This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
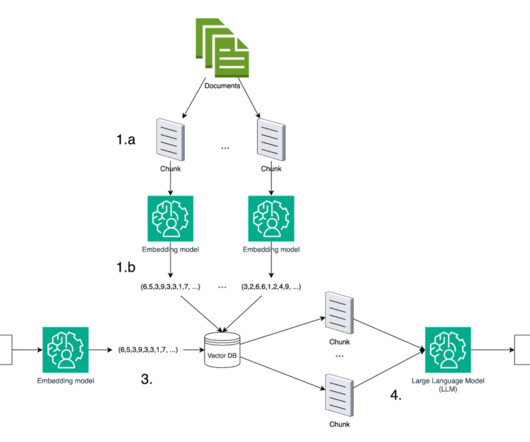
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
As Principal grew, its internal support knowledgebase considerably expanded. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
The process goes beyond storing and retrieving information and includes intelligently managing context, understanding the relevance of past interactions, and dynamically adapting the AI’s responses based on an evolving knowledgebase.
These logs can be used to test the accuracy and enhance the context by providing more details in the knowledgebase. With the aid of a tool like this, you can create automated solutions that are accessible to nontechnical users, empowering them to interact with data more efficiently. About the Author Rajendra Choudhary is a Sr.
With App Studio, a user simply describes the application they want, what they want it to do, and the data sources they want to integrate with, and App Studio builds an application in minutes that could have taken a professional developer days to build a similar application from scratch. Read more about MemoryDB in the News Blog.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
This method involves using data retrieved from a knowledgebase to assist the LLM in generating its response. Additionally it should help to reduce the chance of hallucinations, by restricting the information in responses to information found in the knowledgebase.
Founding AI ecosystem partners | NVIDIA, AWS, Pinecone NVIDIA | Specialized Hardware Highlights: Currently, NVIDIA GPUs are already available in Cloudera Data Platform (CDP), allowing Cloudera customers to get eight times the performance on dataengineering workloads at less than 50 percent incremental cost relative to modern CPU-only alternatives.
This example shows knowledge articles, Service Catalog items, and incidents. When you use a query, you can specify multiple knowledgebases, including private knowledgebases. Lakshmi Dogiparti is a is a Software Development Engineer at Amazon Web Services.
To use this powerful feature you must be running BGP between at least one device in your network and the Kentik DataEngine (KDE). Details on how to do that can be found in KnowledgeBase topics BGP Overview and Router BGP Configuration. Since this feature uses one-hour slices of data, the minimum Time Range is two days.
As a Google Cloud Partner , in this instance we refer to text-based Gemini 1.5 Pro automates and enhances requirements engineering, by using a retrieval system that fetches relevant document chunks from a large knowledgebase, as well as an LLM that produces answers to prompts using the information from those chunks.
This allows non-technical stakeholders from product, marketing, sales, management, and executives to understand the data and gain insight in terms that are relevant to their roles. To learn more about Custom Dimensions, check out our KnowledgeBase article. For more information, check out our Dashboards KnowledgeBase article.
Peering with Kentik is safer than the peering you’re already doing for Internet traffic delivery, and it allows our dataengine to combine your NetFlow records with time-correlated BGP data, creating a unified datastore that enhances your ability to extract operational, security, and business insights. SaaS as a Safe Solution.
Limited community presence, relying more on direct support and knowledgebases. Fivetran – A fully managed solution often comes with high costs, especially for large-scale data pipelines and complex data transformations. Suitable for dataengineers and developers.
dataengineering pipelines, machine learning models). Validation alerts are powered by the Cloudera Diagnostic Bundle built inside of Cloudera Manager and its comprehensive collection of both environmental and product-level diagnostics.
To see the full variety of the calls that are available you can refer to our KnowledgeBase, which covers both Admin APIs and the Query API. This allows our customers to skip a lot of the heavy lifting that would otherwise be involved in pulling in their Kentik data alongside the other data that they are already graphing.
This information is turned into flow data and sent over an SSL encrypted channel to the Kentik DataEngine (KDE), from which it is queryable in Kentik Detect. For a deeper dive, see our KnowledgeBase article on Host Configuration.).
The flow metadata stored in the Kentik DataEngine (our backend) isn’t simply what comes to us from network devices; instead it is enhanced with a variety of derived or externally acquired information (e.g. In the meantime, for more details see the Interface Classification article in the Kentik KnowledgeBase.
