This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Curate the data.
The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both. Imagine that you’re a dataengineer. The data is spread out across your different storage systems, and you don’t know what is where. Through relentless innovation.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. This approach ensures that decisions are made with both performance and budget in mind.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. This approach ensures that decisions are made with both performance and budget in mind.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Cloudera is committed to providing the most optimal architecture for data processing, advanced analytics, and AI while advancing our customers’ cloud journeys. Together, Cloudera and AWS empower businesses to optimize performance for data processing, analytics, and AI while minimizing their resource consumption and carbon footprint.
It’s gaining popularity due to its simplicity and performance – currently getting over 1.5 However, DuckDB doesn’t provide data governance support yet. Unity Catalog gives you centralized governance, meaning you get great features like access controls and data lineage to keep your tables secure, findable and traceable.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage.
The shift to cloud has been accelerating, and with it, a push to modernize data pipelines that fuel key applications. That is why cloud native solutions which take advantage of the capabilities such as disaggregated storage & compute, elasticity, and containerization are more paramount than ever. 4xlarge nodes was used.
The data preparation process should take place alongside a long-term strategy built around GenAI use cases, such as content creation, digital assistants, and code generation. Known as dataengineering, this involves setting up a data lake or lakehouse, with their data integrated with GenAI models.
A few months ago, I wrote about the differences between dataengineers and data scientists. An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as dataengineers at dataengineering. Dataengineering is not in the limelight.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
A cloud architect has a profound understanding of storage, servers, analytics, and many more. Big DataEngineer. Another highest-paying job skill in the IT sector is big dataengineering. And as a big dataengineer, you need to work around the big data sets of the applications.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
This could provide both cost savings and performance improvements. Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. With a soft delete, deletion vectors are marked rather than physically removed, which is a performance boost.
The Iceberg REST catalog specification is a key component for making Iceberg tables available and discoverable by many different tools and execution engines. It enables easy integration and interaction with Iceberg table metadata via an API and also decouples metadata management from the underlying storage.
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
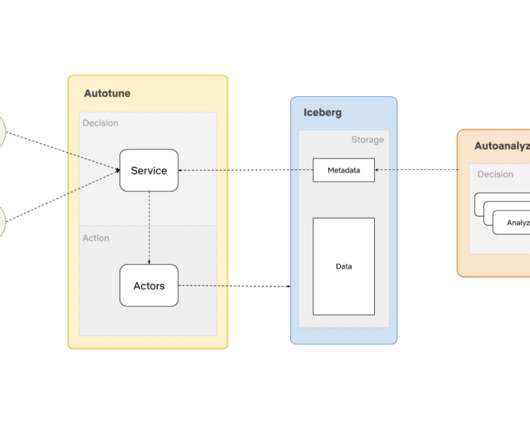
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
Introduction: We often end up creating a problem while working on data. So, here are few best practices for dataengineering using snowflake: 1.Transform So, resist the temptation to periodically load data using other methods (such as querying external tables). Use it, but don’t use it for normal large data loads.
With the ability to quickly provision on-demand and the lower fixed and administrative costs, the costs of operating a cloud data warehouse are driven mostly by the price-performance of the specific data warehouse platform. CDW is one of several managed services that comprise the broader Cloudera Data Platform (CDP).
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A REST API is built directly into our VSP storage controllers.
Are you a dataengineer or seeking to become one? This is the first entry of a series of articles about skills you’ll need in your everyday life as a dataengineer. Data cleansing and enrichment processes need to combine, filter, aggregate, and select different sets to answer questions we have. CROSS JOIN.
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. It empowers employees to be more creative, data-driven, efficient, prepared, and productive.
And as data workloads continue to grow in size and use, they continue to become ever more complex. On top of that, today there are a wide range of applications and platforms that a typical organization will use to manage source material, storage, usage and so on. Doing so manually can be time-consuming, if not impossible.
CEO Ketan Umare says that the proceeds will be put toward supporting the Flyte community by “improving the accessibility, performance and reliability of Flyte” and broadening the array of systems that Flyte integrates with.
The forecasting systems DTN had acquired were developed by different companies, on different technology stacks, with different storage, alerting systems, and visualization layers. Working with his new colleagues, he quickly identified rebuilding those five systems around a single forecast engine as a top priority.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
The core roles in a platform engineering team range from infrastructure engineers, software developers, and DevOps tool engineers, to database administrators, quality assurance, API and security engineers, and product architects. Train up Building high performing teams starts with training, Menekli says. “We
In one use case, AR and VR are being used to re-create people’s spines in a model so that surgeons can look at them in advance of surgeries to help them perform better, says Peter Fleischut, group senior vice president and chief information and transformation officer.
Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. Data analytics and data science are closely related.
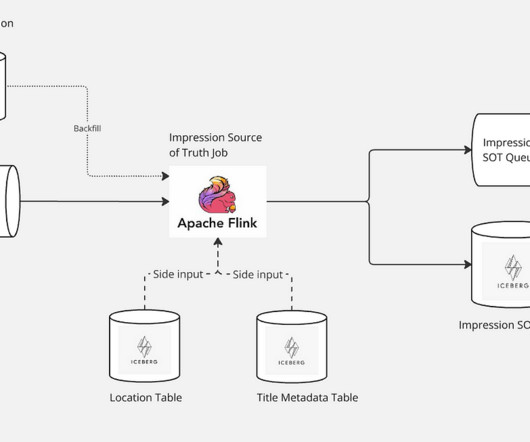
This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
When asked, Heartex says that it doesn’t collect any customer data and open sources the core of its labeling platform for inspection. “We’ve built a data architecture that keeps data private on the customer’s storage, separating the data plane and control plane,” Malyuk added.
Snowflake, Redshift, BigQuery, and Others: Cloud Data Warehouse Tools Compared. From simple mechanisms for holding data like punch cards and paper tapes to real-time data processing systems like Hadoop, datastorage systems have come a long way to become what they are now. Is it still so?
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Supports Disaggregation of compute and storage.
The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket. Solution overview Amazon Q Business is a fully managed, generative AI-powered assistant that helps enterprises unlock the value of their data and knowledge.
A columnar storage format like parquet or DuckDB internal format would be more efficient to store this dataset. This size reduction can have positive impact on loading and writing data to disk. And is a cost saver for cloud storage. This is a binary format that is optimized for query performance. parquet # 1.2G
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content