This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Gen AI-related job listings were particularly common in roles such as data scientists and dataengineers, and in software development. According to October data from Robert Half, AI is the most highly-sought-after skill by tech and IT teams for projects ranging from customer chatbots to predictive maintenance systems.
The two positions are not interchangeable—and misperceptions of their roles can hurt teams and compromise productivity. It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data.
Gartner reported that on average only 54% of AI models move from pilot to production: Many AI models developed never even reach production. These days Data Science is not anymore a new domain by any means. Both the tech and the skills are there: MachineLearning technology is by now easy to use and widely available.
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
Once the province of the data warehouse team, data management has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poordata quality is holding back enterprise AI projects.
When speaking of machinelearning, we typically discuss data preparation or model building. Living in the shadow, this stage, according to the recent study , eats up 25 percent of data scientists time. MLOps lies at the confluence of ML, dataengineering, and DevOps. More time for development of new models.
. “Coming from engineering and machinelearning backgrounds, [Heartex’s founding team] knew what value machinelearning and AI can bring to the organization,” Malyuk told TechCrunch via email. Who can provide the best results other than your own experts?” Heartex’s dashboard.
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. We will learn what it is, why it is important and how Cloudera MachineLearning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
To succeed with real-time AI, data ecosystems need to excel at handling fast-moving streams of events, operational data, and machinelearning models to leverage insights and automate decision-making. It’s also used to deploy machinelearning models, data streaming platforms, and databases.
Data scientists and analysts, dataengineers, and the people who manage them comprise 40% of the audience; developers and their managers, about 22%. Data quality might get worse before it gets better. Comparatively few organizations have created dedicated data quality teams. This is hardly surprising.
Security: Data privacy and security are often afterthoughts during the process of model creation but are critical in production. Kubeflow has its own challenges, too, including difficulties with installation and with integrating its loosely-coupled components, as well as poor documentation.
Businesses and the tech companies that serve them are run on data. At its most challenging, though, data can represent a real headache: there is too much of it, in too many places, and too much of a task to bring it into any kind of order. We look forward to supporting the team through its next phase of growth and expansion.”.
Goldcast, a software developer focused on video marketing, has experimented with a dozen open-source AI models to assist with various tasks, says Lauren Creedon, head of product at the company. Advanced teams will be required to “take a number of these different open-source models and pair them together in a workflow,” Creedon adds.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machinelearning. Besides that, it’s fully compatible with various data ingestion and ETL tools. How dataengineering works in 14 minutes.
Over the years, machinelearning (ML) has come a long way, from its existence as experimental research in a purely academic setting to wide industry adoption as a means for automating solutions to real-world problems. Interpreting high-dimensional MNIST data by visualizing in 3D using PCA for building domain knowledge using TensorFlow.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). You already know the game and how it is played: you’re the coordinator who ties everything together, from the developers and designers to the executives.
The benchmarking revealed that the model performed optimally when processing batches of images, but underperformed when analyzing individual images. Powered by a Llama language model, the assistant initially used carefully engineered prompts created by AI experts. AWS enables us to scale the innovations our customers love most.
Rule-based fraud detection software is being replaced or augmented by machine-learning algorithms that do a better job of recognizing fraud patterns that can be correlated across several data sources. DataOps is required to engineer and prepare the data so that the machinelearning algorithms can be efficient and effective.
Recruiting is one of those things where the Dunning-Kruger effect is the most pronounced: the more you do it, the more you realize how bad you are at it. I think most people in the industry are fed up with bad bulk messages over email/LinkedIn. I think that’s a flawed way to have a tight learning cycle.
Recruiting is one of those things where the Dunning-Kruger effect is the most pronounced: the more you do it, the more you realize how bad you are at it. I think most people in the industry are fed up with bad bulk messages over email/LinkedIn. I think that’s a flawed way to have a tight learning cycle.
web development, data analysis. machinelearning , DevOps and system administration, automated-testing, software prototyping, and. Source: Python Developers Survey 2020 Results. Python uses dynamic typing, which means developers don’t have to declare a variable’s type. many others. How Python is used.
Rau hired a former Apple colleague who approached him and was incentivized by the offer to run the software engineeringteam at the Indianapolis-based Lilly after hearing about the types of projects he could work on. “I P&G is applying AI at scale and automating the machinelearning deployment process, he says.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machinelearning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general.
Natural language processing or NLP is a branch of Artificial Intelligence that gives machines the ability to understand natural human speech. Besides simply looking for email addresses associated with spam, these systems notice slight indications of spam emails, like bad grammar and spelling, urgency, financial language, and so on.
The former extracts and transforms information before loading it into centralized storage while the latter allows for loading data prior to transformation. Developed in 2012 and officially launched in 2014, Snowflake is a cloud-based data platform provided as a SaaS (Software-as-a-Service) solution with a completely new SQL query engine.
