This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
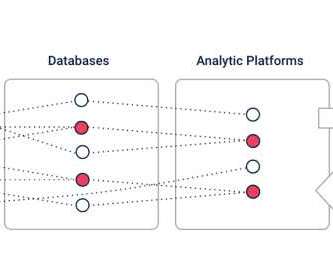
Shared data assets, such as product catalogs, fiscal calendar dimensions, and KPI definitions, require a common vocabulary to help avoid disputes during analysis. Curate the data. Invest in core functions that performdata curation such as modeling important relationships, cleansing raw data, and curating key dimensions and measures.
Collectively, the agencies also have pilots up and running to test electric buses and IoT sensors scattered throughout the transportation system. Dataengine on wheels’. To mine more data out of a dated infrastructure, Fazal first had to modernize NJ Transit’s stack from the ground up to be geared for business benefit.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
IoT Architect. Learning about IoT or the Internet of Things can be significant if you want to learn one of the most popular IT skills. It is the technology that helps in transforming current technology in terms of communication and data sharing. Currently, the IoT architects are paid up to Rs20,00,000 per annum.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
In the annual Porsche Carrera Cup Brasil, data is essential to keep drivers safe and sustain optimal performance of race cars. Until recently, getting at and analyzing that essential data was a laborious affair that could take hours, and only once the race was over. The device plugs into CAN bus cables by induction.
German healthcare company Fresenius Medical Care, which specializes in providing kidney dialysis services, is using a combination of near real-time IoTdata and clinical data to predict one of the most common complications of the procedure.
For data warehouses, it can be a wide column analytical table. Many companies reach a point where the rate of complexity exceeds the ability of dataengineers and architects to support the data change management speed required for the business. About George Trujillo: George is principal data strategist at DataStax.
I have seen solutions based around InfoSphere Streams that are clearly the right approach for high performance solutions where reliability is critical for mission support. Spark is still new and frankly there have been issues with performance from time to time. First, it dramatically improves the performance of data dependent apps.
Across industries, operations managers understand that “digital” has indeed unlocked a new wave of performance improvement opportunities. New technologies make it possible to leverage the wealth of data locked in production equipment and improve its reliability, performance, and flexibility.
It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in dataengineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development. MLOps lies at the confluence of ML, dataengineering, and DevOps.
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
With the uprise of internet-of-things (IoT) devices, overall data volume increase, and engineering advancements in this field led to new ways of collecting, processing, and analysing data. As a result, it became possible to provide real-time analytics by processing streamed data.
Titanium Intelligent Solutions, a global SaaS IoT organization, even saved one customer over 15% in energy costs across 50 distribution centers , thanks in large part to AI. An enterprise data ecosystem architected to optimize data flowing in both directions. Learn how DataStax enables real-time AI.
Looking into Network Monitoring in an IoT enabled network. As part of the movement, organizations are also looking to benefit from the Internet of Things (IoT). IoT infrastructure represents a broad diversity of technology. So, how can digital businesses cope with these challenges without giving up on IoT?
And planning, in turn, relies on understanding of current performance, past trends, existing risks, and possible future scenarios. The data that your procurement management software generates can help you analyze potential suppliers’ performance by comparing their KPIs, prices, compliance, and other variables.
When the formation of Hitachi Vantara was announced, it was clear that combining Hitachi’s broad expertise in OT (operational technology) with its proven IT product innovations and solutions, would give customers a powerful, collaborative partner, unlike any other company, to address the burgeoning IoT market.
REAN Cloud is a global cloud systems integrator, managed services provider and solutions developer of cloud-native applications across big data, machine learning and emerging internet of things (IoT) spaces. This April, 47Lining, announced its Amazon Web Services (AWS) Industrial Time Series Data Connector Quick Start.
That is accomplished by delivering most technical use cases through a primarily container-based CDP services (CDP services offer a distinct environment for separate technical use cases e.g., data streaming, dataengineering, data warehousing etc.) Fine-grained Data Access Control. Capability. CDP Public Cloud.
Imagine you’re a dataengineer at a Fortune 1000 company. You use data virtualization to create data views, configure security, and share data. One: Streaming Data Virtualization. All this data is in motion. But first-generation data virtualization tools are designed for data at rest.
Besides running daily operations, you may evaluate your performance. It means you must collect transactional data and move it from the database that supports transactions to another system that can handle large volumes of data. Imagine that you’re gathering various data that shows how people engage with your brand.
Managing the collection of all the data from all factories in the manufacturing process is a significant undertaking that presents a few challenges: Difficulty assessing the volume and variety of IoTdata: Many factories utilize both modern and legacy manufacturing assets and devices from multiple vendors, with various protocols and data formats.
Sometimes, a data or business analyst is employed to interpret available data, or a part-time dataengineer is involved to manage the data architecture and customize the purchased software. At this stage, data is siloed, not accessible for most employees, and decisions are mostly not data-driven.
