This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Big data architect: The big data architect designs and implements data architectures supporting the storage, processing, and analysis of large volumes of data. Data architect vs. dataengineer The data architect and dataengineer roles are closely related.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. Data-obsessed individuals such as Sherlock Holmes knew full well the importance of inferencing in making predictions, or in his case, solving mysteries.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. you want a running total of the order total price for a customer using order_date as the reference column for time). This blog post is for you.
Note: I'm going to use the term “tool” throughout this post to refer to all kinds of things: frameworks, libraries, development processes, infrastructure.). Decades ago, software engineering was hard because you had to build everything from scratch and solve all these foundational problems.
Liubimov was a senior engineer at Huawei before moving to Yandex, where he worked as a backend developer on speech technologies and dialogue systems. When asked, Heartex says that it doesn’t collect any customer data and open sources the core of its labeling platform for inspection. Heartex’s dashboard.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. The features can be raw data that has been processed or analyzed or derived. The ML workflow for creating these features is referred to as feature engineering.
csv The data has a header and is comma-separated and contains a lot of columns. The last 5 columns are URL references to different datasets. A columnar storage format like parquet or DuckDB internal format would be more efficient to store this dataset. And is a cost saver for cloud storage. __version__) # 1.1.3
Python is used extensively among DataEngineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective datastorage system for many workflows but accessing this data specifically through Python can be a struggle. builder.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so?
Informatica and Cloudera deliver a proven set of solutions for rapidly curating data into trusted information. Informatica’s comprehensive suite of DataEngineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform.
In Cloudera Operational Database, you use Apache HBase as a datastore with HDFS and/or S3 providing the storage infrastructure. You have the choice to either develop applications using one of the native Apache HBase applications, or you can use Apache Phoenix for data access. A column family is stored together in the storage. .
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a dataengineer? By the way, we have a video dedicated to the dataengineering working principles.
Cost-effective – The solution should only invoke LLM to generate reusable code on an as-needed basis instead of manipulating the data directly to be as cost-effective as possible. Automatic code generation reduces dataengineering work from months to days.
To evaluate the models accuracy and track the mechanism, we store every user input and output in Amazon Simple Storage Service (Amazon S3). To clean up your S3 bucket, refer to Emptying a bucket. The user input is combined with relevant table metadata and the prompt template, which is passed to the FM as a single input all together.
Please join us on March 24 for Future of Data meetup where we do a deep dive into Iceberg with CDP . Apache Iceberg is a high-performance, open table format, born-in-the cloud that scales to petabytes independent of the underlying storage layer and the access engine layer. What is Apache Iceberg? 1: Multi-function analytics .
Many customers looking at modernizing their pipeline orchestration have turned to Apache Airflow, a flexible and scalable workflow manager for dataengineers. A provider could be used to make HTTP requests, connect to a RDBMS, check file systems (such as S3 object storage), invoke cloud provider services, and much more.
It means you must collect transactional data and move it from the database that supports transactions to another system that can handle large volumes of data. And, as is common, to transform it before loading to another storage system. But how do you move data? The simplest illustration for a data pipeline.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. Virtually, Hadoop puts no limits on the storage capacity. What is Hadoop.
Now if you want to run and mimic this Demo Application in CDSW, here’s how: Make sure PySpark and HBase are configured – For reference look at Part 1. This application demonstrates how PySpark is leveraged in order to build a simple ML Classification model using HBase as an underlying storage system. Run preprocessing.py
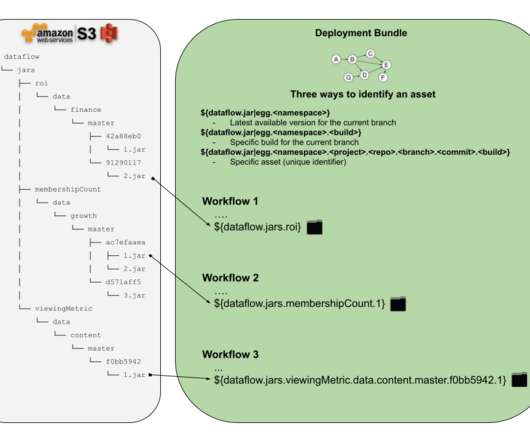
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. This causes the user-managed storage system to be a critical runtime dependency. 39206ee8.3 -> dataflow.egg.hello_world.user.stranger-data.master.39206ee8.2
Impala) and storage (i.e. This also enables advanced scenarios where customers can connect multiple CDW Virtual Clusters to different real-time data mart clusters to connect to a Kudu cluster specific for their workloads. What’s Next For complete setup guide refer to CDW documentation on this topic.
