This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To succeed in todays landscape, every company small, mid-sized or large must embrace a data-centric mindset. This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs.
After the launch of CDP DataEngineering (CDE) on AWS a few months ago, we are thrilled to announce that CDE, the only cloud-native service purpose built for enterprise dataengineers, is now available on Microsoft Azure. . Prerequisites for deploying CDP DataEngineering on Azure can be found here.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
A significant share of organizations say to effectively develop and implement AIOps, they need additional skills, including: 45% AI development 44% security management 42% dataengineering 42% AI model training 41% data science AI and data science skills are extremely valuable today.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
The new team needs dataengineers and scientists, and will look outside the company to hire them. Instead of looking for objective ways to find the best applicant out of 250 that have very similar profiles, IT leaders are favoring applicants who are referred by colleagues or partners,” says Gobrail.
Big data architect: The big data architect designs and implements data architectures supporting the storage, processing, and analysis of large volumes of data. Data architect vs. dataengineer The data architect and dataengineer roles are closely related.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
What is Cloudera DataEngineering (CDE) ? Cloudera DataEngineering is a serverless service for Cloudera Data Platform (CDP) that allows you to submit jobs to auto-scaling virtual clusters. Refer to the following cloudera blog to understand the full potential of Cloudera DataEngineering. .
The development- and operations world differ in various aspects: Development ML teams are focused on innovation and speed Dev ML teams have roles like Data Scientists, DataEngineers, Business owners. Graph refers to Gartner hype cycle. Dev ML teams work agile and experiment rapidly using PoC’s.
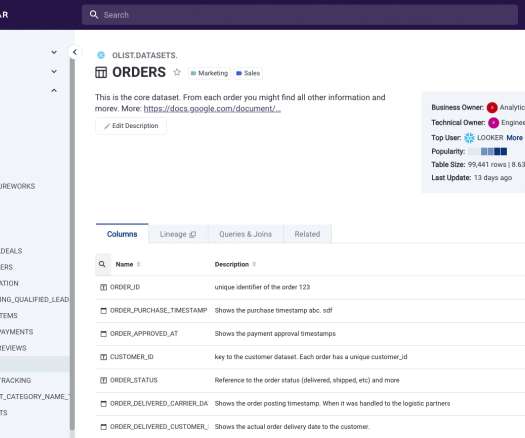
From there, it offers a full-text search that allows users to quickly find data as well as “heat map” signals in its search results which can quickly pinpoint which columns of a dataset are most used by applications within a company and have the most queries that reference them. Photo via Select Star.
It covers essential topics like artificial intelligence, our use of data models, our approach to technical debt, and the modernization of legacy systems. We explore the essence of data and the intricacies of dataengineering. I think we’re very much on our way.
In a conversation with TechCrunch, Playford references building personalized user fintech experiences to what Alipay and WeChat have done in the past couple of years. “It’s a highly data-driven user experience. And every fintech or bank wants to provide that same data-driven user experience.
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. you want a running total of the order total price for a customer using order_date as the reference column for time). This blog post is for you.
DataengineersDataengineers can supercharge their careers by becoming conversant in genAI systems. For instance, most dataengineers may be familiar with working with diverse data sources, but companies require specialists who can collect, preprocess and manage the large datasets required for training models.
This is sometimes referred to as a “ dbt Mesh ”, borrowing from the term Data Mesh. Our analytics engineer consultants are here to help – just contact us and we’ll get back to you soon. Or are you an analyst, analytics engineer or dataengineer interested in learning more about dbt?
For example, Napoli needs conventional data wrangling, dataengineering, and data governance skills, as well as IT pros versed in newer tools and techniques such as vector databases, large language models (LLMs), and prompt engineering.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
Cloudera DataEngineering (CDE) is a cloud-native service purpose-built for enterprise dataengineering teams. CDE provides flexible options for fully operationalizing your dataengineering pipelines and is fully integrated with Shared Data Experience for comprehensive security and governance.
Refer to Steps 1 and 2 in Configuring Amazon VPC support for Amazon Q Business connectors to configure your VPC so that you have a private subnet to host an Aurora MySQL database along with a security group for your database. For instructions, refer to Access an AWS service using an interface VPC endpoint. DataEngineer at Amazon Ads.
Give each secret a clear name, as youll use these names to reference them in Synapse. Add a Linked Service to the pipeline that references the Key Vault. When setting up a linked service for these sources, reference the names of the secrets stored in Key Vault instead of hard-coding the credentials.
Note: I'm going to use the term “tool” throughout this post to refer to all kinds of things: frameworks, libraries, development processes, infrastructure.). But the fact that non-engineers are building technology validates that there's demand for engineers. The insatiable demand for software.
