This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Cloud storage.
The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both. Imagine that you’re a dataengineer. The data is spread out across your different storage systems, and you don’t know what is where. Through relentless innovation.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. Once the decision is made, inefficiencies can be categorized into two primary areas: compute and storage.
A lack of monitoring might result in idle clusters running longer than necessary, overly broad data queries consuming excessive compute resources, or unexpected storage costs due to unoptimized data retention. Once the decision is made, inefficiencies can be categorized into two primary areas: compute and storage.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
Since the release of Cloudera DataEngineering (CDE) more than a year ago , our number one goal was operationalizing Spark pipelines at scale with first class tooling designed to streamline automation and observability. Securing and scaling storage. In the latter half of the year, we completely transitioned to Airflow 2.1.
Application data architect: The application data architect designs and implements data models for specific software applications. Information/datagovernance architect: These individuals establish and enforce datagovernance policies and procedures.
With growing disparate data across everything from edge devices to individual lines of business needing to be consolidated, curated, and delivered for downstream consumption, it’s no wonder that dataengineering has become the most in-demand role across businesses — growing at an estimated rate of 50% year over year.
The Iceberg REST catalog specification is a key component for making Iceberg tables available and discoverable by many different tools and execution engines. It enables easy integration and interaction with Iceberg table metadata via an API and also decouples metadata management from the underlying storage.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Azure Key Vault Secrets offers a centralized and secure storage alternative for API keys, passwords, certificates, and other sensitive statistics. Azure Key Vault is a cloud service that provides secure storage and access to confidential information such as passwords, API keys, and connection strings. What is Azure Key Vault Secret?
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
That’s why a data specialist with big data skills is one of the most sought-after IT candidates. DataEngineering positions have grown by half and they typically require big data skills. Dataengineering vs big dataengineering. This greatly increases data processing capabilities.
Deletion vectors are a storage optimization feature that replaces physical deletion with soft deletion. Data privacy regulations such as GDPR , HIPAA , and CCPA impose strict requirements on organizations handling personally identifiable information (PII) and protected health information (PHI). What Are Deletion Vectors?
I mentioned in an earlier blog titled, “Staffing your big data team, ” that dataengineers are critical to a successful data journey. That said, most companies that are early in their journey lack a dedicated engineering group. Image 1: DataEngineering Skillsets.
They may also ensure consistency in terms of processes, architecture, security, and technical governance. Our platform engineering teams, which support more than 200 applications, have innovated around automation,” says Bob Simms, former director of enterprise infrastructure delivery at the US Patent and Trademark Office (USPTO).
Principal implemented several measures to improve the security, governance, and performance of its conversational AI platform. The Principal AI Enablement team, which was building the generative AI experience, consulted with governance and security teams to make sure security and data privacy standards were met.
Everybody needs more data and more analytics, with so many different and sometimes often conflicting needs. Dataengineers need batch resources, while data scientists need to quickly onboard ephemeral users. Using a single data context, well-governed, ensures we have the best quality data available to all users at once.
OCI’s Supercluster includes OCI Compute Bare Metal, which provides an ultralow-latency remote direct access memory (RDMA) over a Converged Ethernet (RoCE) cluster for low-latency networking, and a choice of high-performance computing storage options.
The third and most complicated layer is architecture and governance, which we’ve linked together as one layer. The last layer is raw data, which is where we get the data out of the source systems, organize it, secure it, and figure out which data lakes to use. What happens at the architecture and governance layer?
The demand for data skills (“the sexiest job of the 21st century”) hasn’t dissipated. LinkedIn recently found that demand for data scientists in the US is “off the charts,” and our survey indicated that the demand for data scientists and dataengineers is strong not just in the US but globally.
Organizations have balanced competing needs to make more efficient data-driven decisions and to build the technical infrastructure to support that goal. Many companies today struggle with legacy software applications and complex environments, which leads to difficulty in integrating new data elements or services.
It is built around a data lake called OneLake, and brings together new and existing components from Microsoft Power BI, Azure Synapse, and Azure Data Factory into a single integrated environment. In many ways, Fabric is Microsoft’s answer to Google Cloud Dataplex. As of this writing, Fabric is in preview.
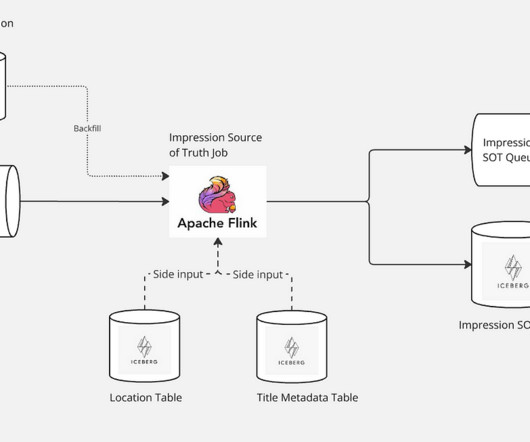
This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
It’s no secret that IT modernization is a top priority for the US federal government. In the private sector, excluding highly regulated industries like financial services, the migration to the public cloud was the answer to most IT modernization woes, especially those around data, analytics, and storage.
