This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But building data pipelines to generate these features is hard, requires significant dataengineering manpower, and can add weeks or months to project delivery times,” Del Balso told TechCrunch in an email interview. Feast instead reuses existing cloud or on-premises hardware, spinning up new resources when needed.
While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business. Depending on your needs, large language models (LLMs) may not be necessary for your operations, since they are trained on massive amounts of text and are largely for general use.
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
Data analytics describes the current state of reality, whereas data science uses that data to predict and/or understand the future. The benefits of data science. The business value of data science depends on organizational needs. For further information about data scientist skills, see “ What is a data scientist?
Crunching mathematical calculations, the model then makes predictions based on what it has learned during training. Inferencing crunches millions or even billions of data points, requiring a lot of computational horsepower. The engines use this information to recommend content based on users’ preference history.
Database developers should have experience with NoSQL databases, Oracle Database, big data infrastructure, and big dataengines such as Hadoop. These IT pros typically have a bachelor’s degree in computer science and should be knowledgeable in LAN/WAN protocol, software, and hardware.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
I’m responsible for training the mechanics, the engineers, and each driver.” Under the hood The cars used in the race produce vast amounts of data: from sensors in the engine and gearbox, to the suspension and brakes. The only differentiator is driver skill. The process took between 30 minutes and two hours.
These measures make sure that client data remains secure during processing and isnt used for model training by third-party providers. Its serverless architecture allowed the team to rapidly prototype and refine their application without the burden of managing complex hardware infrastructure.
Every business unit has a stake in the IT services, apps, networks, hardware, and software needed to meet business goals and objectives, and many of them are hiring their own technologists. Technology has quickly become a top priority for businesses across every industry.
We’ll share why in a moment, but first, we want to look at a historical perspective with what happened to data warehouses and dataengineering platforms. Lessons Learned from Data Warehouse and DataEngineering Platforms. This is an open question, but we’re putting our money on best-of-breed products.
This year, we expanded our partnership with NVIDIA , enabling your data teams to dramatically speed up compute processes for dataengineering and data science workloads with no code changes using RAPIDS AI. This notebook goes through loading just the train and test datasets. The training of the model.
Bring the right skills onboard As a baseline, every platform engineering team needs to hire people who have strong communication skills, are technically proficient in software development, hardware and data, have excellent analytical and problem solving skills, and are familiar with platform engineering tools, says Atkinson.
As I pointed out in previous posts, we learned many companies are still in the early stages of deploying machine learning: Companies cite “lack of data” and “lack of skilled people” as the main factors holding back adoption. In addition to data generation, another important aspect is data sharing.
Most respondents participated in training of some form. Learning new skills and improving old ones were the most common reasons for training, though hireability and job security were also factors. Company-provided training opportunities were most strongly associated with pay increases. Demographics.
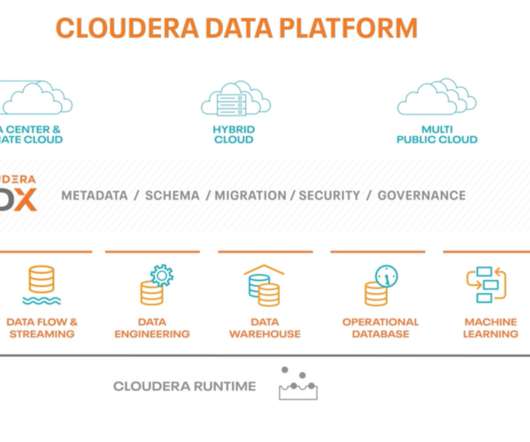
Informatica and Cloudera deliver a proven set of solutions for rapidly curating data into trusted information. Informatica’s comprehensive suite of DataEngineering solutions is designed to run natively on Cloudera Data Platform — taking full advantage of the scalable computing platform.
NVIDIA has developed techniques for training primitive graphical operations for neural networks in near real-time. Poor data quality, lack of accountability, lack of explainability, and the misuse of data–all problems that could make vulnerable people even more so. Is it another component of Web3 or something new and different?
In our own online training platform (which has more than 2.1 Below are the top search topics on our training platform: Beyond “search,” note that we’re seeing strong growth in consumption of content related to ML across all formats—books, posts, video, and training.
Kubernetes would seem to be an ideal way to address some of the obstacles to getting AI/ML workloads into production. Kubeflow has its own challenges, too, including difficulties with installation and with integrating its loosely-coupled components, as well as poor documentation.
For example, if the problem is predicting patient readmissions in healthcare, one approach is to analyze electronic health records, while another might involve real-time monitoring data. Furthermore, it’s essential to compare the benefits of using a pre-trained model, if applicable, or training one from scratch.
The sample is far from tech-laden, however: the only other explicit technology category—“Computers, Electronics, & Hardware”—accounts for less than 7% of the sample. Data scientists dominate, but executives are amply represented. One-sixth of respondents identify as data scientists, but executives—i.e.,
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
Those models are trained or augmented with data from a data management platform. The data management platform, models, and end applications are powered by cloud infrastructure and/or specialized hardware. We see AI applications like chatbots being built on top of closed-source or open source foundational models.
