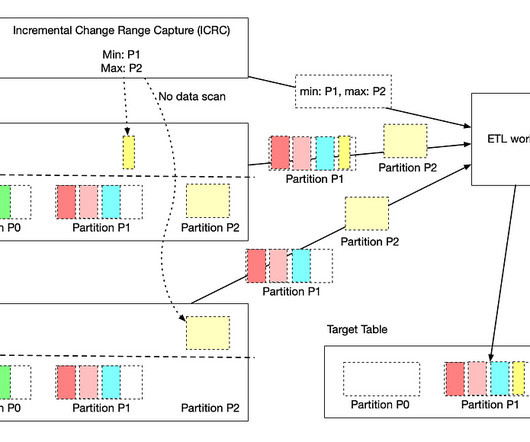
The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset. This not only reduces the cost of compute resources but also reduces the execution time in a significant manner. Users configure the workflow to read the data in a window (e.g.
Trickle data migration. Disadvantages: more expensive, takes more time, needs extra efforts and resources to keep two systems running. Also known as a phased or iterative migration, this approach brings Agile experience to data transfer. The integral part of ETL is data mapping.
This shift requires a fundamental change in your softwareengineering practice. The model outputs produced by the same code will vary with changes to things like the size of the training data (number of labeled examples), network training parameters, and training run time. How do you select what to work on?
Unlike other outsourcing models that spread resources across multiple clients, a dedicated team focuses solely on one project at a time. On the other hand, time and material model charges are based on actual time and resources spent, offering greater flexibility for adjustments as the project progresses.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
As a single platform for your entire team, AI Cloud brings together Data Scientists , analytics experts , IT and the business to collaborate, combine expertise and align resources on shared initiatives. AI Cloud brings together any type of data, from any source, giving you a unique, global view of insights that drive your business.
Education and certifications for AI engineers Higher education base. AI engineers need a strong academic foundation to deeply comprehend the main technology principles and their applications. It includes subjects like dataengineering, model optimization, and deployment in real-world conditions.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Make your job search O (1), not O ( n ). Apply here.
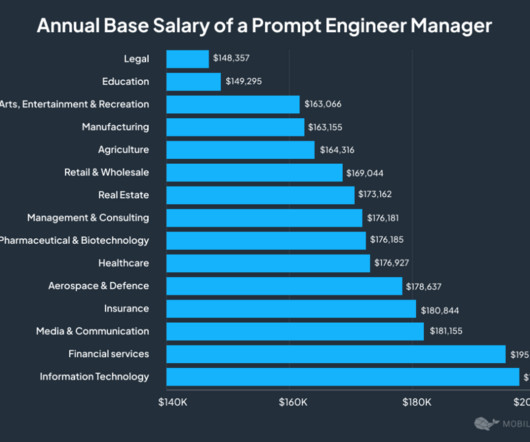
A degree in computer science, softwareengineering, or IT, certifications in AI and ML, NLP and LLM, data science and data analysis, and niche-specific certifications are valuable for a successful career in prompt engineering. Check what top tech companies offer engineers with the required expertise level.
This article will expose Apache Spark architecture, assess its advantages and disadvantages, compare it with other big data technologies, and provide you with the path to learning this impactful instrument. Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content