This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Shared data assets, such as product catalogs, fiscal calendar dimensions, and KPI definitions, require a common vocabulary to help avoid disputes during analysis. Curate the data. Invest in core functions that performdata curation such as modeling important relationships, cleansing raw data, and curating key dimensions and measures.
The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows. The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
Scalability and Flexibility: The Double-Edged Sword of Pay-As-You-Go Models Pay-as-you-go pricing models are a game-changer for businesses. In these scenarios, the very scalability that makes pay-as-you-go models attractive can undermine an organization’s return on investment.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
At Cloudera, we introduced Cloudera DataEngineering (CDE) as part of our Enterprise Data Cloud product — Cloudera Data Platform (CDP) — to meet these challenges. YuniKorn’s Gang scheduling and bin-packing help boost autoscaling performance and improve resource utilization. Summary of Workload Performance Results.
Cloudera sees success in terms of two very simple outputs or results – building enterprise agility and enterprise scalability. Contrast this with the skills honed over decades for gaining access, building data warehouses, performing ETL, creating reports and/or applications using structured query language (SQL).
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. CRM platforms).
Software projects of all sizes and complexities have a common challenge: building a scalable solution for search. For this reason and others as well, many projects start using their database for everything, and over time they might move to a search engine like Elasticsearch or Solr. You might be wondering, is this a good solution?
The data preparation process should take place alongside a long-term strategy built around GenAI use cases, such as content creation, digital assistants, and code generation. Known as dataengineering, this involves setting up a data lake or lakehouse, with their data integrated with GenAI models.
But when the size of a dbt project grows, and the number of developers increases, then an automated approach is often the only scalable way forward. What other checks can dbt-bouncer perform? check_exposure_based_on_view ensures exposures are not based on views as this may result in poor performance for data consumers.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, such as AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
The funding will be used to add more features to Omni, including a recruitment module by the third quarter and a performance enhancement module by the end of the year. The company was founded in 2021 by Brian Ip, a former Goldman Sachs executive, and dataengineer YC Chan.
Integrated Data Lake Synapse Analytics is closely integrated with Azure Data Lake Storage (ADLS), which provides a scalable storage layer for raw and structured data, enabling both batch and interactive analytics. When Should You Use Azure Synapse Analytics?
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. It empowers employees to be more creative, data-driven, efficient, prepared, and productive.
This could provide both cost savings and performance improvements. With a soft delete, deletion vectors are marked rather than physically removed, which is a performance boost. There is a catch once we consider data deletion within the context of regulatory compliance. What Are Deletion Vectors?
Firebolt’s pitch is that it has built a SQL-based architecture that handles this challenge better than anything that has come before it, using new techniques in compression that can connect data lakes and result in smaller cloud capacity requirements, resulting in lower costs and better performance, up to 182 times faster than that of other data (..)
Platform engineering: purpose and popularity Platform engineering teams are responsible for creating and running self-service platforms for internal software developers to use. Staff up for the future Simms also looks for skill sets that will prepare the organization for the future, including AI, ML, and chaos engineering.
Breaking down silos has been a drumbeat of data professionals since Hadoop, but this SAP <-> Databricks initiative may help to solve one of the more intractable dataengineering problems out there. SAP has a large, critical data footprint in many large enterprises. However, SAP has an opaque data model.
One key to more efficient, effective AI model and application development is executing workloads on compute platforms that offer high scalability, performance, and concurrency.
With the ability to quickly provision on-demand and the lower fixed and administrative costs, the costs of operating a cloud data warehouse are driven mostly by the price-performance of the specific data warehouse platform. CDW is one of several managed services that comprise the broader Cloudera Data Platform (CDP).
With App Studio, technical professionals such as IT project managers, dataengineers, enterprise architects, and solution architects can quickly develop applications tailored to their organizations needswithout requiring deep software development skills. Outside of work, Samit enjoys playing cricket, traveling, and biking.
That amount of data is more than twice the data currently housed in the U.S. Nearly 80% of hospital data is unstructured and most of it has been underutilized until now. To build effective and scalable generative AI solutions, healthcare organizations will have to think beyond the models that are visible at the surface.
The demand for specialized skills has boosted salaries in cybersecurity, data, engineering, development, and program management. It’s a role that not only requires technical skills, but also leadership and communication skills as well to work across departments and to manage teams of engineers. increase from 2021.
Technologies that have expanded Big Data possibilities even further are cloud computing and graph databases. The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer?
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way.
Data Warehouse – in addition to a number of performance optimizations, DW has added a number of new features for better scalability, monitoring and reliability to enable self-service access with security and performance . Enrich – DataEngineering (Apache Spark and Apache Hive). New Services.
This will empower businesses and accelerate the time to market by creating: A data asset which supports business self-service, data science, and shadow IT Technology enabled scalability, cross self-service, shadow IT, data science, and IT industrialized solutions. To read the full whitepaper, click here.
As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. In the Performance space, our data teams currently focus on the quality of experience on Netflix-enabled devices.
It’s also used to deploy machine learning models, data streaming platforms, and databases. A cloud-native approach with Kubernetes and containers brings scalability and speed with increased reliability to data and AI the same way it does for microservices. Every machine learning model is underpinned by data.
To do so, the team had to overcome three major challenges: scalability, quality and proactive monitoring, and accuracy. The opportunity to predict IDH during a dialysis treatment is one of several building blocks to transform our company into the world of the Internet of Things, big data, and artificial intelligence,” he says.
Aurora MySQL-Compatible is a fully managed, MySQL-compatible, relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management.
“When you think about what skill sets do you need, it’s a broad spectrum: dataengineering, data storage, scientific experience, data science, front-end web development, devops, operational experience, and cloud experience.”.
However, in the typical enterprise, only a small team has the core skills needed to gain access and create value from streams of data. This dataengineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. A rare breed. This is a task best left to expert Java programming minds.
I have discussed the seven pillars of the well-archotected lakehouse framework in general and now I want to focus on performance efficiency. Performance Efficiency I previously wrote about cost optimization and performance efficiency is a key lever to pull in the drive to manage cost. Technically, this is what Spark does.
Inside the ‘factory’ Aside from its core role as a migration platform, Network Alpha Factory also delivers network scalability and a bird’s-eye view of an enterprise’s entire network landscape, including where upgrades may be needed. Network Alpha Factory also provides data intelligence and the ability to decommission legacy devices.
Data Modelers: They design and create conceptual, logical, and physical data models that organize and structure data for best performance, scalability, and ease of access. In the 1990s, data modeling was a specialized role.
We’ll review all the important aspects of their architecture, deployment, and performance so you can make an informed decision. Before jumping into the comparison of available products right away, it will be a good idea to get acquainted with the data warehousing basics first. Different data is processed in parallel on different nodes.
“Organizations are spending billions of dollars to consolidate its data into massive data lakes for analytics and business intelligence without any true confidence applications will achieve a high degree of performance, availability and scalability. The post Immuta raises $1.5M
John Snow Labs’ Medical Language Models library is an excellent choice for leveraging the power of large language models (LLM) and natural language processing (NLP) in Azure Fabric due to its seamless integration, scalability, and state-of-the-art accuracy on medical tasks. See here for benchmarks and responsibly developed AI practices.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