Kentik Detect customers use alerts to monitor various metrics in the data that is ingested into the Kentik DataEngine (KDE), including information on devices, interfaces, IP/CIDR, Geo, ASN, and ports. It focuses on using PHP to parse the JSON and to write the desired values to a human-readable file on a web server.
Kentik Detect uses SQL as the query language, but the underlying data is stored in the Kentik DataEngine (KDE), a custom, distributed, column-store database. See Subquery Function Syntax in the Kentik KnowledgeBase for more information. Return the count of bytes. FROM all_devices. WHERE ctimestamp > 3600.
To briefly review, Interface Classification enables an organization to quickly and efficiently assign a Connectivity Type and Network Boundary value to every interface in the network, and to store those values in the Kentik DataEngine (KDE) records of each flow that is ingested by Kentik Detect.
Roles Responsibilities Project Lead Monitoring the system’s design, selecting algorithms and architecture Product Owner/ Business Analyst Ensuring that solutions meet business objectives and stakeholders’ needs Project Manager Managing deadlines, software engineers workload, and effective collaboration DevOps Engineer Making the infrastructure (..)
Under the hood, Kentik Detect is powered by Kentik DataEngine (KDE), a high-availability, massively-scalable, multi-tenant distributed database. Applying Multi-level Queues in Multi-tenant Databases. These tables are each divided into logical “slices” of one minute (for Full dataseries) or one hour (for Fast dataseries).
Using the Data Explorer API for Added-value Content. Kentik Detect™ is a powerful solution that ingests and stores large volumes of network data on a per device, per customer basis. The data is stored in the Kentik DataEngine™, a timeseries database that unifies flow records (NetFlow v5/9, IPFIX, sFlow) with BGP, Geo-IP, and SNMP.
Alation is an industry recognized provider whose data management solutions focus primarily on fueling self-service analytics, data governance, and cloud data migration. Alation supports active metadata management with its Data Governance App and Data Catalog tools. Create a metadata directory.
There’s also a vast online knowledgebase with descriptions, tips, how-to guides , and best practices. Here’s a collection of guided training options for those who need a deeper knowledge of the platform. Detailed documentation. Certification. Third-party education.
This post was co-written with Vishal Singh, DataEngineering Leader at Data & Analytics team of GoDaddy Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) in these solutions has become increasingly popular.
In general, a data infrastructure is a system of hardware and software tools used to collect, store, transfer, prepare, analyze, and visualize data. Check our article on dataengineering to get a detailed understanding of the data pipeline and its components. Big data infrastructure in a nutshell.
Allowing organizations to inject knowledge-based decisions services that are traceable, auditable and explainable into the process fabric of their operations. AI-enabled dataengines will provide insight about what processes can be redesigned and/or automated. Lloyd Dugan BPM.com [link].
Large enterprises have long used knowledge graphs to better understand underlying relationships between data points, but these graphs are difficult to build and maintain, requiring effort on the part of developers, dataengineers, and subject matter experts who know what the data actually means.
Solution Patterns from Clouderas Professional Services provide a blueprint for scaling AI by encompassing all aspects of the AI lifecycle, from dataengineering and model deployment to real-time inference and monitoring. This flexibility allows you to select the best models for your specific use cases.
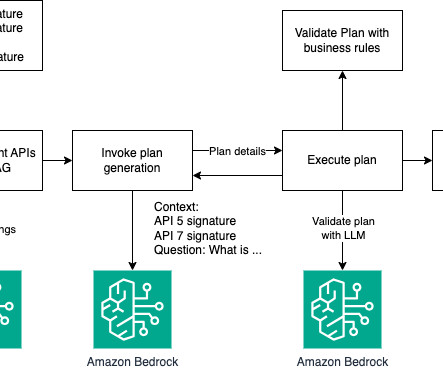
Amazon Bedrock Agents and Amazon Bedrock KnowledgeBases as native CrewAI Tools Amazon Bedrock Agents offers you the ability to build and configure autonomous agents in a fully managed and serverless manner on Amazon Bedrock. A US Army veteran, Tony brings a diverse background in healthcare, dataengineering, and AI.
Traditionally, answering these queries required the expertise of business intelligence specialists and dataengineers, often resulting in time-consuming processes and potential bottlenecks. or How do prescription trends for [specific drug] vary across different regions?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content