This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. Once the decision is made, inefficiencies can be categorized into two primary areas: compute and storage.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. Once the decision is made, inefficiencies can be categorized into two primary areas: compute and storage.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Preql founders Gabi Steele and Leah Weiss were dataengineers in the early days at WeWork. They later opened their own consultancy to help customers build data stacks, and they saw a stubborn consistency in the types of information their clients needed. They don’t stop there though.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
The Principal AI Enablement team, which was building the generative AI experience, consulted with governance and security teams to make sure security and data privacy standards were met. Model monitoring of key NLP metrics was incorporated and controls were implemented to prevent unsafe, unethical, or off-topic responses.
MaestroQA also offers a logic/keyword-based rules engine for classifying customer interactions based on other factors such as timing or process steps including metrics like Average Handle Time (AHT), compliance or process checks, and SLA adherence. Success metrics The early results have been remarkable.
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A REST API is built directly into our VSP storage controllers.
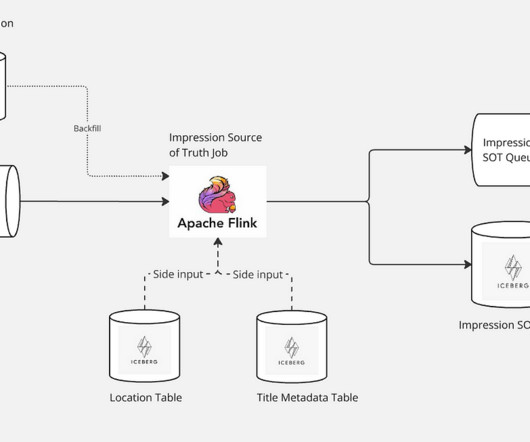
This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
When our dataengineering team was enlisted to work on Tenable One, we knew we needed a strong partner. When Tenable’s product engineering team came to us in dataengineering asking how we could build a data platform to power the product, we knew we had an incredible opportunity to modernize our data stack.
I'm deliberately vague about what exact role I mean here: take it to mean dataengineers, data scientists, ML engineers, analytics engineers, and maybe more roles. But under the hood, the we use a content-addressed storage system. I will be posting a lot more about it! ↩︎
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. To evaluate the models accuracy and track the mechanism, we store every user input and output in Amazon Simple Storage Service (Amazon S3). I am creating a new metric and need the sales data.
Start with storage. Before you can even think about analyzing exabytes worth of data, ensure you have the infrastructure to store more than 1000 petabytes! Going from 250 PB to even a single exabyte means multiplying storage capabilities four times. So, what does it require for organizations to go from PB to EB scale?
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
It means you must collect transactional data and move it from the database that supports transactions to another system that can handle large volumes of data. And, as is common, to transform it before loading to another storage system. But how do you move data? The simplest illustration for a data pipeline.
KDE handles over 10B flow records/day with a microservice architecture that's optimized using metrics. Here at Kentik, our Kentik Detect service is powered by a multi-tenant big data datastore called Kentik DataEngine. And that leads us to metrics. Workers are processes that run on our storage nodes.
Optimized read and write paths to cloud object stores (S3, Azure Data Lake Storage, etc) with local caching, allowing workloads to run directly against data in shared object stores without explicit loading to local storage. No local data loading step was required prior to query execution. Results Drill Down.
People analytics is the analysis of employee-related data using tools and metrics. Dashboard with key metrics on recruiting, workforce composition, diversity, wellbeing, business impact, and learning. Choose metrics and KPIs to monitor and predict. How are given metrics interconnected with each other? Commute time.
When evaluating solutions, whether to internal problems or those of our customers, I like to keep the core metrics fairly simple: will this reduce costs, increase performance, or improve the network’s reliability? In this case, choosing to separate the storage traffic from the normal business traffic enhances both performance and reliability.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a dataengineer? By the way, we have a video dedicated to the dataengineering working principles.
Informatica and Cloudera deliver a proven set of solutions for rapidly curating data into trusted information. Informatica’s comprehensive suite of DataEngineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform.
Here are some tips and tricks of the trade to prevent well-intended yet inappropriate dataengineering and data science activities from cluttering or crashing the cluster. For dataengineering and data science teams, CDSW is highly effective as a comprehensive platform that trains, develops, and deploys machine learning models.
