This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
A cloud architect has a profound understanding of storage, servers, analytics, and many more. IoT Architect. Learning about IoT or the Internet of Things can be significant if you want to learn one of the most popular IT skills. Currently, the IoT architects are paid up to Rs20,00,000 per annum. Big DataEngineer.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
When the formation of Hitachi Vantara was announced, it was clear that combining Hitachi’s broad expertise in OT (operational technology) with its proven IT product innovations and solutions, would give customers a powerful, collaborative partner, unlike any other company, to address the burgeoning IoT market.
The demand for data skills (“the sexiest job of the 21st century”) hasn’t dissipated. LinkedIn recently found that demand for data scientists in the US is “off the charts,” and our survey indicated that the demand for data scientists and dataengineers is strong not just in the US but globally.
There’s a high demand for software engineers, dataengineers, business analysts and data scientists, as finance companies move to build in-house tools and services for customers.
Titanium Intelligent Solutions, a global SaaS IoT organization, even saved one customer over 15% in energy costs across 50 distribution centers , thanks in large part to AI. Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal.
Few if any data management frameworks are business focused, to not only promote efficient use of data and allocation of resources, but also to curate the data to understand the meaning of the data as well as the technologies that are applied to the data so that dataengineers can move and transform the essential data that data consumers need.
With the uprise of internet-of-things (IoT) devices, overall data volume increase, and engineering advancements in this field led to new ways of collecting, processing, and analysing data. As a result, it became possible to provide real-time analytics by processing streamed data. Sales region: Northern California.
Second, since IaaS deployments replicated the on-premises HDFS storage model, they resulted in the same data replication overhead in the cloud (typical 3x), something that could have mostly been avoided by leveraging modern object store. Storage costs. using list pricing of $0.72/hour hour using a r5d.4xlarge
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. Impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
It means you must collect transactional data and move it from the database that supports transactions to another system that can handle large volumes of data. And, as is common, to transform it before loading to another storage system. But how do you move data? The simplest illustration for a data pipeline.
As more and more enterprises drive value from container platforms, infrastructure-as-code solutions, software-defined networking, storage, continuous integration/delivery, and AI, they need people and skills on board with ever more niche expertise and deep technological understanding. IoTEngineer.
In the private sector, excluding highly regulated industries like financial services, the migration to the public cloud was the answer to most IT modernization woes, especially those around data, analytics, and storage.
Managing the collection of all the data from all factories in the manufacturing process is a significant undertaking that presents a few challenges: Difficulty assessing the volume and variety of IoTdata: Many factories utilize both modern and legacy manufacturing assets and devices from multiple vendors, with various protocols and data formats.
Data curation will be a focus to understand the meaning of the data as well as the technologies that are applied to the data so that dataengineers can move and transform the essential data that data consumers need to power the organization.
Hybrid clouds must bond together the two clouds through fundamental technology, which will enable the transfer of data and applications. REAN Cloud is a global cloud systems integrator, managed services provider and solutions developer of cloud-native applications across big data, machine learning and emerging internet of things (IoT) spaces.
The requirement was to centralize and archive the data collected from these endpoint devices while keeping with regulation requirements. Hitachi Vantara provided HCP object storage to replace traditional storage for ease of access, search and index, privacy regulations and hybrid cloud.
Taking action to leverage your data is a multi-step journey, outlined below: First, you have to recognize that sticking to the status quo is not an option. Your data demands, like your data itself, are outpacing your dataengineering methods and teams.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. Virtually, Hadoop puts no limits on the storage capacity. What is Hadoop.
Sometimes, a data or business analyst is employed to interpret available data, or a part-time dataengineer is involved to manage the data architecture and customize the purchased software. At this stage, data is siloed, not accessible for most employees, and decisions are mostly not data-driven.
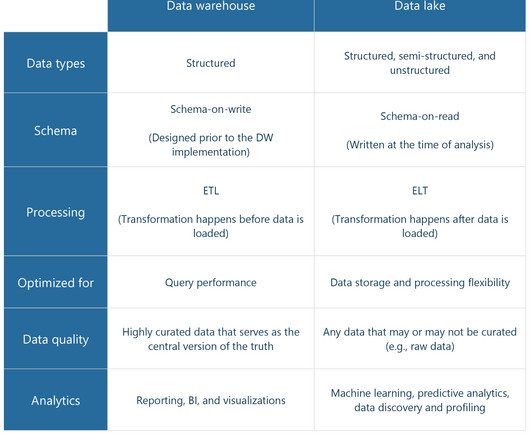
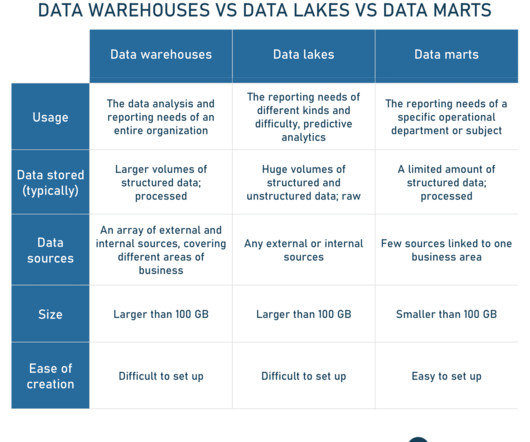
Similar to humans companies generate and collect tons of data about the past. And this data can be used to support decision making. While our brain is both the processor and the storage, companies need multiple tools to work with data. And one of the most important ones is a data warehouse. Subject-oriented data.
