This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
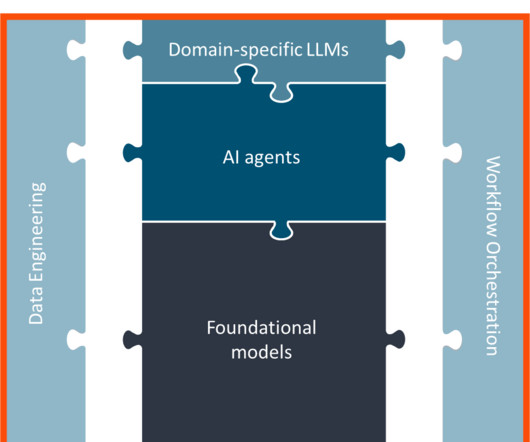
It’s important to understand the differences between a dataengineer and a data scientist. Misunderstanding or not knowing these differences are making teams fail or underperform with big data. I think some of these misconceptions come from the diagrams that are used to describe data scientists and dataengineers.
And part of that success comes from investing in talented IT pros who have the skills necessary to work with your organizations preferred technology platforms, from the database to the cloud. Its widespread use in the enterprise makes it a steady entry on any in-demand skill list. As such, Oracle skills are perennially in-demand skill.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machinelearning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
Read along to learn more! Being ready means understanding why you need that technology and what it is. Universities have been pumping out Data Science grades in rapid pace and the Open Source community made ML technology easy to use and widely available. About being ready So, what does it mean to be ready ?
So what does our data show? First, interest in almost all of the top skills is up: From 2023 to 2024, MachineLearning grew 9.2%; Artificial Intelligence grew 190%; Natural Language Processing grew 39%; Generative AI grew 289%; AI Principles grew 386%; and Prompt Engineering grew 456%. Is that noise or signal?
Hes seeing the need for professionals who can not only navigate the technology itself, but also manage increasing complexities around its surrounding architectures, data sets, infrastructure, applications, and overall security. The speed of the cyber technology revolution is very fast and attackers are always changing behaviors.
s unique about the [chief data officer] role is it sits at the cross-section of data, technology, and analytics,â?? s unique about the role is it sits at the cross-section of data, technology, and analytics. that cover areas of software engineering, infrastructure, cybersecurity, and architecture, for instance.
Strata Data London will introduce technologies and techniques; showcase use cases; and highlight the importance of ethics, privacy, and security. The growing role of data and machinelearning cuts across domains and industries. Data Platforms sessions. Privacy and security.
The survey points to a fundamental misunderstanding among many business leaders regarding the data work needed to deploy most AI tools, says John Armstrong, CTO of Worldly, a supply chain sustainability data insights platform. Gen AI uses huge amounts of energy compared to some other AI tools, he notes.
What is a dataengineer? Dataengineers design, build, and optimize systems for data collection, storage, access, and analytics at scale. They create data pipelines used by data scientists, data-centric applications, and other data consumers. The dataengineer role.
DevOps fueled this shift to the cloud, as it gave decision-makers a sense of control over business-critical applications hosted outside their own data centers. Dataengineers play with tools like ETL/ELT, data warehouses and data lakes, and are well versed in handling static and streaming data sets.
In addition to using cloud for storage, many modern data architectures make use of cloud computing to analyze and manage data. Modern data architectures use APIs to make it easy to expose and share data. AI and machinelearning models. Data integrity. Choose the right tools and technologies.
Changing demographics, fast-evolving technologies, and the globalization of job opportunities make recruiting and holding onto skilled professionals much more difficult. As technology continues to change more rapidly than ever, CIOs who want to build and maintain a team with the right skills will need to do these four things.
In this episode of the Data Show , I spoke with Harish Doddi , co-founder and CEO of Datatron , a startup focused on helping companies deploy and manage machinelearning models. Today’s data science and dataengineering teams work with a variety of machinelearning libraries, data ingestion, and data storage technologies.
When speaking of machinelearning, we typically discuss data preparation or model building. Much less often the technology is mentioned in terms of deployment. Living in the shadow, this stage, according to the recent study , eats up 25 percent of data scientists time. More time for development of new models.
In this short talk, I describe some interesting trends in how data is valued, collected, and shared. Economic value of data. It’s no secret that companies place a lot of value on data and the data pipelines that produce key features. But if data is precious, how do we go about estimating its value?
Machinelearning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. At a high level, Tecton automates the process of building features using real-time data sources.
IT or Information technology is the industry that has registered continuous growth. The Indian information Technology has attained about $194B in 2021 and has a 7% share in GDP growth. Because startups like Zerodha, Ola, and Rupay to large organizations like Infosys, HCL Technologies Ltd, all will grow at a mass scale.
MLOps, or MachineLearning Operations, is a set of practices that combine machinelearning (ML), dataengineering, and DevOps to streamline and automate the end-to-end ML model lifecycle. MLOps is an essential aspect of the current data science workflows.
