This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Microservices seem to be everywhere. Scratch that: talk about microservices seems to be everywhere. So we wanted to determine to what extent, and how, O’Reilly subscribers are empirically using microservices. Here’s a summary of our key findings: Most adopters are successful with microservices. And that’s the problem.
Today, IT encompasses site reliability engineering (SRE), platform engineering, DevOps, and automation teams, and the need to manage services across multi-cloud and hybrid-cloud environments in addition to legacy systems. Experience and deliberate cross-functional learning opportunities are needed for people to acquire these skills.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
It’s possible that microservices architecture is hastening the move to other languages (such as Go, Rust, and Python) for web properties. Kubernetes has emerged as the de facto solution for orchestrating services and microservices in cloud native design patterns. Most cloud native design patterns involve microservices.
Data scientists may build the ML models, but its ML engineers who implement them. This person is tasked with packing the ML model into a container and deploying to production — usually as a microservice,” says Dattaraj Rao, innovation and R&D architect at technology services company Persistent Systems. Dataengineer.
The target architecture of the data economy is platform-based , cloud-enabled, uses APIs to connect to an external ecosystem, and breaks down monolithic applications into microservices. To solve this, we’ve kept dataengineering in IT, but embedded machine learning experts in the business functions. The cloud.
Cloud-native apps, microservices and mobile apps drive revenue with their real-time customer interactions. It’s clear how these real-time data sources generate data streams that need new data and ML models for accurate decisions. It’s also used to deploy machine learning models, data streaming platforms, and databases.
You’ll be required to write code, troubleshoot systems, fix bugs, and assist with the development of microservices. In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems.
You’ll be required to write code, troubleshoot systems, fix bugs, and assist with the development of microservices. In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems.
Considering dataengineering and data science, Astro and Apache Airflow rise to the top as important tools used in the management of these data workflows. This should help software developers and dataengineers in selecting the right tool for their specific needs and project requirements.
Key survey results: The C-suite is engaged with data quality. Data scientists and analysts, dataengineers, and the people who manage them comprise 40% of the audience; developers and their managers, about 22%. Data quality might get worse before it gets better. An additional 7% are dataengineers.
Skills++: Induct specialised Frontend, Backend & QA engineers, Technical Leadership 21-30 Engineers Focus: Building quality in products and continue to innovate while proactively planning team structure, incentives, and culture. Architecture: Small microservices targeting new features. Adopt DevSecOps best-practices.
KDE handles over 10B flow records/day with a microservice architecture that's optimized using metrics. Here at Kentik, our Kentik Detect service is powered by a multi-tenant big data datastore called Kentik DataEngine. So it was critical to instrument every component leading to, around, and within our dataengine.
Tech Conferences Compass Tech Summit – October 5-6 Compass Tech Summit is a remarkable 5-in-1 tech conference, encompassing topics such as engineering leadership, AI, product management, UX, and dataengineering that will take place on October 5-6 at the Hungarian Railway Museum in Budapest, Hungary.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
Get hands-on training in Docker, microservices, cloud native, Python, machine learning, and many other topics. Microservices Architecture and Design , July 8-9. Practical Linux Command Line for DataEngineers and Analysts , July 22. Domain-driven design and event-driven microservices , July 23-24.
Out of the box Cloudera Data platform (CDP) performs superbly but over time, if data architecture, dataengineering, and DevOps best practices are not maintained, you can get stuck maintaining the wild, wild west. In this six-part series, we’re focused on improving the health of your environment.
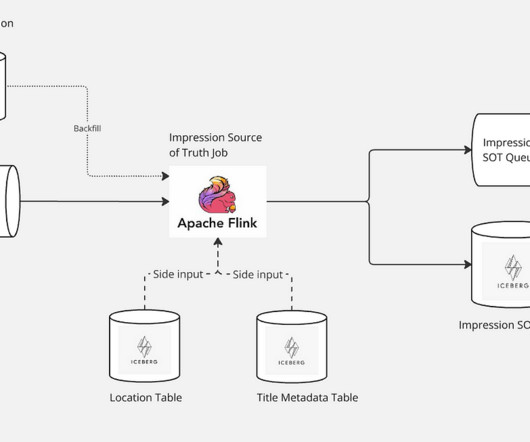
Stay tuned for the next part of this series, where well delve into how we use this SOT dataset to create a microservice that provides impression histories. Conclusion Creating a reliable source of truth for impressions is a complex but essential task that enhances personalization and discovery experience.
Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , March 13. Data Modelling with Qlik Sense , March 19-20. Foundational Data Science with R , March 26-27. What You Need to Know About Data Science , April 1. Microservice Fundamentals , April 15.
Russ Miles – Chaos Engineer Thought Leader & Author of multiple books including “Antifragile Software: Building Adaptable Software with Microservices”. Chris Richardson – Developer & Architect, Author of “POJOs in Action“ and “Microservices patterns“, Founder at Eventuate.