InsureApp is another company that contextualizes behavior and translates it into personalized insurance by combining and interpreting data from smartphone sensors and IoT devices. You can start investing in data infrastructure and analytical pipelines to automate data collection and analysis mechanisms.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing.
Key zones of an Enterprise Data Lake Architecture typically include ingestion zone, storage zone, processing zone, analytics zone, and governance zone. Ingestion zone is where data is collected from various sources and ingested into the data lake. Storage zone is where the raw data is stored in its original format.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
Data Factory : A data integration tool with 150+ connectors to cloud and on-premises data sources. Synapse DataEngineering : A Spark authoring experience that includes instant start with live pools and collaboration features. It triggers notifications and actions when it finds specified patterns in the data.
Today, the costs of sensors, data capture, and information storage have significantly decreased and are one tenth of what they were 10 years ago, leading to the proliferation of data that enables advanced analytics-driving efficiencies. Explore operational efficiencies with our Federated Learning Machine Learning Prototype.
A data lakehouse , as the name suggests, is a new data architecture that merges data warehouse and data lake into a single whole, aiming at addressing each one’s limitations. In a nutshell, the lakehouse system leverages low-cost storage to keep large volumes of data in its raw formats just like data lakes.
Data is a valuable source that needs management. If your business generates tons of data and you’re looking for ways to organize it for storage and further use, you’re at the right place. Read the article to learn what components data management consists of and how to implement a data management strategy in your business.
These systems can be hosted on-premises, in the cloud, and on IoT devices, etc. With the right data integration strategy, companies can consolidate the needed data into a single place and ensure its integrity and quality for better and more reliable insights. How data consolidation works. Middleware data integration.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. In other words, Kafka can serve as a messaging system, commit log, data integration tool, and stream processing platform. cloud data warehouses — for example, Snowflake , Google BigQuery, and Amazon Redshift.
Following the Azure learning path under Microsoft, there are certifications available that allow you to demonstrate your expertise in Microsoft cloud-related technologies and advance your career by earning one of the new Azure role-based certifications or an Azure-related certification in platform, development, or data. Azure Fundamentals.
A shared data catalog and data context including definitions, permissions, and governance, offered as part of our Cloudera Altus platform to simplify configurations in the cloud, makes it easy to consolidate all data into a single, well-defined, persistent repository in object storage.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general. Stream processing.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
Time-to-solution expectations for new data-driven solutions are even faster – With better data-driven solutions often the competitive battlefield, victory goes to the swift. Data Is The Wisest Bet for 2020.
In 2010, they launched Windows Azure, the PaaS, positioning it as an alternative to Google App Engine and Amazon EC2. They provided a few services like computing, Azure Bob storage, SQL Azure, and Azure Service Bus. The new structure enabled the opportunity to meet such customer needs in computing as storage, networking, and services.
For many enterprises, applications represent only a portion of a much larger reliability mandate, including offices, robotics, hardware, and IoT, and the complex networking, data, and observability infrastructure required to facilitate such a mandate. This is no small feat and can lead to significant overhead and resource consumption.
Such an approach requires a great deal of investment since a whole ecosystem has to be created, including IoT sensors installation, acquiring specialized software, creating and maintaining machine learning (ML) models, engaging IT and data science specialists , and so on. Collecting data from connected sensors and external sources.
Decentralized data ownership by domain. Zhamak Dehghani divides the data into the “two planes”: The operational plane presents the data from the source systems where it originates — for example, front-desk apps, IoT systems , point of sales systems , etc. And it’s their job to guarantee data quality.
Both data integration and ingestion require building data pipelines — series of automated operations to move data from one system to another. For this task, you need a dedicated specialist — a dataengineer or ETL developer. Dataengineering explained in 14 minutes. Find sources of relevant data.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content