Sometimes, a data or business analyst is employed to interpret available data, or a part-time dataengineer is involved to manage the data architecture and customize the purchased software. At this stage, data is siloed, not accessible for most employees, and decisions are mostly not data-driven.
Going from petabytes (PB) to exabytes (EB) of data is no small feat, requiring significant investments in hardware, software, and human resources. Prepare : Orchestrate and automate complex data pipelines with an all-inclusive toolset and a cloud-native service purpose-built for enterprise dataengineering teams.
So I think for anyone who wants to build cool ML algos, they should also learn backend and dataengineering. How do you respond when you hear the phrase ‘big data’? Seriously, there’s this weird anti-trend of people bashing big data. You don’t have big data”. I almost definitely had big data at Spotify.
So I think for anyone who wants to build cool ML algos, they should also learn backend and dataengineering. How do you respond when you hear the phrase ‘big data’? Seriously, there’s this weird anti-trend of people bashing big data. You don’t have big data”. I almost definitely had big data at Spotify.
In order to plan how to train you to learn and evolve itself, an important step is to define which development and deployment platform for Machine Learning you’ll use. It includes pre-trained services for computer vision, language, recommendations, and forecasting. Pricing: AWS offers a pay-as-you-go model. Watson Machine Learning.
Network, customer, finance, partner, and operational data all contribute to a comprehensive view of business performance and service delivery that can make the difference between the right strategy at the right time, and a decision that maybe shouldn’t have been made.
Hardware and software become obsolete sooner than ever before. So data migration is an unavoidable challenge each company faces once in a while. Transferring data from one computer environment to another is a time-consuming, multi-step process involving such activities as planning, data profiling, testing, to name a few.
Challenge 2: Different Training and Production Architectures. Organizations often have multiple training tools, and a lengthy compute lifecycle. Typical IT departments work with dozens of evolving language and framework combinations and hardware modifications. How to Thrive in the Age of Data Dominance. Download Now.
Technical Expertise and Hard Skills for AI Engineers PRO TIP “When AI projects demand rapid development, finding skilled engineers quickly can be a game-changer. Mobilunitys outstaffing solution offers instant access to highly trained AI experts, allowing you to meet project demands without compromising quality.”
AWS has removed all ML barriers that have traditionally slowed down devs and data scientists. Amazon offers the broadest and deepest set of ML and AI services, including pre-trained services for computer vision, language, recommendations, and forecasting. Pricing: try it out free for 12-months. Watson Machine Learning .
Google Professional Machine Learning Engineer implies developers knowledge of design, building, and deployment of ML models using Google Cloud tools. It includes subjects like dataengineering, model optimization, and deployment in real-world conditions.
Hadoop allows you to leverage data from multiple sources and in different formats, both structured and unstructured. You don’t need to archive or clean data before loading. Hadoop works on low-cost, commodity hardware which makes it relatively cheap to maintain. Physically, they require the best hardware resources available.
For lack of similar capabilities, some of our competitors began implying that we would no longer be focused on the innovative data infrastructure, storage and compute solutions that were the hallmark of Hitachi Data Systems.
This data-driven transparency simplifies strategic decisions, so LLMs may sometimes substitute for some counseling jobs. Internal system training. With an advanced LLM, businesses can assemble personalized trainingdata or deliver round-the-clock assistance within internal systems to guide employees through tasks and processes.
A data architect focuses on building a robust infrastructure so that data brings business value. Data modeling: creating useful and meaningful data entities. Data integration and interoperability: consolidating data into a single view. Snowflake data management processes. Ensure data accessibility.
As a Cloud Infrastructure Manager, I want to be able to easily scale up or down the compute resources in my cloud infrastructure to meet changing demands, without having to worry about the underlying hardware. Expected outcome : Develop software that optimizes workflows, strengthens security protocols, and enhances employee training methods.
Depending on the complexity of your data architecture, consider hiring a business analyst , dataengineer , or a team of data scientists to manage your company’s data in a most efficient way. Only with such a holistic approach to data, you can build a prosperous business.
This compact, low-level language runs on a Python virtual machine (PVM), which is software that mimics the work of the real hardware. By contrast, a low-level language offers little to no human-readable elements, as it sits close to hardware and is often optimized for a specific CPU (central processing unit.). Dynamic semantics.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing dataengineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with dataengineering in general.
Process maps can be used as a guide or template to train bots, outlining the sequence of necessary steps. Besides, they hired a data scientist to further discover opportunities for process improvement and trained more people in big data. Process mining discovers areas that need improvement and can benefit from automation.
Effective training programmes are essential. Outsourcing: Some of the work related to dataengineering and DevOps/SRE may be outsourced to concentrate resources towards achieving the business goals. #2 How to manage data and the model?—We The AI narrative should be as much inward focused as outward.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content