This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Strata Data London will introduce technologies and techniques; showcase use cases; and highlight the importance of ethics, privacy, and security. The growing role of data and machinelearning cuts across domains and industries. Data Science and MachineLearning sessions will cover tools, techniques, and case studies.
The time-travel functionality of the delta format enables AI systems to access historical data versions for training and testing purposes. Modern AI models, particularly large language models, frequently require real-time data processing capabilities. data lake for exploration, data warehouse for BI, separate ML platforms).
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
It was not alive because the business knowledge required to turn data into value was confined to individuals minds, Excel sheets or lost in analog signals. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies.
When speaking of machinelearning, we typically discuss data preparation or model building. Living in the shadow, this stage, according to the recent study , eats up 25 percent of data scientists time. MLOps lies at the confluence of ML, dataengineering, and DevOps. More time for development of new models.
In the previous blog post in this series, we walked through the steps for leveraging Deep Learning in your Cloudera MachineLearning (CML) projects. RAPIDS on the Cloudera Data Platform comes pre-configured with all the necessary libraries and dependencies to bring the power of RAPIDS to your projects. Ingest Data.
Collectively, the agencies also have pilots up and running to test electric buses and IoT sensors scattered throughout the transportation system. Dataengine on wheels’. To mine more data out of a dated infrastructure, Fazal first had to modernize NJ Transit’s stack from the ground up to be geared for business benefit. “I
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, dataengineers and production engineers.
You know the one, the mathematician / statistician / computer scientist / dataengineer / industry expert. Some companies are starting to segregate the responsibilities of the unicorn data scientist into multiple roles (dataengineer, ML engineer, ML architect, visualization developer, etc.),
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. Google, in turn, uses the Google Neural Machine Translation (GNMT) system, powered by ML, reducing error rates by up to 60 percent. The role of a machinelearningengineer in the data science team.
Currently, the demand for data scientists has increased 344% compared to 2013. hence, if you want to interpret and analyze big data using a fundamental understanding of machinelearning and data structure. Because the salary for a data scientist can be over Rs5,50,000 to Rs17,50,000 per annum.
Software testing, especially in large scale projects, is a time intensive process. Test suites may be computationally expensive, compete with each other for available hardware, or simply be so large as to cause considerable delay until their results are available.
Being at the top of data science capabilities, machinelearning and artificial intelligence are buzzing technologies many organizations are eager to adopt. If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering.
The second blog dealt with creating and managing Data Enrichment pipelines. The third video in the series highlighted Reporting and Data Visualization. Specifically, we’ll focus on training MachineLearning (ML) models to forecast ECC part production demand across all of its factories. Data Collection – streaming data.
Why companies are turning to specialized machinelearning tools like MLflow. A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machinelearning (ML) projects. The upcoming 0.9.0
Going from a prototype to production is perilous when it comes to machinelearning: most initiatives fail , and for the few models that are ever deployed, it takes many months to do so. As little as 5% of the code of production machinelearning systems is the model itself. Adapted from Sculley et al.
Engineers are not only the ones bearing helmets and operating on construction sites. Scientists don’t always wear lab coats or handle test tubes. Explaining the difference, especially when they both work with something intangible such as data , is difficult. Data science vs dataengineering.
When we introduced Cloudera DataEngineering (CDE) in the Public Cloud in 2020 it was a culmination of many years of working alongside companies as they deployed Apache Spark based ETL workloads at scale. Each unlocking value in the dataengineering workflows enterprises can start taking advantage of. Usage Patterns.
Databricks is now a top choice for data teams. Its user-friendly, collaborative platform simplifies building data pipelines and machinelearning models. Many data practitioners, myself included, have faced various deployment and resource management strategies. You are ready to run and test your application logic.
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. We will learn what it is, why it is important and how Cloudera MachineLearning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearning models and addition of new features. Principal strategically worked with the Amazon Q Business and QnABot teams to test and improve the Amazon Q Business conversational AI platform.
Data science is an interdisciplinary field that uses a blend of data inference and algorithm development to solve complex analytical problems. An ideal candidate has skills in the 3 fields: mathematics/ statistics/ machinelearning/ programming and business/ domain knowledge. . MachineLearning and Programming.
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by big data and deep learning advancements.
Have you ever wondered about systems based on machinelearning? In those cases, testing takes a backseat. And even if testing is done, it’s done mostly by developers itself. A tester’s role is not clearly portrayed. Testers usually struggle to understand ML-based systems and explore what contributions they can make.
Data scientists are the core of any AI team. They process and analyze data, build machinelearning (ML) models, and draw conclusions to improve ML models already in production. You don’t understand how long you should test your feature and what exactly you should measure,” he says. ML engineer.