Few Data Management Frameworks are Business Focused Data management has been around since the beginning of IT, and a lot of technology has been focused on big data deployments, governance, best practices, tools, etc. However, large data hubs over the last 25 years (e.g.,
CDP Generalist The Cloudera Data Platform (CDP) Generalist certification verifies proficiency with the Cloudera CDP platform. The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, dataengineer, data scientist, and system architect.
A TPC-DS 10TB dataset was generated in ACID ORC format and stored on the ADLS Gen 2 cloud storage. Cloudera Data Warehouse vs HDInsight. Finally, CDW is offered in CDP along with other data lifecycle services – DataEngineering, Operational Database, Machine Learning, and Data Hub.
The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, dataengineer, data scientist, and system architect. The exam consists of 60 questions and the candidate has 90 minutes to complete it.
Generally, if five LOB users use the data warehouse on a public cloud for eight hours a day for one month, you pay for the use of the service and the associated cloud hardware resources (compute and storage) for this period. 150 for storage use = $15 / TB / month x 10 TB. 150 for storage use = $15 / TB / month x 10 TB.
Start with storage. Before you can even think about analyzing exabytes worth of data, ensure you have the infrastructure to store more than 1000 petabytes! Going from 250 PB to even a single exabyte means multiplying storage capabilities four times. Merely adding more data nodes is insufficient. Focus on scalability.
And that some people in your company should be allowed to view that personal data, while others should not. And let’s say you have an employees table that looks like this: employee_id first_name yearly_income team_name 1 Marta 123.456 DataEngineers 2 Tim 98.765 Data Analysts You could provide access to this table in different ways.
As the amount of enterprise data continues to surge, businesses are increasingly recognizing the importance of datagovernance — the framework for managing an organization’s data assets for accuracy, consistency, security, and effective use. Projections show that the datagovernance market will expand from $1.81
Today’s general availability announcement covers Iceberg running within key data services in the Cloudera Data Platform (CDP) — including Cloudera Data Warehousing ( CDW ), Cloudera DataEngineering ( CDE ), and Cloudera Machine Learning ( CML ). Why integrate Apache Iceberg with Cloudera Data Platform?
There are many reasons for this failure, but poor (or a complete lack of) datagovernance strategies is most often to blame. This article discusses the importance of solid datagovernance implementation plans and why, despite its obvious benefits, many organizations find datagovernance implementation to be challenging.
Data is the fuel that drives government, enables transparency, and powers citizen services. Data quality issues deter trust and hinder accurate analytics. Citizens who have negative experiences with government services are less likely to use those services in the future. Modern data architectures.
Please join us on March 24 for Future of Data meetup where we do a deep dive into Iceberg with CDP . Apache Iceberg is a high-performance, open table format, born-in-the cloud that scales to petabytes independent of the underlying storage layer and the access engine layer. What is Apache Iceberg? 1: Multi-function analytics .
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. If yes, the solution retrieves and executes the previously-generated python codes (Step 2) and the transformed data is stored in S3 (Step 10).
The data journey is not linear, but it is an infinite loop data lifecycle – initiating at the edge, weaving through a data platform, and resulting in business imperative insights applied to real business-critical problems that result in new data-led initiatives. Fig 1: The Enterprise Data Lifecycle.
Optimized read and write paths to cloud object stores (S3, Azure Data Lake Storage, etc) with local caching, allowing workloads to run directly against data in shared object stores without explicit loading to local storage. No local data loading step was required prior to query execution.
Model interpretability is one of five main components of model governance. In this article, we explore model governance, a function of ML Operations (MLOps). Each project consists of a declarative series of steps or operations that define the data science workflow. blueberry spacing) is a measure of the model’s interpretability.
For this reason, many financial institutions are converting their fraud detection systems to machine learning and advanced analytics and letting the data detect fraudulent activity. Regulated data also needs to show lineage, a history of where the data came from and what has been done with it.
Today, we are announcing a private technical preview (TP) release of Iceberg for CDP Data Services in the public cloud, including Cloudera Data Warehousing ( CDW ) and Cloudera DataEngineering ( CDE ). . That is why from day one we ensured the same security and governance of SDX apply to Iceberg tables.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content