This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The next phase of this transformation requires an intelligent datainfrastructure that can bring AI closer to enterprise data. The challenges of integrating data with AI workflows When I speak with our customers, the challenges they talk about involve integrating their data and their enterprise AI workflows.
As organizations adopt a cloud-first infrastructure strategy, they must weigh a number of factors to determine whether or not a workload belongs in the cloud. By optimizing energy consumption, companies can significantly reduce the cost of their infrastructure. Sustainable infrastructure is no longer optional–it’s essential.
Businesses can onboard these platforms quickly, connect to their existing data sources, and start analyzing data without needing a highly technical team or extensive infrastructure investments. This means no more paying for unused capacity or worrying about outgrowing a fixed-size infrastructure. The result?
Businesses can onboard these platforms quickly, connect to their existing data sources, and start analyzing data without needing a highly technical team or extensive infrastructure investments. This means no more paying for unused capacity or worrying about outgrowing a fixed-size infrastructure. The result?
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
However, they often forget about the fundamental work – data literacy, collection, and infrastructure – that must be done prior to building intelligent data products. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
The data preparation process should take place alongside a long-term strategy built around GenAI use cases, such as content creation, digital assistants, and code generation. Known as dataengineering, this involves setting up a data lake or lakehouse, with their data integrated with GenAI models.
A cloud architect has a profound understanding of storage, servers, analytics, and many more. Big DataEngineer. Another highest-paying job skill in the IT sector is big dataengineering. And as a big dataengineer, you need to work around the big data sets of the applications.
If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. We will try to answer your questions and explain how two critical data jobs are different and where they overlap. Data science vs dataengineering.
The data architect also “provides a standard common business vocabulary, expresses strategic requirements, outlines high-level integrated designs to meet those requirements, and aligns with enterprise strategy and related business architecture,” according to DAMA International’s Data Management Body of Knowledge.
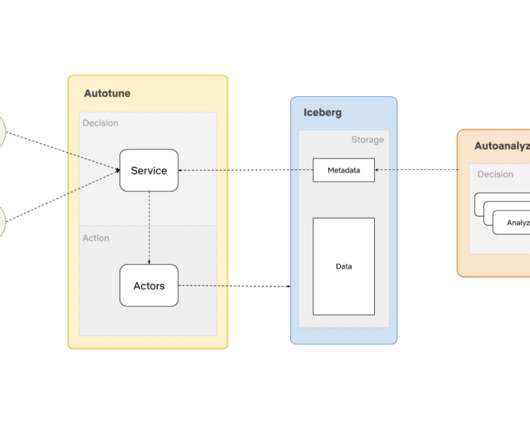
The Iceberg REST catalog specification is a key component for making Iceberg tables available and discoverable by many different tools and execution engines. It enables easy integration and interaction with Iceberg table metadata via an API and also decouples metadata management from the underlying storage.
Data Science and Machine Learning sessions will cover tools, techniques, and case studies. This year’s sessions on DataEngineering and Architecture showcases streaming and real-time applications, along with the data platforms used at several leading companies. Privacy and security. Visualization, Design, and UX sessions.
I know this because I used to be a dataengineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Regular data processing.
So, along with data scientists who create algorithms, there are dataengineers, the architects of data platforms. In this article we’ll explain what a dataengineer is, the field of their responsibilities, skill sets, and general role description. What is a dataengineer?
Modak, a leading provider of modern dataengineering solutions, is now a certified solution partner with Cloudera. Customers can now seamlessly automate migration to Cloudera’s Hybrid Data Platform — Cloudera Data Platform (CDP) to dynamically auto-scale cloud services with Cloudera DataEngineering (CDE) integration with Modak Nabu.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
“A managed version of Flyte, called Union Cloud, will allow smaller teams and organizations to use the power of Flyte without the need to staff up on infrastructure teams,” Umare continued. “We [founded Union] because we believe that machine learning and data workflows are fundamentally different from software deployments.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Upgrading cloud infrastructure is critical for deploying broad AI initiatives more quickly, so that’s a key area where investments are being made this year. Cold: On-prem infrastructure As they did in 2022, many IT leaders are reducing investments in data centers and on-prem technologies. “We
BSH’s previous infrastructure and operations teams, which supported the European appliance manufacturer’s application development groups, simply acted as suppliers of infrastructure services for the software development organizations. Our gap was operational excellence,” he says. “We
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative datainfrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems. A REST API is built directly into our VSP storage controllers.