And Holochain is a decentralized framework for building peer-to-peer microservices–no cloud provider needed. ApacheHop is a metadata-driven data orchestration for building dataflows and data pipelines. It integrates with Spark and other dataengines, and is programmed using a visual drag-and-drop interface, so it’s low code.
Custom and off-the-shelf microservices cover the complexity of security, scalability, and data isolation and integrate into complex workflows through orchestration. That lack of support leaves the citizen report builders and data scientists with no way to act on that data.
We can’t wait to attend them all: Best practices in a modern (microservices) environment by Alvaro García. Micro Frontend: the microservice puzzle extended to frontend by Audrey Neveu. Nowadays Architecture Trends, from Monolith to Microservices and Serverless by Alberto Salazar. Responsible Microservices by Nate Schutta.
Get hands-on training in Docker, microservices, cloud native, Python, machine learning, and many other topics. Microservices Architecture and Design , July 8-9. Practical Linux Command Line for DataEngineers and Analysts , July 22. Domain-driven design and event-driven microservices , July 23-24.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Native frameworks.
The concept of the data mesh architecture is not entirely new; Its conceptual origins are rooted in the microservices architecture, its design principles (i.e.,
One-sixth of respondents identify as data scientists, but executives—i.e., The survey does have a data-laden tilt, however: almost 30% of respondents identify as data scientists, dataengineers, AIOps engineers, or as people who manage them. All told, more than 70% of respondents work in technology roles.
In this post, we will discuss why you should avoid building data pipelines in first place. Depending on the use cases, it is quite possible that you can achieve similar outcomes by using techniques such as data virtualisation or simply building microservices. It can be used to power new analytics, insight, and product features.
Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , May 20. First Steps in Data Analysis , May 20. Data Analysis Paradigms in the Tidyverse , May 30. Data Visualization with Matplotlib and Seaborn , June 4. Microservices Caching Strategies , June 17.
AWS Amplify is a good choice as a development platform when: Your team is proficient with building applications on AWS with DevOps, Cloud Services and DataEngineers. You’re developing a greenfield application that doesn’t require any external data or auth systems. You have existing backend services developed on AWS.
AWS Amplify is a good choice as a development platform when: Your team is proficient with building applications on AWS with DevOps, Cloud Services and DataEngineers. You’re developing a greenfield application that doesn’t require any external data or auth systems. You have existing backend services developed on AWS.
AWS Amplify is a good choice as a development platform when: Your team is proficient with building applications on AWS with DevOps, Cloud Services and DataEngineers. You’re developing a greenfield application that doesn’t require any external data or auth systems. You have existing backend services developed on AWS.
Components that are unique to dataengineering and machine learning (red) surround the model, with more common elements (gray) in support of the entire infrastructure on the periphery. Before you can build a model, you need to ingest and verify data, after which you can extract features that power the model.
A single, unified infrastructure for both majority of batch workloads and microservices. Cloudera’s CDP platform offers Cloudera DataEngineering experience which is powered by Apache YuniKorn (Incubating). Fine-grained access controls on shared clusters. Apache YuniKorn (Incubating) in CDP.
This might mean a complete transition to cloud-based services and infrastructure or isolating an IT or business domain in a microservice, like data backups or auth, and establishing proof-of-concept. Either way, it’s a step that forces teams to deal with new data, network problems, and potential latency.
Since then, open-source Metaflow has gained support for Argo Workflows , a Kubernetes-native orchestrator, as well as support for Airflow which is still widely used by dataengineering teams. Internally, we use a production workflow orchestrator called Maestro. Metaflow Hosting caches the response, so Amber can fetch it after a while.
Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Data analytics — and for the better. DataOps is a relatively new methodology that knits together dataengineering, data analytics, and DevOps to deliver high-quality data products as fast as possible.
Data solution vendors like SnapLogic and Informatica are already developing machine learning and artificial intelligence (AI) based smart data integration assistants. These assistants can recommend next-best-action or suggest datasets, transforms, and rules to a dataengineer working on a data integration project.
In order to utilize the wealth of data that they already have, companies will be looking for solutions that will give comprehensive access to data from many sources. More focus will be on the operational aspects of data rather than the fundamentals of capturing, storing and protecting data.
Our quickly expanding business also means our platform needs to keep ahead of the curve to accommodate the ever-growing volumes of data and increasing complexity of our systems. The Deliveroo Engineering organisation is in the process of decomposing a monolith application into a suite of microservices.
This basic principle corresponds to that of agile software development or approaches such as DevOps, Domain-Driven Design, and Microservices: DevOps (development and operations) is a practice that aims at merging development, quality assurance, and operations (deployment and integration) into a single, continuous set of processes.
It offers features such as data ingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment. The platform offers advanced capabilities for data warehousing (DW), dataengineering (DE), and machine learning (ML), with built-in data protection, security, and governance.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content