This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This becomes more important when a company scales and runs more machinelearning models in production. Please have a look at this blog post on machinelearning serving architectures if you do not know the difference. Let’s say you are a Data Scientist working in a model development environment.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
Data is a key component when it comes to making accurate and timely recommendations and decisions in real time, particularly when organizations try to implement real-time artificial intelligence. Real-time AI involves processing data for making decisions within a given time frame. It isn’t easy.
Cloudera MachineLearning (CML) is a cloud-native and hybrid-friendly machinelearning platform. It unifies self-service data science and dataengineering in a single, portable service as part of an enterprise data cloud for multi-function analytics on data anywhere. Click +Add Runtime.
Cost and Performance The solution achieves remarkable throughput by processing 100,000 documents within a 12-hour window. Serverless on AWS AWS GovCloud (US) Generative AI on AWS About the Authors Nick Biso is a MachineLearningEngineer at AWS Professional Services. He is also the #1 Square Off player in the world.
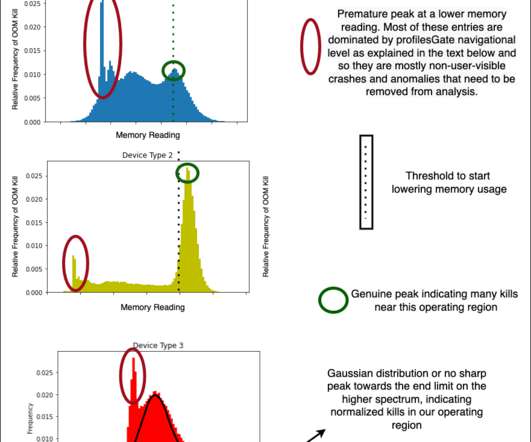
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers.
Radical Ventures and Temasek are co-leading this round, w1ith Air Street Capital, Amadeus Capital Partners and Partech (three previous backers ) also participating, along with a number of individuals prominent in the world of machinelearning and AI. Image Credits: V7 Labs (opens in a new window).
Embedding is usually performed by a machinelearning (ML) model. It should look something like the following: [link] Choose Generate SQL query to open the chat window. With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, data modeling, and dataengineering.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. This solution is implemented using Anthropic Claude 3, available through Amazon Bedrock.
Everybody needs more data and more analytics, with so many different and sometimes often conflicting needs. Dataengineers need batch resources, while data scientists need to quickly onboard ephemeral users. Meanwhile, some workloads hog resources making others miss defined agreements.
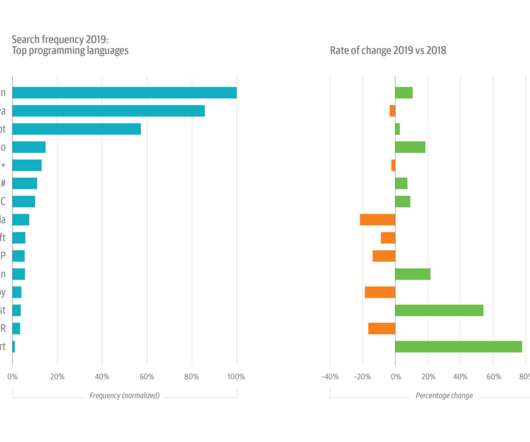
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machinelearning (ML) and artificial intelligence (AI) engineers. The results for data-related topics are both predictable and—there’s no other way to put it—confusing. This follows a 3% drop in 2018.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support AI, BI, ML, and dataengineering on a single platform.” According to Gartner, Inc.
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). Microsoft Certified Azure AI Engineer Associate. Microsoft Certified Azure DataEngineer Associate. Microsoft Certified Azure Administrator ( Associate ).
The organization now has dataengineers, data scientists, and is investing in cutting-edge technologies like quantum computing. “In Another concept is the Immersive Basketball Experience, which uses optical data to provide fans with a life-size augmented reality experience. That was a large move.
