This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. Operational errors because of manual management of data platforms can be extremely costly in the long run.
Heartex, a startup that bills itself as an “opensource” platform for data labeling, today announced that it landed $25 million in a Series A funding round led by Redpoint Ventures. ” Software developers Malyuk, Maxim Tkachenko, and Nikolay Lyubimov co-founded Heartex in 2019. Heartex’s dashboard.
Gartner reported that on average only 54% of AI models move from pilot to production: Many AI models developed never even reach production. These days Data Science is not anymore a new domain by any means. Data Science profiles are more abundant in the market than ever before. First let’s throw in a statistic. Why is that?
Challenges of growing Imagine the following scenario, you have a dbt project and you are successfully delivering valuable data to your business stakeholders. These contributors can be from your team, a different analytics team, or a different engineeringteam. Sometimes this is in the README.md
“Most of the technical content published misses the mark with developers. I think we can all do a better job,” author and developer marketing expert Adam DuVander says. DuVander was recommended to us by Karl Hughes, the CEO of Draft.dev, which specializes in content production for developer-focused companies.
Goldcast, a software developer focused on video marketing, has experimented with a dozen open-source AI models to assist with various tasks, says Lauren Creedon, head of product at the company. The company isn’t building its own discrete AI models but is instead harnessing the power of these open-source AIs.
DevOps continues to get a lot of attention as a wave of companies develop more sophisticated tools to help developers manage increasingly complex architectures and workloads. “Users didn’t know how to organize their tools and systems to produce reliable data products.” ” Not a great scenario.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Data scientists and analysts, dataengineers, and the people who manage them comprise 40% of the audience; developers and their managers, about 22%. Data quality might get worse before it gets better. Comparatively few organizations have created dedicated data quality teams. This is hardly surprising.
Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. Apache Kafka is an open-source, distributed streaming platform for messaging, storing, processing, and integrating large data volumes in real time.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
Recruiting is one of those things where the Dunning-Kruger effect is the most pronounced: the more you do it, the more you realize how bad you are at it. Blog, talk at meetups, opensource stuff , go to conferences. I think most people in the industry are fed up with bad bulk messages over email/LinkedIn.
Recruiting is one of those things where the Dunning-Kruger effect is the most pronounced: the more you do it, the more you realize how bad you are at it. Blog, talk at meetups, opensource stuff , go to conferences. I think most people in the industry are fed up with bad bulk messages over email/LinkedIn.
web development, data analysis. Source: Python Developers Survey 2020 Results. This distinguishes Python from domain-specific languages like HTML and CSS limited to web design or SQL created for accessing data in relational database management systems. many others. How Python is used. Object-oriented.
Data Scientist Cathy O’Neil has recently written an entire book filled with examples of poor interpretability as a dire warning of the potential social carnage from misunderstood models—e.g., Interpreting high-dimensional MNIST data by visualizing in 3D using PCA for building domain knowledge using TensorFlow.
Rule-based fraud detection software is being replaced or augmented by machine-learning algorithms that do a better job of recognizing fraud patterns that can be correlated across several datasources. DataOps is required to engineer and prepare the data so that the machine learning algorithms can be efficient and effective.
Maintained by the Apache Software Foundation, Apache Spark is an open-source, unified engine designed for large-scale data analytics. With its native support for in-memory distributed processing and fault tolerance, Spark empowers users to build complex, multi-stage data pipelines with relative ease and efficiency.
Gone are the days of a web app being developed using a common LAMP (Linux, Apache, MySQL, and PHP ) stack. What’s more, this software may run either partly or completely on top of different hardware – from a developer’s computer to a production cloud provider. Since its creation, Docker has been an open-source project.
Whether it’s controlling for common risk factors—bias in model development, missing or poorly conditioned data, the tendency of models to degrade in production—or instantiating formal processes to promote data governance, adopters will have their work cut out for them as they work to establish reliable AI production lines.
Besides simply looking for email addresses associated with spam, these systems notice slight indications of spam emails, like bad grammar and spelling, urgency, financial language, and so on. Often used for directing customer requests to an appropriate team, language detection highlights the languages used in emails and chats.
You already know the game and how it is played: you’re the coordinator who ties everything together, from the developers and designers to the executives. Why AI software development is different. AI products are automated systems that collect and learn from data to make user-facing decisions.
The former extracts and transforms information before loading it into centralized storage while the latter allows for loading data prior to transformation. Developed in 2012 and officially launched in 2014, Snowflake is a cloud-based data platform provided as a SaaS (Software-as-a-Service) solution with a completely new SQL query engine.
When it comes to organising engineeringteams, a popular view has been to organise your teams based on either Spotify's agile model (i.e. squads, chapters, tribes, and guilds) or simply follow Amazon's two-pizza team model. It is one of the ways you can organise your engineeringteams in a retail environment.
The Cloudera Data Platform comprises a number of ‘data experiences’ each delivering a distinct analytical capability using one or more purposely-built Apache opensource projects such as Apache Spark for DataEngineering and Apache HBase for Operational Database workloads.