Gone are the days of a web app being developed using a common LAMP (Linux, Apache, MySQL, and PHP ) stack. What’s more, this software may run either partly or completely on top of different hardware – from a developer’s computer to a production cloud provider. million monthly active developers sharing 13.7 Docker containers.
The 11th annual survey of Chief Data Officers (CDOs) and Chief Data and Analytics Officers reveals 82 percent of organizations are planning to increase their investments in data modernization in 2023. What’s more, investing in data products, as well as in AI and machinelearning was clearly indicated as a priority.
One of the important steps away from spreadsheets and towards developing your BI capabilities is choosing and implementing specialized technology to support your analytics endeavors. Microsoft Power BI is an interactive data visualization software suite developed by Microsoft that helps businesses aggregate, organize, and analyze data.
WM reveals strengths and weaknesses in workloads that run on Cloudera clusters. Fixed Reports / DataEngineering jobs . Often mission-critical to the various lines of business (risk analytics, platform support, or dataengineering), which hydrate critical data pipelines for downstream consumption.
These challenges can be addressed by intelligent management supported by data analytics and business intelligence (BI) that allow for getting insights from available data and making data-informed decisions to support company development. Comparison between traditional and machinelearning approaches to demand forecasting.
The Cloudera Data Platform comprises a number of ‘data experiences’ each delivering a distinct analytical capability using one or more purposely-built Apache open source projects such as Apache Spark for DataEngineering and Apache HBase for Operational Database workloads.
Forrester Consulting discovered that poor checkout experience and long lines are the third highest reason grocers would skip the line and shop in a different place. Let’s travel overseas and check out how Chinese tech giants have been developing in the same field. Forecasting demand with machinelearning in Walmart.
an also be described as a part of business process management (BPM) that applies data science (with its data mining and machinelearning techniques) to dig into the records of the company’s software, get the understanding of its processes performance, and support optimization activities. Process mining ?an
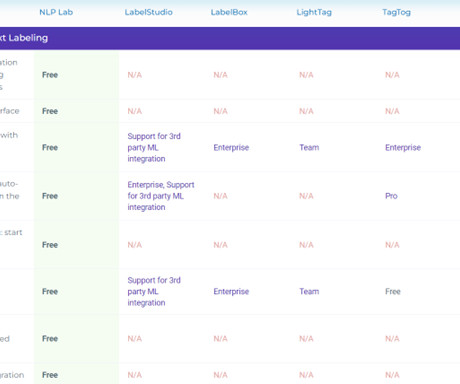
Almost 90% of the machinelearning models encounter delays and never make it into production. Developing a machinelearning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case.
It’s all possible thanks to LLM engineers – people, responsible for building the next generation of smart systems. While we’re chatting with our ChatGPT, Bards (now – Geminis), and Copilots, those models grow, learn, and develop. So, what does it take to be a mighty creator and whisperer of models and data sets?
The Apache Iceberg project continues developing an implementation of Iceberg specification in the form of Java Library. Several compute engines such as Impala, Hive, Spark, and Trino have supported querying data in Iceberg table format by adopting this Java Library provided by the Apache Iceberg project.
Veracity is the measure of how truthful, accurate, and reliable data is and what value it brings. Data can be incomplete, inconsistent, or noizy, decreasing the accuracy of the analytics process. Due to this, data veracity is commonly classified as good, bad, and undefined. Big Data analytics processes and tools.
To optimise our use of data, we need services which store it reliably, provide interfaces for analysis and automate transformation. In developing and configuring these services we must walk a fine line between security and usability. Usability, because business value depends on frictionless access to data. DataEngineering.
Predictive maintenance (PdM) involves constant monitoring of your equipment condition and conducting repairs only when bad trends are detected – but before breakdowns occur. Integration with scheduling software will support your workforce management and help organize shifts of service teams.
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. Inability to handle unstructured data such as audio, video, text documents, and social media posts. Data lake architecture example.
Models are trained on existing data to recognize recurring patterns, often leading to specific results. Related: Gain confidence in your forecasts by hiring top dedicated developers with Mobilunity for unparalleled accuracy. AI vs. MachineLearning vs. Deep Learning: What’s the Difference?
Reputation management systems use natural language processing and machinelearning to read, filter and classify reviews spotted on Google, TripAdvisor, Expedia, Booking.com as well as on your own website. only then pipe data to the targeted warehouse. Data processing in a nutshell and ETL steps outline. Source: DJUBO.
The specific data governance model that an organization adopts depends on various factors, such as its size, complexity, industry, and regulatory environment. Data governance models with pros and cons. Benefits include improved representation, better data, increased efficiency, and shared maintenance. sales specialists).
You can read the details on them in the linked articles, but in short, data warehouses are mostly used to store structured data and enable business intelligence , while data lakes support all types of data and fuel big data analytics and machinelearning. To buy or build?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content