This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its a common skill for cloud engineers, DevOps engineers, solutions architects, dataengineers, cybersecurity analysts, software developers, network administrators, and many more IT roles. Job listings: 90,550 Year-over-year increase: 7% Total resumes: 32,773,163 3. As such, Oracle skills are perennially in-demand skill.
As with many data-hungry workloads, the instinct is to offload LLM applications into a public cloud, whose strengths include speedy time-to-market and scalability. Inferencing funneled through RAG must be efficient, scalable, and optimized to make GenAI applications useful. Inferencing and… Sherlock Holmes???
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics. It brings together DevOps teams with dataengineers and data scientists to provide the tools, processes, and organizational structures to support the data-focused enterprise. What is DataOps?
The data preparation process should take place alongside a long-term strategy built around GenAI use cases, such as content creation, digital assistants, and code generation. Known as dataengineering, this involves setting up a data lake or lakehouse, with their data integrated with GenAI models.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. Big data processing. maintaining data pipeline.
Database developers should have experience with NoSQL databases, Oracle Database, big data infrastructure, and big dataengines such as Hadoop. It requires a strong ability for complex project management and to juggle design requirements while ensuring the final product is scalable, maintainable, and efficient.
The demand for specialized skills has boosted salaries in cybersecurity, data, engineering, development, and program management. It’s a role that not only requires technical skills, but also leadership and communication skills as well to work across departments and to manage teams of engineers. increase from 2021.
Amazon Bedrocks broad choice of FMs from leading AI companies, along with its scalability and security features, made it an ideal solution for MaestroQA. Its serverless architecture allowed the team to rapidly prototype and refine their application without the burden of managing complex hardware infrastructure.
Platform engineering: purpose and popularity Platform engineering teams are responsible for creating and running self-service platforms for internal software developers to use. The value proposition of IT will move into providing scalable, reliable platform services as well as IT expertise into those product teams.”
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
Going from petabytes (PB) to exabytes (EB) of data is no small feat, requiring significant investments in hardware, software, and human resources. This can be achieved by utilizing dense storage nodes and implementing fault tolerance and resiliency measures for managing such a large amount of data. Focus on scalability.
Cloudera Private Cloud Data Services is a comprehensive platform that empowers organizations to deliver trusted enterprise data at scale in order to deliver fast, actionable insights and trusted AI. This means you can expect simpler data management and drastically improved productivity for your business users.
The variety of data explodes and on-premises options fail to handle it. Apart from the lack of scalability and flexibility offered by modern databases, the traditional ones are costly to implement and maintain. At the moment, cloud-based data warehouse architectures provide the most effective employment of data warehousing resources.
Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Businesses are also looking to move to a scale-out storage model that provides dense storages along with reliability, scalability, and performance.
Kubernetes would seem to be an ideal way to address some of the obstacles to getting AI/ML workloads into production. Kubeflow has its own challenges, too, including difficulties with installation and with integrating its loosely-coupled components, as well as poor documentation.
Hardware and software become obsolete sooner than ever before. So data migration is an unavoidable challenge each company faces once in a while. Transferring data from one computer environment to another is a time-consuming, multi-step process involving such activities as planning, data profiling, testing, to name a few.
This includes Apache Hadoop , an open-source software that was initially created to continuously ingest data from different sources, no matter its type. Cloud data warehouses such as Snowflake, Redshift, and BigQuery also support ELT, as they separate storage and compute resources and are highly scalable.
Data architect and other data science roles compared Data architect vs dataengineerDataengineer is an IT specialist that develops, tests, and maintains data pipelines to bring together data from various sources and make it available for data scientists and other specialists.
It offers features such as data ingestion, storage, ETL, BI and analytics, observability, and AI model development and deployment. The platform offers advanced capabilities for data warehousing (DW), dataengineering (DE), and machine learning (ML), with built-in data protection, security, and governance.
This is the stage where scalability becomes a reality, adapting to growing data and user demands while continuously fortifying security measures. Moreover, it is a period of dynamic adaptation, where documentation and operational protocols will adapt as your data and technology landscape change.
As a result, it became possible to provide real-time analytics by processing streamed data. Please note: this topic requires some general understanding of analytics and dataengineering, so we suggest you read the following articles if you’re new to the topic: Dataengineering overview.
Those models are trained or augmented with data from a data management platform. The data management platform, models, and end applications are powered by cloud infrastructure and/or specialized hardware.
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
Drawing on more than a decade of experience in building and deploying massive scale data platforms on economical budgets, Cloudera has designed and delivered a cost-cutting cloud-native solution – Cloudera Data Warehouse (CDW), part of the new Cloudera Data Platform (CDP). 2,300 / month for the cloud hardware costs.
scalability. Hadoop allows you to leverage data from multiple sources and in different formats, both structured and unstructured. You don’t need to archive or clean data before loading. Hadoop works on low-cost, commodity hardware which makes it relatively cheap to maintain. No real-time data processing.
