This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Python Python is a programming language used in several fields, including data analysis, web development, software programming, scientific computing, and for building AI and machinelearning models. Kubernetes Kubernetes is an open-source automation tool that helps companies deploy, scale, and manage containerized applications.
Heartex, a startup that bills itself as an “opensource” platform for data labeling, today announced that it landed $25 million in a Series A funding round led by Redpoint Ventures. This helps to monitor label quality and — ideally — to fix problems before they impact training data.
In 2019 alone the Data Scientist job postings on Indeed rose by 256% [2]. Universities have been pumping out Data Science grades in rapid pace and the OpenSource community made ML technology easy to use and widely available. Data Science profiles are more abundant in the market than ever before.
In this short talk, I describe some interesting trends in how data is valued, collected, and shared. Economic value of data. It’s no secret that companies place a lot of value on data and the data pipelines that produce key features. But if data is precious, how do we go about estimating its value?
Iterative , an open-source startup that is building an enterprise AI platform to help companies operationalize their models, today announced that it has raised a $20 million Series A round led by 468 Capital and Mesosphere co-founder Florian Leibert. He noted that the industry has changed quite a bit since then. ”
Machinelearning can provide companies with a competitive advantage by using the data they’re collecting — for example, purchasing patterns — to generate predictions that power revenue-generating products (e.g. At a high level, Tecton automates the process of building features using real-time datasources.
In addition to using cloud for storage, many modern data architectures make use of cloud computing to analyze and manage data. Modern data architectures use APIs to make it easy to expose and share data. AI and machinelearning models. Application programming interfaces. Container orchestration.
As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machinelearning. Privacy and security.
Union.ai , a startup emerging from stealth with a commercial version of the opensource AI orchestration platform Flyte, today announced that it raised $10 million in a round contributed by NEA and “select” angel investors. “Data science is very academic, which directly affects machinelearning.
Building a scalable, reliable and performant machinelearning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machinelearning framework. Impedance mismatch between data scientists, dataengineers and production engineers.
When DBeaver creator Serge Rider began building an opensource database admin tool in 2013, he probably had no idea that 10 years later, it would boast more than 8 million users. So actually anyone who needs to work with data can use DBeaver,” she told TechCrunch.
“The major challenges we see today in the industry are that machinelearning projects tend to have elongated time-to-value and very low access across an organization. “Given these challenges, organizations today need to choose between two flawed approaches when it comes to developing machinelearning. .
What is data science? Data science is a method for gleaning insights from structured and unstructured data using approaches ranging from statistical analysis to machinelearning. Organizations need data scientists and analysts with expertise in techniques for analyzing data.
Principal also used the AWS opensource repository Lex Web UI to build a frontend chat interface with Principal branding. The flexible, scalable nature of AWS services makes it straightforward to continually refine the platform through improvements to the machinelearning models and addition of new features.
Being at the top of data science capabilities, machinelearning and artificial intelligence are buzzing technologies many organizations are eager to adopt. If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering.
RudderStack , a platform that focuses on helping businesses build their customer data platforms to improve their analytics and marketing efforts, today announced that it has raised a $56 million Series B round led by Insight Partners, with previous investors Kleiner Perkins and S28 Capital also participating.
Going from a prototype to production is perilous when it comes to machinelearning: most initiatives fail , and for the few models that are ever deployed, it takes many months to do so. As little as 5% of the code of production machinelearning systems is the model itself. Adapted from Sculley et al.
Most relevant roles for making use of NLP include data scientist , machinelearningengineer, software engineer, data analyst , and software developer. They’re also seeking skills around APIs, deep learning, machinelearning, natural language processing, dialog management, and text preprocessing.
A summary of sessions at the first DataEngineeringOpen Forum at Netflix on April 18th, 2024 The DataEngineeringOpen Forum at Netflix on April 18th, 2024. Netflix is not the only place where dataengineers are solving challenging problems with creative solutions.
Breaking down silos has been a drumbeat of data professionals since Hadoop, but this SAP <-> Databricks initiative may help to solve one of the more intractable dataengineering problems out there. SAP has a large, critical data footprint in many large enterprises. However, SAP has an opaque data model.
Predictive analytics applies techniques such as statistical modeling, forecasting, and machinelearning to the output of descriptive and diagnostic analytics to make predictions about future outcomes. In business, predictive analytics uses machinelearning, business rules, and algorithms. Data analytics tools.
Goldcast, a software developer focused on video marketing, has experimented with a dozen open-source AI models to assist with various tasks, says Lauren Creedon, head of product at the company. The company isn’t building its own discrete AI models but is instead harnessing the power of these open-source AIs.
Machinelearning (ML) history can be traced back to the 1950s, when the first neural networks and ML algorithms appeared. Analysis of more than 16.000 papers on data science by MIT technologies shows the exponential growth of machinelearning during the last 20 years pumped by big data and deep learning advancements.
The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, dataengineer, data scientist, and system architect. The exam is designed for seasoned and high-achiever data science thought and practice leaders.
That is, products that are laser-focused on one aspect of the data science and machinelearning workflows, in contrast to all-in-one platforms that attempt to solve the entire space of data workflows. This is an open question, but we’re putting our money on best-of-breed products. A little of both?
Machinelearning is now being used to solve many real-time problems. One big use case is with sensor data. Corporations now use this type of data to notify consumers and employees in real-time. With this example as inspiration, I decided to build off of sensor data and serve results from a model in real-time.
Candidates are required to complete a minimum of 12 credits, including four required courses: Algorithms for Data Science, Probability and Statistics for Data Science, MachineLearning for Data Science, and Exploratory Data Analysis and Visualization.
Cloudera MachineLearning (CML) is a cloud-native and hybrid-friendly machinelearning platform. It unifies self-service data science and dataengineering in a single, portable service as part of an enterprise data cloud for multi-function analytics on data anywhere. References.
Observability tools to capture and analyze IT tool data aren’t new — and these days, they’re raising a respectable amount of capital. Monte Carlo , whose platform uses machinelearning to infer what data looks like and assess its impact, became a unicorn last May with $135 million in funding.
You know Spark, the free and opensource complement to Apache Hadoop that gives enterprises better ability to field fast, unified applications that combine multiple workloads, including streaming over all your data. They also launched a plan to train over a million data scientists and dataengineers on Spark.
In financial services, another highly regulated, data-intensive industry, some 80 percent of industry experts say artificial intelligence is helping to reduce fraud. Machinelearning algorithms enable fraud detection systems to distinguish between legitimate and fraudulent behaviors.
Many of the open models can deliver acceptable performance when running on laptops and phones; some are even targeted at embedded devices. So what does our data show? Searches for prompt engineering grew sharply in 2023 but appeared to decline slightly in 2024. Theres a different take on the future of prompt engineering.
In the finance industry, software engineers are often tasked with assisting in the technical front-end strategy, writing code, contributing to open-source projects, and helping the company deliver customer-facing services. Dataengineer.
In the finance industry, software engineers are often tasked with assisting in the technical front-end strategy, writing code, contributing to open-source projects, and helping the company deliver customer-facing services. Dataengineer.
In a recent O’Reilly survey , we found that the skills gap remains one of the key challenges holding back the adoption of machinelearning. The demand for data skills (“the sexiest job of the 21st century”) hasn’t dissipated. Continuing investments in (emerging) data technologies. Burgeoning IoT technologies.
In their effort to reduce their technology spend, some organizations that leverage opensource projects for advanced analytics often consider either building and maintaining their own runtime with the required data processing engines or retaining older, now obsolete, versions of legacy Cloudera runtimes (CDH or HDP).
Radical Ventures and Temasek are co-leading this round, w1ith Air Street Capital, Amadeus Capital Partners and Partech (three previous backers ) also participating, along with a number of individuals prominent in the world of machinelearning and AI. “This is where V7’s AI DataEngine shines.
Data scientists, dataengineers, AI and ML developers, and other data professionals need to live ethical values, not just talk about them. The hard thing about being an ethical data scientist isn’t understanding ethics. It’s doing good data science. It’s the junction between ethical ideas and practice.
We use it as a datasource for our annual platform analysis , and we’re using it as the basis for this report, where we take a close look at the most-used and most-searched topics in machinelearning (ML) and artificial intelligence (AI) on O’Reilly [1]. that support unsupervised learning.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support AI, BI, ML, and dataengineering on a single platform.” According to Gartner, Inc.
To assess the state of adoption of machinelearning (ML) and AI, we recently conducted a survey that garnered more than 11,000 respondents. Novices and non-experts have also benefited from easy-to-use, opensource libraries for machinelearning. had a national surplus of people with data science skills.
A general LLM won’t be calibrated for that, but you can recalibrate it—a process known as fine-tuning—to your own data. Fine-tuning applies to both hosted cloud LLMs and opensource LLM models you run yourself, so this level of ‘shaping’ doesn’t commit you to one approach.
Rule-based fraud detection software is being replaced or augmented by machine-learning algorithms that do a better job of recognizing fraud patterns that can be correlated across several datasources. This will require another product for data governance. This is colloquially called data wrangling.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





