This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. Operational errors because of manual management of data platforms can be extremely costly in the long run.
Many still rely on legacy platforms , such as on-premises warehouses or siloed data systems. These environments often consist of multiple disconnected systems, each managing distinct functions policy administration, claims processing, billing and customer relationship management all generating exponentially growing data as businesses scale.
Establishing AI guidelines and policies One of the first things we asked ourselves was: What does AI mean for us? Having clear AI policies isnt just about risk mitigation; its about controlling our own destiny in this rapidly evolving space. Mike Vaughan serves as Chief Data Officer for Brown & Brown Insurance.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects.
It must be a joint effort involving everyone who uses the platform, from dataengineers and scientists to analysts and business stakeholders. For example, avoid running idle clusters by setting up auto-termination policies and ensure that workloads are matched to cluster sizes to prevent overprovisioning.
It must be a joint effort involving everyone who uses the platform, from dataengineers and scientists to analysts and business stakeholders. For example, avoid running idle clusters by setting up auto-termination policies and ensure that workloads are matched to cluster sizes to prevent overprovisioning.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. The post Cloudera DataEngineering 2021 Year End Review appeared first on Cloudera Blog.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows. The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both.
At Cloudera, we introduced Cloudera DataEngineering (CDE) as part of our Enterprise Data Cloud product — Cloudera Data Platform (CDP) — to meet these challenges. In a nutshell, the bin-packing policy can help nodes scaling down because the scheduler tries to “pack” the pods into fewer nodes. .
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
For example, if one of our teams is working with a customer on a commercial property policy and our data can surface insights in real-time like whether that customer also might benefit from management liability coverage our team can offer a more holistic solution.
Application data architect: The application data architect designs and implements data models for specific software applications. Information/data governance architect: These individuals establish and enforce data governance policies and procedures.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
Fernandes says that IT leaders also need to secure data and IP, especially as agentic AI becomes more prevalent. Were going to identify and hire dataengineers and data scientists from within and beyond our organization and were going to get ahead, he says.
Not cleaning your data enough causes obvious problems, but context is key. To understand if you’re getting value from data cleaning, start by defining success and understanding the point of the model, says Howard Friedman, adjunct professor of health policy and management at Columbia University.
And in a mature ML environment, ML engineers also need to experiment with serving tools that can help find the best performing model in production with minimal trials, he says. Dataengineer. Dataengineers build and maintain the systems that make up an organization’s data infrastructure. Domain expert.
I mentioned in an earlier blog titled, “Staffing your big data team, ” that dataengineers are critical to a successful data journey. That said, most companies that are early in their journey lack a dedicated engineering group. Image 1: DataEngineering Skillsets.
Data privacy regulations such as GDPR , HIPAA , and CCPA impose strict requirements on organizations handling personally identifiable information (PII) and protected health information (PHI). Ensuring compliant data deletion is a critical challenge for dataengineering teams, especially in industries like healthcare, finance, and government.
Key elements of this foundation are data strategy, data governance, and dataengineering. A healthcare payer or provider must establish a data strategy to define its vision, goals, and roadmap for the organization to manage its data. This is the overarching guidance that drives digital transformation.
Step 2: Configure Access Policies in Key Vault In your Key Vault, go to Access Policies and select Add Access Policy. In your Key Vault, add an access policy for this managed identity, allowing Get and List permissions for secrets. Give each secret a clear name, as youll use these names to reference them in Synapse.
By harnessing cutting-edge AI and advanced data analysis techniques, participants, from seasoned professionals to aspiring data scientists, are building tools to empower educators and policy makers worldwide to improve teaching and learning. The need for innovation in education is undeniable. percentage points per year.
Data Science and Machine Learning sessions will cover tools, techniques, and case studies. This year’s sessions on DataEngineering and Architecture showcases streaming and real-time applications, along with the data platforms used at several leading companies. Here are some examples: Data Case Studies (12 presentations).
That’s why Cloudera added support for the REST catalog : to make open metadata a priority for our customers and to ensure that data teams can truly leverage the best tool for each workload– whether it’s ingestion, reporting, dataengineering, or building, training, and deploying AI models.
The company was founded in 2021 by Brian Ip, a former Goldman Sachs executive, and dataengineer YC Chan. The funding will be used to add more features to Omni, including a recruitment module by the third quarter and a performance enhancement module by the end of the year. He added that Rippling and other top U.S.
Database developers should have experience with NoSQL databases, Oracle Database, big data infrastructure, and big dataengines such as Hadoop. These candidates will be skilled at troubleshooting databases, understanding best practices, and identifying front-end user requirements.
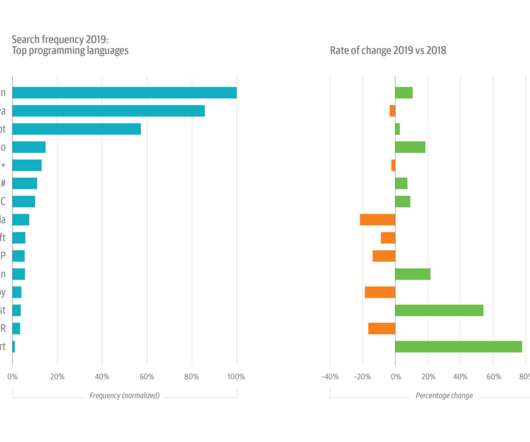
The results for data-related topics are both predictable and—there’s no other way to put it—confusing. Starting with dataengineering, the backbone of all data work (the category includes titles covering data management, i.e., relational databases, Spark, Hadoop, SQL, NoSQL, etc.). This follows a 3% drop in 2018.
