

Data engineers vs. data scientists
O'Reilly Media - Data
APRIL 11, 2018
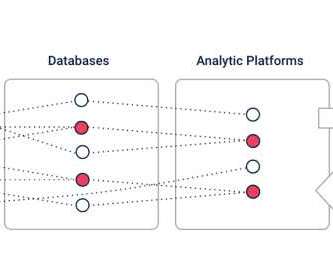
It’s important to understand the differences between a data engineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and data engineers.















































Let's personalize your content