Yet for organizations that only want to get their toes wet and perhaps just evaluate the capability, the 16 cores, 128 GB RAM, and 600 GB of storage prevented them from doing just that. we introduce detailed low resource requirements that reduce the amount of CPU, RAM, and storage needed by up to 75%. With Private Cloud 1.2,
Sometimes, a data or business analyst is employed to interpret available data, or a part-time dataengineer is involved to manage the data architecture and customize the purchased software. At this stage, data is siloed, not accessible for most employees, and decisions are mostly not data-driven.
There is a clear consensus that data teams should express their goals and results in business value terms and not in technical, tactical descriptions, such as “improving dataengineering” and “better master data management.” . Yet if their only purpose is secure datastorage, they know the market will leave them behind.
Performance metrics appear in charts and graphs. . We compare the current run of a job to a baseline derived from performance metrics. Fixed Reports / DataEngineering jobs . Fixed Reports / DataEngineering Jobs. DataEngineering jobs only. DataEngineering jobs. Report Format.
In “ The AI Hierarchy of Needs ,” Monica Rogati argues that you can build an AI capability only after you’ve built a solid data infrastructure, including data collection, datastorage, data pipelines, data preparation, and traditional analytics. If you can’t walk, you’re unlikely to run.
Whether it’s increased predictive accuracy or a quantifiable reduction in readmissions, the metrics should resonate with the key concerns of your identified stakeholders, ensuring the project remains aligned with its core objectives. They’re an evolving set of needs and costs that can change as your project progresses.
Components that are unique to dataengineering and machine learning (red) surround the model, with more common elements (gray) in support of the entire infrastructure on the periphery. Before you can build a model, you need to ingest and verify data, after which you can extract features that power the model.
But, in any case, the pipeline would provide dataengineers with means of managing data for training, orchestrating models, and managing them on production. Getting additional data from feature store. This storage for features provides the model with a quick access to data that can’t be accessed from the client.
In the case of CDP Public Cloud, this includes virtual networking constructs and the data lake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloud storage. Each project consists of a declarative series of steps or operations that define the data science workflow.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing.
DataOps strategies require a robust data infrastructure, including data warehouses, data lakes, caches, and other datastorage and processing systems. DataOps team roles In a DataOps team, several key roles work together to ensure the data pipeline is efficient, reliable, and scalable.
Similar to how DevOps once reshaped the software development landscape, another evolving methodology, DataOps, is currently changing Big Data analytics — and for the better. DataOps is a relatively new methodology that knits together dataengineering, data analytics, and DevOps to deliver high-quality data products as fast as possible.
That first step requires integrating the latest versions of all required open source projects, including not just data processing engines (e.g., Apache Impala, Apache Spark) but also all foundational services needed for storage (e.g., dataengineering pipelines, machine learning models).
In this session, we discuss the technologies used to run a global streaming company, growing at scale, billions of metrics, benefits of chaos in production, and how culture affects your velocity and uptime. Technology advancements in content creation and consumption have also increased its data footprint.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. What does the high-performance data project have to do with the real Franz Kafka’s heritage? process data in real time and run streaming analytics. How Apache Kafka streams relate to Franz Kafka’s books.
DataOps aids data practitioners to continuously deliver quality data to applications and business processes. The end-users of data, like the data analysts and data scientists, work closely with both dataengineers and IT Ops in order to deliver continuous data movement.
The folks on the Cloud DataEngineering (CDE) team, the ones building the paved path for internal data at Netflix, graciously helped us scale it up and make adjustments, but it ended up being an involved process as we kept growing. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
In the digital communities that we live in, storage is virtually free and our garrulous species is generating and storing data like never before. Set short term goals that are clearly measurable and preferably single metrics for each ML program to evaluate progress. A DevOps/SRE approach is essential for the project life cycle.
There are several pillar data sets you have to consider in the first place. Important hotel data sets and overlaps between them. Booking and property data. The main storage of hotel booking information is your property management system (PMS). Data processing in a nutshell and ETL steps outline.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general.
“They combine the best of both worlds: flexibility, cost effectiveness of data lakes and performance, and reliability of data warehouses.”. It allows users to rapidly ingest data and run self-service analytics and machine learning. You can also create metrics to fire alerts when system resources meet specified thresholds.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content