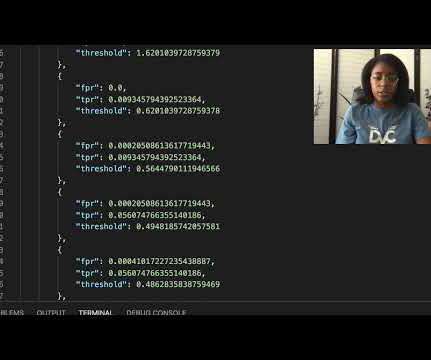































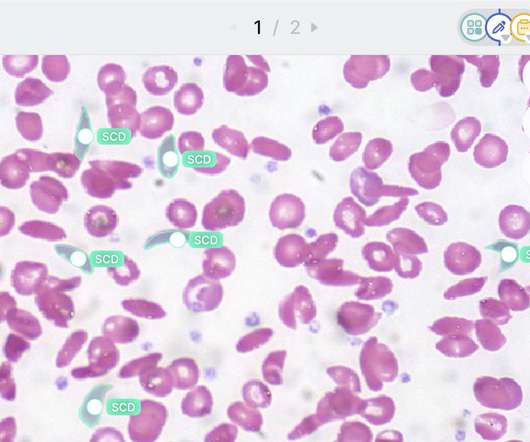















Let's personalize your content