All of the observability companies founded post-2020 have been built using a very different approach: a single consolidated storage engine, backed by a columnar store. In the past, I have referred to these models as observability 1.0 But companies built using the multiple pillars model have bristled at being referred to as 1.0
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. Data-obsessed individuals such as Sherlock Holmes knew full well the importance of inferencing in making predictions, or in his case, solving mysteries.
Petrossian met Coalesce’s other co-founder, Satish Jayanthi, at WhereScape, where the two were responsible for solving data warehouse problems for large organizations. (In In computing, a “data warehouse” refers to systems used for reporting and data analysis — analysis usually germane to business intelligence.)
Molino describes it as a “declarative” approach to AI development, borrowing a term from computer science that refers to code written to describe what a developer wishes to accomplish. and low-code dataengineering platform Prophecy (not to mention SageMaker and Vertex AI ). healthcare company.”
The information provided was all pulled from data he’s already entered - just Mark, Houston, Math Teacher, Teach for America. Maybe those references to TFA sound like bragging, or he thinks “passion for numbers” sounds silly. And if this description doesn’t resonate with Mark, he can ask for a new one, while providing feedback.
“With the Design Hub, Avnet enables engineers to design, get a bill of materials, check prices and availability, compile a quote, and make a purchase all in a single, frictionless workflow.” Product design made easy The Design Hub offers thousands of proven reference designs, technical calculators and tools. Robinson agrees.
Liubimov was a senior engineer at Huawei before moving to Yandex, where he worked as a backend developer on speech technologies and dialogue systems. For example, dataengineers using Heartex can see the names and email addresses of annotators and data reviewers, which are tied to labels that they’ve contributed or audited.
V7 — named in reference to AI being the “seventh” area for processing images after the six areas in the human brain that form its visual cortex (V1 through V6) — and the others are banking on the fact that the training model is inefficient and can be improved. “This is where V7’s AI DataEngine shines.
When we interviewed him last July , Hughes explained that he would refer leads to EveryDeveloper when they needed to sort out their content strategy. If your customers are dataengineers, it probably won’t make sense to discuss front-end web technologies. Hughes was therefore happy to recommend DuVander via our experts survey.
The features can be raw data that has been processed or analyzed or derived. The ML workflow for creating these features is referred to as feature engineering. The storage for these features is referred to as a feature store. Data and ML model development fundamentally depend on one another.
Airbus was conceiving an ambitious plan to develop an open aviation data platform, Skywise, as a single platform of reference for all major aviation players that would enable them to improve their operational performance and business results and support Airbus’ own digital transformation.
Python is used extensively among DataEngineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle. Introduction.
References: What is Intelligent Document Processing (IDP)? Serverless on AWS AWS GovCloud (US) Generative AI on AWS About the Authors Nick Biso is a Machine Learning Engineer at AWS Professional Services. Ian Thompson is a DataEngineer at Enterprise Knowledge, specializing in graph application development and data catalog solutions.
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
However, in the typical enterprise, only a small team has the core skills needed to gain access and create value from streams of data. This dataengineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. A rare breed. What do you mean by democratizing?
These are the four reasons one would adopt a feature store: Prevent repeated feature development work Fetch features that are not provided through customer input Prevent repeated computations Solve train-serve skew These are the issues addressed by what we will refer to as the Offline and Online Feature Store.
It provides a suite of tools for dataengineering, data science, business intelligence, and analytics. Once the notebook is created, the next step is to attach the newly created lakehouse, which we’ll refer to as jsl_workspace , to your notebook. For detailed instructions, refer to our documentation.
Data freshness, sometimes referred to as data timeliness, is the frequency with which data is updated for consumption. It is an important dimension of data quality because recently refreshed data is more accurate and, thus, more valuable.
To clean up your S3 bucket, refer to Emptying a bucket. With the aid of a tool like this, you can create automated solutions that are accessible to nontechnical users, empowering them to interact with data more efficiently. Solution Verify your bucket name in the app.py file and update the name based on your S3 bucket name.
To save ourselves from answering the same thing five times a day, here’s a handy blog series that answers these questions thoroughly and to which we can start referring to instead. Are you part of an organisation looking into implementing best practices around data modeling? Oh, sweet summer child.
Machine learning : This is the art of classifying or grouping data for prediction. An ideal data scientist should be able to use big data technologies to create pipelines that feed machine learning algorithms. Data mining : This refers to handling and cleaning data.
Refer to ServiceNow data source connector field mappings documentation for more information. Refer to How Amazon Q Business connector crawls ServiceNow ACLs for more information. If a user doesn’t have permission to access data without Amazon Q, they can’t access it using Amazon Q either. Choose Create application.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content