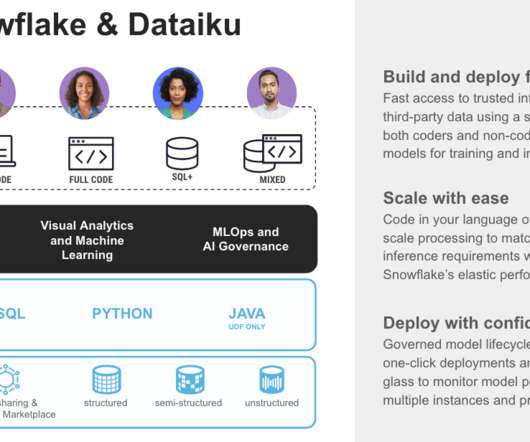


















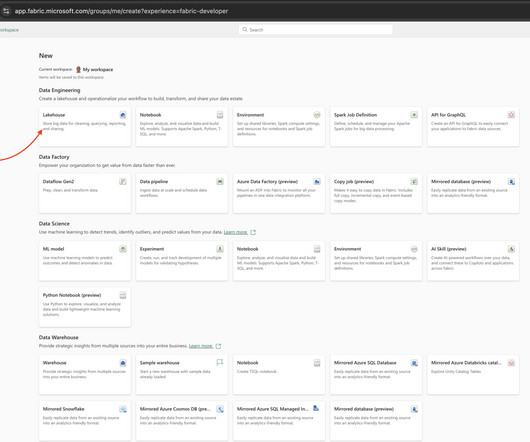









Let's personalize your content