Please check it out — it lets you run things in the cloud without having to think about infrastructure. It's primarily meant for data teams. Whether you're running SQL or doing ML, it's often pointless to do that on non-production data. We run everything in our infrastructure, so there's nothing to set up other than that.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
The first data source connected was an Amazon Simple Storage Service (Amazon S3) bucket, where a 100-page RFP manual was uploaded for natural language querying by users. The data source allowed accurate results to be returned based on indexed content. Joel Elscott is a Senior DataEngineer on the Principal AI Enablement team.
To do this, they are constantly looking to partner with experts who can guide them on what to do with that data. This is where dataengineering services providers come into play. Dataengineering consulting is an inclusive term that encompasses multiple processes and business functions.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). It includes major services related to compute, storage, network, and security, and is aimed at those in administrative and technical roles looking to validate administration knowledge in cloud services.
From infrastructure to tools to training, Ben Lorica looks at what’s ahead for data. Whether you’re a business leader or a practitioner, here are key data trends to watch and explore in the months ahead. Increasing focus on building data culture, organization, and training. Cloud for datainfrastructure.
The forecasting systems DTN had acquired were developed by different companies, on different technology stacks, with different storage, alerting systems, and visualization layers. Working with his new colleagues, he quickly identified rebuilding those five systems around a single forecast engine as a top priority.
I list a few examples from the media industry, but there are are numerous new startups that collect aerial imagery, weather data, in-game sports data , and logistics data, among other things. If you are an aspiring entrepreneur, note that you can build interesting and highly valued companies by focusing on data.
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Supports Disaggregation of compute and storage.
The customer interaction transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket. Its serverless architecture allowed the team to rapidly prototype and refine their application without the burden of managing complex hardware infrastructure.
Few if any data management frameworks are business focused, to not only promote efficient use of data and allocation of resources, but also to curate the data to understand the meaning of the data as well as the technologies that are applied to the data so that dataengineers can move and transform the essential data that data consumers need.
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems. Dataengineer.
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machine learning, dataengineering, distributed microservices, and full stack systems. Dataengineer.
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. This can only be achieved if the underlying datainfrastructure is unified, robust, and efficient. The storage for these features is referred to as a feature store.
When our dataengineering team was enlisted to work on Tenable One, we knew we needed a strong partner. When Tenable’s product engineering team came to us in dataengineering asking how we could build a data platform to power the product, we knew we had an incredible opportunity to modernize our data stack.
Microsoft Certified Azure AI Engineer Associate ( Associate ). Microsoft Certified Azure DataEngineer Associate ( Associate ). It includes major services related to compute, storage, network, and security, and is aimed at those in administrative and technical roles looking to validate administration knowledge in cloud services.
Note: I'm going to use the term “tool” throughout this post to refer to all kinds of things: frameworks, libraries, development processes, infrastructure.). Decades ago, software engineering was hard because you had to build everything from scratch and solve all these foundational problems.
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. After all, machine learning with Python requires the use of algorithms that allow computer programs to constantly learn, but building that infrastructure is several levels higher in complexity. For now, we’ll focus on Kafka.
Data obsession is all the rage today, as all businesses struggle to get data. But, unlike oil, data itself costs nothing, unless you can make sense of it. Dedicated fields of knowledge like dataengineering and data science became the gold miners bringing new methods to collect, process, and store data.
In the article, we explore the role of a data architect, discuss the responsibilities and required skills, and share what kind of companies may need such a specialist. What is a data architect? Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company.
This material uncovers the specifics of the underlying BI datainfrastructure, so we suggest you reading it to get a deeper insight on the topic. Let’s break them down: A data source layer is where the raw data is stored. Those are any of your databases, cloud-storages, and separate files filled with unstructured data.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content