A data source connector is a component of Amazon Q that helps integrate and synchronize data from multiple repositories into one index. For a full list of Amazon Q business supported data source connectors, see Amazon Q Business connectors. Refer to How Amazon Q Business connector crawls ServiceNow ACLs for more information.
With tools like KSQL and Kafka Connect, the concept of streaming ETL is made accessible to a much wider audience of developers and dataengineers. My source of data is a public feed provided by the UK’s Network Rail company through an ActiveMQ interface. There’s also some static referencedata that is published on web pages. ?After
In addition, data pipelines include more and more stages, thus making it difficult for dataengineers to compile, manage, and troubleshoot those analytical workloads. CRM platforms). Limited flexibility to use more complex hosting models (e.g., benchmarking study conducted by independent 3rd party ).
Ozone supports dense node configurations of 350TB which increases the current usable storage capacity by 350% compared to HDFS and reduces storage cost by 50%. DataEngineering . Hive Warehouse Connector (HWC) makes dataengineering simpler and faster. Data Warehouse. Release Notes.
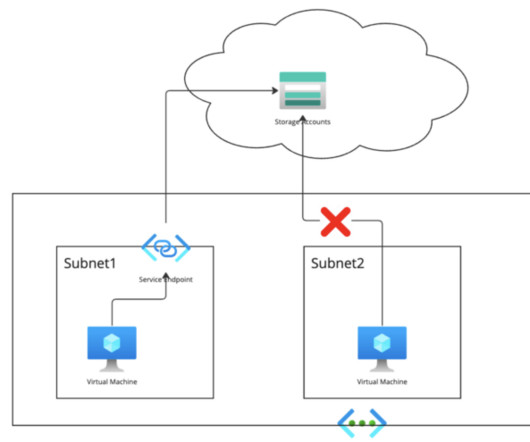
Please refer to the Microsoft documentation for detail. In a Cloudera deployment scenario, only storage accounts, PostgreSQL DB, and Key Vault support service endpoints. For example: Storage account private endpoint—the public DNS zone stores the public IP address of that service.
These runtime roles provide the necessary permissions for your workloads to access AWS resources, such as Amazon Simple Storage Service (Amazon S3) buckets. If you don’t have a SageMaker Studio domain available, refer to Quick setup to Amazon SageMaker to provision one. Install Docker in your JupyterLab environment. python3.11-pip
While this “data tsunami” may pose a new set of challenges, it also opens up opportunities for a wide variety of high value business intelligence (BI) and other analytics use cases that most companies are eager to deploy. . Traditional data warehouse vendors may have maturity in datastorage, modeling, and high-performance analysis.
So, the path that companies cover in their analytical development can be broken down into 5 stages: No analytics refers to companies with no analytical processes whatsoever. Descriptive analytics lets us know what happened , gathering, and visualizing historical data. Introducing dataengineering and data science expertise.
Traditionally, organizations used to provision multiple services of Azure Services, like Azure Storage, Azure Databricks, etc. It is crucial that in Premium tab of settings, one needs to choose Fabric capacity (or Trial), which offers Lakehouse (refer below screenshot). Once created, it should look as below (refer below screenshot).
It builds on top of existing file systems like Amazon S3, Azure Blob Storage, and Hadoop HDFS, providing a layer of abstraction and additional functionalities for Spark applications. DBFS provides a unified interface to access data stored in various underlying storage systems. How does DBFS work?
This solution uses Amazon Bedrock, Amazon Relational Database Service (Amazon RDS), Amazon DynamoDB , and Amazon Simple Storage Service (Amazon S3). The workflow consists of the following steps: An end-user (data analyst) asks a question in natural language about the data that resides within a data lake.
Not only does Big Data apply to the huge volumes of continuously growing data that come in different formats, but it also refers to the range of processes, tools, and approaches used to gain insights from that data. Key Big Data characteristics. What is Big Data analytics? Datastorage and processing.
ETL refers to extract, transform, load and it is generally used for data warehousing and data integration. There are several emerging data trends that will define the future of ETL in 2018. Common in-memory data interfaces. It generally improves performance by placing frequently accessed data in memory.
Hybrid clouds must bond together the two clouds through fundamental technology, which will enable the transfer of data and applications. The term “hyperscale” is used by Gartner to refer to Amazon Web Services, Microsoft Azure, and Google Cloud Platform.
In most digital spheres, especially in fintech, where all business processes are tied to data processing, a good big dataengineer is worth their weight in gold. In this article, we’ll discuss the role of an ETL engineer in data processing and why businesses need such experts nowadays. Who Is an ETL Engineer?
Moreover, it is a period of dynamic adaptation, where documentation and operational protocols will adapt as your data and technology landscape change. Configuration: set up initial configurations, including cluster settings, user access, and datastorage configurations. How does Cloudera support Day 2 operations?
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content