The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, dataengineer, data scientist, and system architect. The exam is designed for seasoned and high-achiever data science thought and practice leaders.
Moreover, many need deeper AI-related skills, too, such as for building machinelearning models to serve niche business requirements. He wants data scientists who can build, train, and validate models for use cases, and who can perform exploratory analysis and hypothesis testing. Here’s how IT leaders are coping.
For AI, there’s no universal standard for when data is ‘clean enough.’ But making data too uniform can lead to models that perform well on clean, structured data like their training set, but struggle with real-world messy data, giving you poor performance in production environments.
Most recommended development and deployment platforms for machinelearning projects. Are you getting started with MachineLearning? There’s a forecasted demand for MachineLearning among all kinds of industries. Innovative machinelearning products and services on a trusted platform.
As we depend more on these systems, testing should be a top priority during deployment. AI systems are even more vulnerable as, besides code, they leverage data and algorithms, so you need to test all the components to avoid whammies. When a new system version is ready, the tests ensure it still functions correctly.
Cloudera MachineLearning (CML) is a cloud-native and hybrid-friendly machinelearning platform. It unifies self-service data science and dataengineering in a single, portable service as part of an enterprise data cloud for multi-function analytics on data anywhere. Next Steps.
Most relevant roles for making use of NLP include data scientist , machinelearningengineer, software engineer, data analyst , and software developer. Organizations are looking for professionals who can test and debug, deploy and integrate, and analyze and monitor chatbot services.
Information/data governance architect: These individuals establish and enforce data governance policies and procedures. Analytics/data science architect: These data architects design and implement data architecture supporting advanced analytics and data science applications, including machinelearning and artificial intelligence.
Verify that Synapse has permission to retrieve secrets by testing access from within the Synapse workspace. Azure Synapse Analytics acts as a data warehouse using dedicated SQL pools, but it is also a comprehensive analytics platform designed to handle a wide range of data processing and analytics tasks on structured and unstructured data.
Predictive analytics applies techniques such as statistical modeling, forecasting, and machinelearning to the output of descriptive and diagnostic analytics to make predictions about future outcomes. In business, predictive analytics uses machinelearning, business rules, and algorithms.
Applied Intelligence derives actionable intelligence from our data to optimize massive scale operation of datacenters worldwide. We are developing innovative software in big data analytics, predictive modeling, simulation, machinelearning and automation. Work collaboratively to deliver data in visually impactful ways.
Additionally, the introduction of more CDP operators that integrate with CML (machinelearning) and COD (operation database) are critical for a complete end-to-end orchestration service. With this Technical Preview release, any CDE customer can test drive the new authoring interface by setting up the latest CDE service.
Organization: AWS Price: US$300 How to prepare: Amazon offers free exam guides, sample questions, practice tests, and digital training. Organization: Columbia University Price: Students pay Columbia Engineering’s rate of tuition (US$2,362 per credit). The exam consists of 60 questions and the candidate has 90 minutes to complete it.
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
You’ll be tested on your knowledge of generative models, neural networks, and advanced machinelearning techniques. Upon completion, you will need to pass a knowledge test to earn a badge that you can display on your resume or LinkedIn profile. Cost : $4,000
And whether you’re a novice or an expert, in the field of technology or finance, medicine or retail, machinelearning is revolutionizing your industry and doing it at a rapid pace. You may recognize the ways that MachineLearning can improve your life and work but may not know how to implement it in your own company.
To succeed with real-time AI, data ecosystems need to excel at handling fast-moving streams of events, operational data, and machinelearning models to leverage insights and automate decision-making. It’s also used to deploy machinelearning models, data streaming platforms, and databases.
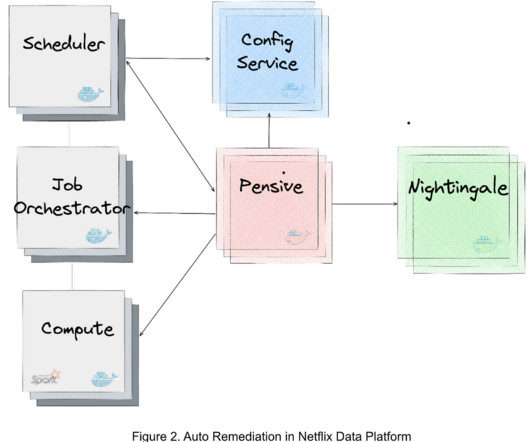
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. John Zhuge , Jun He , Holden Karau , Samarth Jain , Julian Jaffe , Batul Shajapurwala , Michael Sachs , Faisal Siddiqi ).
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content