Let’s dive into the intricacies of these data integration giants and uncover the key differences that could sway your decision. However, each tool has its own strengths and weaknesses. This comparison will help you make an informed decision and ensure that your data flows smoothly.
The Deliveroo Engineering organisation is in the process of decomposing a monolith application into a suite of microservices. The team began investigating the range of encoding formats that would suit Deliveroo’s requirements. Because it builds on top of Apache Kafka we decided to call it Franz. Deciding on an Encoding Format.
Three types of data migration tools. Use cases: small projects, specific source and target locations not supported by other solutions. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. Phases of the data migration process. Self-scripted tools.
Veracity is the measure of how truthful, accurate, and reliable data is and what value it brings. Data can be incomplete, inconsistent, or noizy, decreasing the accuracy of the analytics process. Due to this, data veracity is commonly classified as good, bad, and undefined. Big Data analytics processes and tools.
Alexander Rinke, co-founder and co-CEO of Celonis, emphasizes the importance of process analysis and optimization BEFORE starting an RPA project: “If a process is already flawed, RPA will only make a bad process faster. How a procure to pay process may look like, source: Processand. Build the team. Payment is processed.
Iceberg is an emerging open-table format designed for large analytic workloads. The Apache Iceberg project continues developing an implementation of Iceberg specification in the form of Java Library. However, other query engines such as Hive and Spark can also benefit from this Iceberg improvement as well.
What’s more, that data comes in different forms and its volumes keep growing rapidly every day — hence the name of Big Data. The good news is, businesses can choose the path of data integration to make the most out of the available information. On-premise data integration tools. Cloud-based data integration tools.
CONFERENCE RECAP Platform engineering, AI, APIs, abstractions, portals, security, patent trolls, andmore! The Syntasso team and I have returned home from a successful KubeCon NA in Salt Lake City ! Bridging the worlds of software developers and platform engineers appears vitally important.
To optimise our use of data, we need services which store it reliably, provide interfaces for analysis and automate transformation. In developing and configuring these services we must walk a fine line between security and usability. Usability, because business value depends on frictionless access to data. DataEngineering.
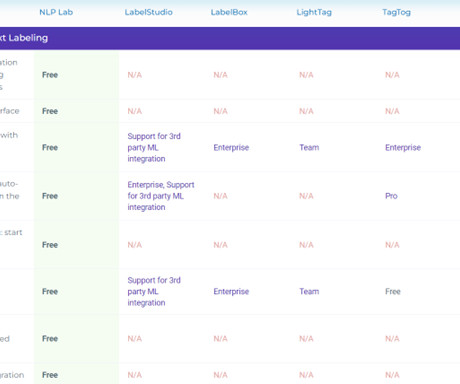
Developing a machine learning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case. Developing such tools from scratch is a highly time-consuming and an effort-intensive process. – It offers documentation and live demos for ease of use.
Models are trained on existing data to recognize recurring patterns, often leading to specific results. Related: Gain confidence in your forecasts by hiring top dedicated developers with Mobilunity for unparalleled accuracy. For example, supervised frameworks can be developed to recognize different objects in an image. #2
Now the ball is in the application developers court: Where, when, and how will AI be integrated into the applications we build and use every day? And if AI replaces the developers, who will be left to do the integration? Our data shows how our users are reacting to changes in the industry: Which skills do they need to brush up on?
Data scientists, dataengineers, AI and ML developers, and other data professionals need to live ethical values, not just talk about them. The hard thing about being an ethical data scientist isn’t understanding ethics. It’s doing good data science. So, we’re not working in a vacuum.
Remember that these “units” are “viewed” by our users, who are largely professional software developers and programmers. Software Development Most of the topics that fall under software development declined in 2023. Software developers are responsible for designing and building bigger and more complex projects than ever.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. Source: Apache Airflow.
Now developers are using AI to write software. Content about software development was the most widely used (31% of all usage in 2022), which includes software architecture and programming languages. Practices like the use of code repositories and continuous testing are still spreading to both new developers and older IT departments.
AI is making that transition now; we can see it in our data. What developments represent new ways of thinking, and what do those ways of thinking mean? What are the bigger changes shaping the future of software development and software architecture? What does that mean, and how is it affecting software developers?
So BPM is today another form of low-code application development. Expect true zero code delivery, best of breed opensource, 100% event-driven architecture, 100% microservices based, SDKs in all major languages, and a simple, fast, sleek new design. Success will require teams to listen to the business not just to the data.
We were also interested in the practice of AI: how developers work, what techniques and tools they use, what their concerns are, and what development practices are in place. That clearly doesn’t reflect reality; China is a leader in AI and probably has more AI developers than any other nation, including the US.
Data warehouses have been broadly adopted to provide timely reports and valuable insights. They require skilled central IT teams to tackle technical complexities and long lead times in planning, procuring, and provisioning. In a multi-tenant environment, many users access the same datasources. CDW minimizes contention.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content