We wanted to provide a modern cloud-based platform leveraging the latest in machinelearning, analytics and automation to fight the many cyber attacks businesses face every day. also delivers endpoint detection and response (EDR)-level protection for cloud assets, including Windows and Linux virtual machines and Kubernetes containers.
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). Microsoft Certified Azure AI Engineer Associate. Microsoft Certified Azure DataEngineer Associate. Microsoft Certified Azure Administrator ( Associate ).
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) data processing purposes, e.g. MachineLearning model building and scoring. alias("view_hours")) ) window = Window.partitionBy( "country_code" ).orderBy(col("view_hours").desc())
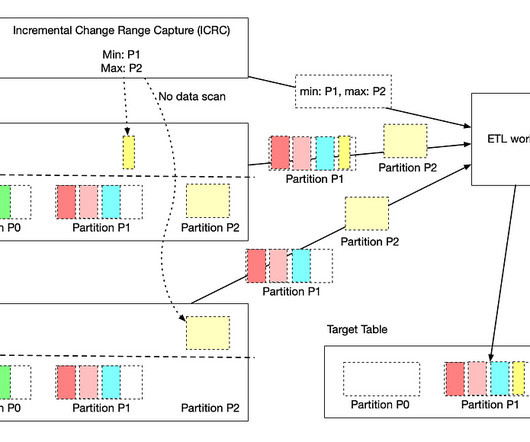
Data Accuracy: Late arriving data causes datasets processed in the past to become incomplete and as a result inaccurate. To compensate for that, ETL workflows often use a lookback window, based on which they reprocess the data in that certain time window. data arrives too late to be useful).
Our data science team uses KSQL to experiment with raw or lifted streams to ultimately deploy new machinelearning models ( using custom user-defined functions ) without writing a single line of Java code. The Confluent Platform is an amazing toolbox, which every architect and dataengineer should know of and utilize.
Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machinelearning—your relational database might not be enough. Building an indexing pipeline at scale with Kafka Connect.
Moreover, it is a period of dynamic adaptation, where documentation and operational protocols will adapt as your data and technology landscape change. This functionality allows our customers to run periodic backups or as needed during business hours and maintenance windows. How does Cloudera support Day 2 operations?
Apache NiFi empowers dataengineers to orchestrate data collection, distribution, and transformation of streaming data with capacities of over 1 billion events per second. . Apache Kafka helps data administrators and streaming app developers to buffer high volumes of streaming data for high scalability.
web development, data analysis. machinelearning , DevOps and system administration, automated-testing, software prototyping, and. This distinguishes Python from domain-specific languages like HTML and CSS limited to web design or SQL created for accessing data in relational database management systems. many others.
for active archive or joining live data with historical data), or machinelearning. Architecture for Real-Time Data Warehousing with Extended Capabilities. cleansing, feature engineering, CDC reconciliation) or for stream analytics (e.g. Data Hub – . Data Hub – .
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional dataengineering and machinelearning life cycles.
Requests for IT resources for data and compute services can’t be delayed three to six months, which is how long the typical procurement cycle, machine configuration, and software installation takes. Delays mean losing to competition or the missing the window of a perfect trial. Related Links: Cloudera Data warehouse (CDW).
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
ETL jobs and staging of data often often require large amounts of resources. ETL is a dataengineering task and should be offloaded onto a scale-out and more cost effective solution. . Similarly, operational data stores take up resources on a data warehouse. They too can be moved to a more cost effective platform.
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). Microsoft Certified Azure AI Engineer Associate. Microsoft Certified Azure DataEngineer Associate. Microsoft Certified Azure Administrator ( Associate ).
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
Learn how world-class tech companies crush the hiring game! Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data.
Learn how world-class tech companies crush the hiring game! Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data.
Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Who's Hiring? Apply here. Try the 30-day free trial!
Learn how world-class tech companies crush the hiring game! Sisu Data is looking for machinelearningengineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content