Ronald van Loon has been recognized among the top 10 global influencers in Big Data, analytics, IoT, BI, and data science. As the director of Advertisement, he works to help data-driven businesses be more successful. He regularly publishes articles on Big Data and Analytics on Forbes. Ronald van Loon. Bernard Marr.
City of Istanbul Governorship: Safe, Smart Campus The challenge was to secure the governorship campus and include multiple existing video and IoT systems. They used a time series data base (TSDB) which is optimized for measuring change over time and makes time series data very different than other data workloads.
In most cases, manufacturers can access significant amounts of historical and real-time data from machines to make reliable use cases, but it takes a change in mindset because many collected this data but did not look at it until it was too late. The use of IoT sensors means manufacturers can access real-time data now.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
Case study: leveraging AgileEngine as a data solutions vendor 11. Key takeaways Any organization that operates online and collects data can benefit from a data analytics consultancy, from blockchain and IoT, to healthcare and financial services The market for data analytics globally was valued at $112.8
To democratize, collaborate, and operationalize data science and machine learning (ML) across your entire organization, you need to make data science a team sport. TIBCO can help empower everyone from data scientists and citizen data scientists to dataengineers to business users to developers with flexible and extensible tools.
This is due to an improvement in plant uptime, supported by predictive maintenance applications, coupled with optimization of the fuel consumption that powers these plants, as well as fine-grained performance monitoring that eliminates over-production. . These include recruitment, training, performance management, and employee retention.
This “revolution” stems from breakthrough advancements in artificial intelligence, robotics, and the Internet of Things (IoT). Python is unarguably the most broadly used programming language throughout the data science community. IoT Empowered Assembly Lines: Predictive Maintenance. Native Python Support for Snowpark.
To understand Big Data, you need to get acquainted with its attributes known as the four V’s: Volume is what hides in the “big” part of Big Data. This relates to terabytes to petabytes of information coming from a range of sources such as IoT devices, social media, text files, business transactions, etc.
After trying all options existing on the market — from messaging systems to ETL tools — in-house dataengineers decided to design a totally new solution for metrics monitoring and user activity tracking which would handle billions of messages a day. High performance. How Apache Kafka streams relate to Franz Kafka’s books.
The framework provides a way to divide a huge data collection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster. As a result, a Big Data analytics task is split up, with each machine performing its own little part in parallel. No real-time data processing.
Data Lineage : Data constituents (including Data Consumers, Producers and Data Stewards) should be able to track lineage of data as it flows from data producers to data consumers but also, when applicable, as data flows between different data processing stages within the boundaries of a given data product.
Thankfully, it’s now a game for new technologies and leveraging structured and unstructured data like no other. The future of the global supply chain market lies in IoT, integrated solutions, data, and mobility. Connected logistics devices generate a massive amount of data. The route to the future.
Well-designed data management processes can yield big benefits for your business — such as follows. If properly organized, data management minimizes data movement, helps uncover performance breakdowns, and enables users to have all the necessary information a click away. Snowflake data management processes.
Veteran truck drivers believe that “ If handled and driven correctly and the maintenance and inspections are performed religiously, you may never suffer a breakdown. ”. Data is gathered from connected sensors and analyzed so that predictions of possible failures can be generated.
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Data availability.
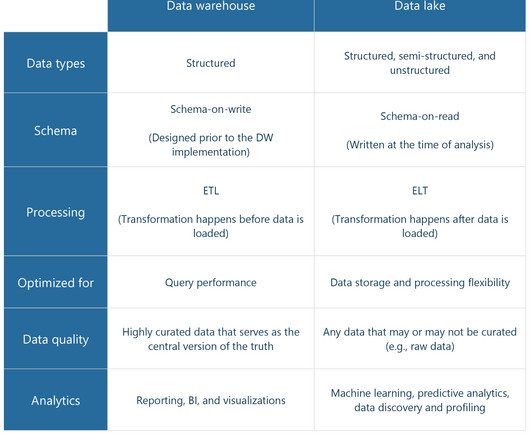
Key zones of an Enterprise Data Lake Architecture typically include ingestion zone, storage zone, processing zone, analytics zone, and governance zone. Ingestion zone is where data is collected from various sources and ingested into the data lake. Storage zone is where the raw data is stored in its original format.
Intended for individuals who perform intricate networking tasks. AWS Certified Big Data – Speciality. For individuals who perform complex Big Data analyses and have at least two years of experience using AWS. Azure DataEngineer Associate. Azure IoT Developer Specialty. GCP Certifications.
If the transformation step comes after loading (for example, when data is consolidated in a data lake or a data lakehouse ), the process is known as ELT. You can learn more about how such data pipelines are built in our video about dataengineering. Self-service capabilities for all business users.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by dataengineering practices that include object storage. Watch our video explaining how dataengineering works.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content