Having a live view of all aspects of their network lets them identify potentially faulty hardware in real time so they can avoid impact to customer call/data service. Ingest 100s of TB of network event data per day . By doing so the benefits to ingest speed, query latency, and scalability can be huge. Data Hub – .
It offers high throughput, low latency, and scalability that meets the requirements of Big Data. The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. But for high availability and data loss prevention, it’s recommended that you have at least three brokers.
” Cyril Samovskiy, Founder of Mobilunity Tech Stack Proficiency AI-proficient engineers must write clean, efficient, and scalable code, ensuring their AI frameworks run effectively in various environments.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Native frameworks.
A data architect focuses on building a robust infrastructure so that data brings business value. Data modeling: creating useful and meaningful data entities. Data integration and interoperability: consolidating data into a single view. Snowflake provides computing resources scalable for different workloads.
The concept of Big Data isn’t new: It has been the desired fruit for several decades already as the capabilities of software and hardware have made it possible for companies to successfully manage vast amounts of complex data. Big Data analytics processes and tools. Data ingestion. Apache Kafka.
And this is what makes a data warehouse different from a Data Lake. Data Lakes are used to store unstructured data for analytical purposes. But unlike warehouses, data lakes are used more by dataengineers/scientists to work with big sets of raw data. Subject-oriented data.
What happens, when a data scientist, BI developer , or dataengineer feeds a huge file to Hadoop? Under the hood, the framework divides a chunk of Big Data into smaller, digestible parts and allocates them across multiple commodity machines to be processed in parallel. Scalability. Apache Hadoop architecture.
Legacy data warehouse solutions are often inefficient due to their scale-up architecture, attempting to serve multiple phases of the data lifecycle with a single monolithic architecture, ineffective management and performance tuning tools. . ETL jobs and staging of data often often require large amounts of resources.
ML algorithms for predictions and data-based decisions; Deep Learning expertise to analyze unstructured data, such as images, audio, and text; Mathematics and statistics. Google Professional Machine Learning Engineer implies developers knowledge of design, building, and deployment of ML models using Google Cloud tools.
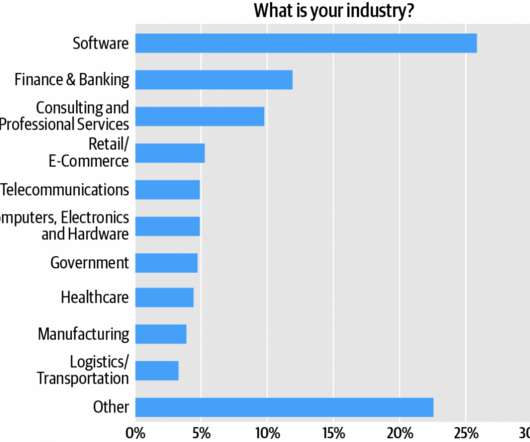
Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. Combined, technology verticals—software, computers/hardware, and telecommunications—account for about 35% of the audience (Figure 2).
Let’s take a quick look at the big data infrastructure. Big Data infrastructure in healthcare. In general, a data infrastructure is a system of hardware and software tools used to collect, store, transfer, prepare, analyze, and visualize data. Big data infrastructure in a nutshell. Staffing problems.
For many enterprises, applications represent only a portion of a much larger reliability mandate, including offices, robotics, hardware, and IoT, and the complex networking, data, and observability infrastructure required to facilitate such a mandate.
Now we are moving to the section, where we will discuss tools that you can use to perform data visualization. Data visualization tools and libraries. There are a lot of products on the market of data visualization. GB, Sisense about 5 GB), and require modern hardware to operate without burning your computer.
As a Cloud Infrastructure Manager, I want to be able to easily scale up or down the compute resources in my cloud infrastructure to meet changing demands, without having to worry about the underlying hardware. Scalability: It can handle large volumes of data with ease, making it ideal for complex projects4. Thanks to Gemini 1.5
Whether your goal is data analytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced dataengineers, designing a new data pipeline is a unique journey each time. Dataengineering in 14 minutes. Scalability. Please note!
Depending on the complexity of your data architecture, consider hiring a business analyst , dataengineer , or a team of data scientists to manage your company’s data in a most efficient way. Think about the functionality you want and results you’re looking for.
Not long ago setting up a data warehouse — a central information repository enabling business intelligence and analytics — meant purchasing expensive, purpose-built hardware appliances and running a local data center. This demand gave birth to cloud data warehouses that offer flexibility, scalability, and high performance.
That’s a fairly good picture of our core audience’s interests: solidly technical, focused on software rather than hardware, but with a significant stake in business topics. The topics that saw the greatest growth were business (30%), design (23%), data (20%), security (20%), and hardware (19%)—all in the neighborhood of 20% growth.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content