This directly impacted use cases that require access to raw files/objects such as dataengineering with Hive, Apache Spark, and Apache Pig. This service enables data owners to audit and control access to files and directories in cloud storage using Apache Ranger as a centralized repository for data security policies.
However, it not only increases costs but requires duplication of policies and yet another external tool to manage. That’s why we are excited to introduce Spark Secure Access , a new security feature for Apache Spark in the Cloudera Data Platform (CDP), that adheres to all security policies without resorting to 3rd party tools.
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
The counterpoint is that with increased decentralization, engineers will increasingly develop subject-matter experience. A lot of companies have dedicated data science and dataengineering resources to the HR and Finance teams, as an example. The market for tools to software engineer will keep growing.
This approach supports the broader goal of digital transformation, making sure that archival data can be effectively used for research, policy development, and institutional knowledge retention. Ian Thompson is a DataEngineer at Enterprise Knowledge, specializing in graph application development and data catalog solutions.
Cloudera Operational Database (COD) plays the crucial role of a data store in the enterprise data lifecycle. You can use COD with: Cloudera DataFlow to ingest and aggregate data from various sources. Cloudera DataEngineering to ingest bulk data and data from mainframes. Cloudera DataEngineering.
The SOC 2 Type II Certification consists of a careful examination by a third party firm of Cloudera’s internal control policies and practices over a specified time period. The SOC 2 certification helps ensure that applications and code are developed, reviewed, tested, and released following the AICPA Trust Services Principles.
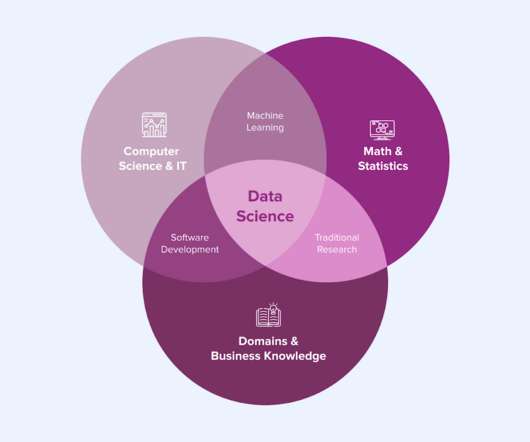
Ideally, ‘ facilitate individual business domains with their ‘insights’ demand ’ means: individual business domains are capable to take ownership of creating and operating their own ‘data and insights’ needs. Let’s first briefly explore the world of Data Science and better understand why DevOps can help.
YuniKorn supports FIFO/FAIR/Priority (WIP) job ordering policies. In the above example of a queue structure in YuniKorn, namespaces defined in Kubernetes are mapped to queues under the Namespaces parent queue using a placement policy. Many times, such policies help to define stricter SLA’s for job execution. Job ordering.
From our release of advanced production machine learning features in Cloudera Machine Learning, to releasing CDP DataEngineering for accelerating data pipeline curation and automation; our mission has been to constantly innovate at the leading edge of enterprise data and analytics.
Or, to state it formally, model interpretation can be defined as the ability to better understand the decision policies of a machine-learned response function to explain the relationship between independent (input) and dependent (target) variables, preferably in a human interpretable way. Conclusion.
“Access to data allows users to make better decisions, drives efficiency in providing analytics, enables us to serve clients faster and with more knowledge, and begins to show possibilities for new products and services that may not have been apparent until the data was viewed more holistically,” she says.
The answer lies in three critical areas: people, processes, and policy faults. Of the organizations surveyed, 52 percent were seeking machine learning modelers and data scientists, 49 percent needed employees with a better understanding of business use cases, and 42 percent lacked people with dataengineering skills.
RAZ for S3 and RAZ for ADLS introduce FGAC and Audit on CDP’s access to files and directories in cloud storage making it consistent with the rest of the SDX data entities. In this blog post we’ll compare implementing policies using the group-based mechanism (IDBroker) to how it is done in a RAZ-enabled environment. .
But many organizations are limiting use of public tools while they set policies to source and use generative AI models. CIOs want to take advantage of this but on their terms—and their own data. To get good output, you need to create a data environment that can be consumed by the model,” he says.
The administrator can configure the appropriate privileges by updating the runtime role with an inline policy, allowing SageMaker Studio users to interactively create, update, list, start, stop, and delete EMR Serverless clusters. An ML platform administrator can manage permissioning for the EMR Serverless integration in SageMaker Studio.
Data scientists and dataengineers want full control over every aspect of their machine learning solutions and want coding interfaces so that they can use their favorite libraries and languages. At the same time, business and data analysts want to access intuitive, point-and-click tools that use automated best practices.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content