While collaborating with product developers, Dang and Wang saw that while product developers wanted to use AI, they didn’t have the right tools in which to do it without relying on data scientists. “We They didn’t work with machinelearning extensively, so we decided to build tools for technical non-experts.
The sheer number of options and configurations, not to mention the costs associated with these underlying technologies, is multiplying so quickly that its creating some very real challenges for businesses that have been investing heavily to incorporate AI-powered capabilities into their workflows.
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, dataengineers and production engineers.
This blog focuses on the principles of technology and the most important problems a feature store solves. This becomes more important when a company scales and runs more machinelearning models in production. Please have a look at this blog post on machinelearning serving architectures if you do not know the difference.
In a world fueled by disruptive technologies, no wonder businesses heavily rely on machinelearning. Google, in turn, uses the Google Neural Machine Translation (GNMT) system, powered by ML, reducing error rates by up to 60 percent. But no technology can work efficiently without human experts behind it.
To become a machinelearningengineer, you have to interview. Include technologies, frameworks, and projects on your CV. You have to gain relevant skills from books, courses, conferences, and projects. In an interview, expect that you will be asked technical questions, insight questions, and programming questions.
“The major challenges we see today in the industry are that machinelearning projects tend to have elongated time-to-value and very low access across an organization. “Given these challenges, organizations today need to choose between two flawed approaches when it comes to developing machinelearning. .
Being at the top of data science capabilities, machinelearning and artificial intelligence are buzzing technologies many organizations are eager to adopt. If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering.
You’ve probably heard it more than once: Machinelearning (ML) can take your digital transformation to another level. We recently published a Cloudera Special Edition of Production MachineLearning For Dummies eBook. Let your teams experiment rapidly, fail early and often, continuously learn, and try new things.
Going from a prototype to production is perilous when it comes to machinelearning: most initiatives fail , and for the few models that are ever deployed, it takes many months to do so. As little as 5% of the code of production machinelearning systems is the model itself. Adapted from Sculley et al.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
They’ve also created a relationship with universities, setting up a pipeline of emerging technology-focused interns, who work at the company, gain experience in data science, and then can potentially be hired after they graduate. . And machinelearningengineers are being hired to design and build automated predictive models.
A few months ago, I wrote about the differences between dataengineers and data scientists. An interesting thing happened: the data scientists started pushing back, arguing that they are, in fact, as skilled as dataengineers at dataengineering. I agree; learn as much as you can.
The complexity of streaming datatechnologies – not just streaming video but any kind of streaming data – has created a headache around dealing with that high speed data processing. Accordingly, companies like Spark, Flink have spring up to address this ksqlDB. It’s now raised a £11m / $12.9m
The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearning models and addition of new features. There is a commitment to scale and accelerate development of generative AI technology to meet the growing needs of the enterprise.
But the success of their AI initiatives depends on more than just data and technology — it’s also about having the right people on board. An effective enterprise AI team is a diverse group that encompasses far more than a handful of data scientists and engineers. Data scientists are the core of any AI team.
After walking his executive team through the data hops, flows, integrations, and processing across different ingestion software, databases, and analytical platforms, they were shocked by the complexity of their current data architecture and technology stack. It isn’t easy.
For AI, there’s no universal standard for when data is ‘clean enough.’ A golden dataset of questions paired with a gold standard response can help you quickly benchmark new models as the technology improves. In the generative AI world, the notion of accuracy is much more nebulous.”
If any technology has captured the collective imagination in 2023, it’s generative AI — and businesses are beginning to ramp up hiring for what in some cases are very nascent gen AI skills, turning at times to contract workers to fill gaps, pursue pilots, and round out in-house AI project teams.
What is data science? Data science is a method for gleaning insights from structured and unstructured data using approaches ranging from statistical analysis to machinelearning. Given the current shortage of data science talent, many organizations are building out programs to develop internal data science talent.
Less than a year after its $3 million seed round, San Francisco- and Africa-based fintech Pngme has snapped up another $15 million for its financial data infrastructure play. The company is also describing itself as a machinelearning-as-a-service platform.
It combines genetic information, along with other data like epigenetic changes or proteomics (the study of proteins), to map out how the immune system functions. However, M&A strategy remains to acquire complementary technologies. Immunai has been building a massive dataset of clinical immunological information.
Pete Warden has an ambitious goal: he wants to build machinelearning (ML) applications that can run on a microcontroller for a year using only a hearing aid battery for power. Turning off the radio inverts our models for machinelearning on small devices. And it draws 1.6 And why do we want to build them?
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by big data and deep learning advancements.
That is, products that are laser-focused on one aspect of the data science and machinelearning workflows, in contrast to all-in-one platforms that attempt to solve the entire space of data workflows. Lessons Learned from Data Warehouse and DataEngineering Platforms. A little of both?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content