This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
Integrated Data Lake Synapse Analytics is closely integrated with Azure Data Lake Storage (ADLS), which provides a scalable storage layer for raw and structured data, enabling both batch and interactive analytics. on-premises, AWS, GoogleCloud). When Should You Use Azure Synapse Analytics?
The role typically requires a bachelor’s degree in computer science or a related field and at least three years of experience in cloud computing. Keep an eye out for candidates with certifications such as AWS Certified Cloud Practitioner, GoogleCloud Professional, and Microsoft Certified: Azure Fundamentals.
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way.
Software engineers are one of the most sought-after roles in the US finance industry, with Dice citing a 28% growth in job postings from January to May. The most in-demand skills include DevOps, Java, Python, SQL, NoSQL, React, GoogleCloud, Microsoft Azure, and AWS tools, among others. Dataengineer.
Software engineers are one of the most sought-after roles in the US finance industry, with Dice citing a 28% growth in job postings from January to May. The most in-demand skills include DevOps, Java, Python, SQL, NoSQL, React, GoogleCloud, Microsoft Azure, and AWS tools, among others. Dataengineer.
Technologies that have expanded Big Data possibilities even further are cloud computing and graph databases. The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer?
Individuals in an associate solutions architect role have 1+ years of experience designing available, fault-tolerant, scalable, and most importantly cost-efficient, distributed systems on AWS. Must prove knowledge of deploying, operating and managing highly available, scalable and fault-tolerant systems on AWS.
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies.
The variety of data explodes and on-premises options fail to handle it. Apart from the lack of scalability and flexibility offered by modern databases, the traditional ones are costly to implement and maintain. At the moment, cloud-based data warehouse architectures provide the most effective employment of data warehousing resources.
In the first article in this series, I explained the five components necessary to prevent a Data Lake from Becoming a Data Swamp. Data lakes work on the concept of load first and use later, which means the data stored in the repository doesn’t necessarily have to be used immediately for a specific purpose.
Programming with Data: Advanced Python and Pandas , July 9. Understanding Data Science Algorithms in R: Regression , July 12. Cleaning Data at Scale , July 15. ScalableData Science with Apache Hadoop and Spark , July 16. Effective Data Center Design Techniques: Data Center Topologies and Control Planes , July 19.
With CDP, customers can deploy storage, compute, and access, all with the freedom offered by the cloud, avoiding vendor lock-in and taking advantage of best-of-breed solutions. The new capabilities of Apache Iceberg in CDP enable you to accelerate multi-cloud open lakehouse implementations. Performance and scalability.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Cloud-based tools. Phases of the data migration process.
Taking a RAG approach The retrieval-augmented generation (RAG) approach is a powerful technique that leverages the capabilities of Gen AI to make requirements engineering more efficient and effective. As a GoogleCloud Partner , in this instance we refer to text-based Gemini 1.5 What is Retrieval-Augmented Generation (RAG)?
Programming with Data: Advanced Python and Pandas , July 9. Understanding Data Science Algorithms in R: Regression , July 12. Cleaning Data at Scale , July 15. ScalableData Science with Apache Hadoop and Spark , July 16. Effective Data Center Design Techniques: Data Center Topologies and Control Planes , July 19.
What is Databricks Databricks is an analytics platform with a unified set of tools for dataengineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
ML algorithms for predictions and data-based decisions; Deep Learning expertise to analyze unstructured data, such as images, audio, and text; Mathematics and statistics. Google Professional Machine Learning Engineer implies developers knowledge of design, building, and deployment of ML models using GoogleCloud tools.
Python devs create robust and scalable solutions using Django and Flask frameworks. Developers gather and preprocess data to build and train algorithms with libraries like Keras, TensorFlow, and PyTorch. Dataengineering. They efficiently extract and manipulate data to process and analyze large datasets.
As a result, it became possible to provide real-time analytics by processing streamed data. Please note: this topic requires some general understanding of analytics and dataengineering, so we suggest you read the following articles if you’re new to the topic: Dataengineering overview.
It offers high throughput, low latency, and scalability that meets the requirements of Big Data. The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. Still, it’s the number one choice for data-driven companies, and here’re some reasons why. Scalability.
With the consistent rise in data volume, variety, and velocity, organizations started seeking special solutions to store and process the information tsunami. This demand gave birth to clouddata warehouses that offer flexibility, scalability, and high performance. As such, it is considered cloud-agnostic.
” Cyril Samovskiy, Founder of Mobilunity Tech Stack Proficiency AI-proficient engineers must write clean, efficient, and scalable code, ensuring their AI frameworks run effectively in various environments.
In the world of big data processing, efficient and scalable file systems play a crucial role. It abstracts away the complexities of dealing with different storage backends, making it easier for dataengineers and data scientists to focus on their analysis and machine learning tasks. What is DBFS?
The infrastructural shift means going from a fragmented platform with separate operational and analytical planes to an integrated infrastructure for both operational and data systems. Data mesh can be utilized as an element of an enterprise data strategy and can be described through four interacting principles.
Rather than asking ‘what are the productivity gains’ and seeking to translate those metrics into incremental efficiencies or profits, visionary enterprises should ask ‘what is our North Star vision and roadmap for human value development in the Generative Engineering Era’. We look forward to working with you to help you build yours.
Data science and data analysis certification from IBM, Google, or Johns Hopkins University The mix of linguistic studies, computer science, and AI and NLP-related certifications from top platforms like GoogleCloud, DeepLearning.ai, and Microsoft are vital for obtaining the expertise and skills to work as a prompt designer.
Throughout the development, engineers constantly refine the model to improve its efficiency, speed, and capacity for bigger request volumes. Such optimization minimizes costs, cuts response times, and provides the model scalability for real-world business scenarios. GoogleCloud Certified: Machine Learning Engineer.
In addition to AI consulting, the company has expertise in delivering a wide range of AI development services , such as Generative AI services, Custom LLM development , AI App Development, DataEngineering, RAG As A Service , GPT Integration, and more. Founded: 2009 Location: London, UK Employees: 251-500 8.
Yet, there were some limitations in MPP at the time, because some of these systems running Hive were quite large, and the database community thought that instead of the future being Hive on MapReduce or something similar, that we could extend, bend, and change the MPP engines to actually operate in a more scalable manner on such large data.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
Decomposing a complex monolith into a complex set of microservices is a challenging task and certainly one that can’t be underestimated: developers are trading one kind of complexity for another in the hope of achieving increased flexibility and scalability long-term. Dataengineering was the dominant topic by far, growing 35% year over year.
What happens, when a data scientist, BI developer , or dataengineer feeds a huge file to Hadoop? Under the hood, the framework divides a chunk of Big Data into smaller, digestible parts and allocates them across multiple commodity machines to be processed in parallel. Scalability. Apache Hadoop architecture.
You can hardly compare dataengineering toil with something as easy as breathing or as fast as the wind. The platform went live in 2015 at Airbnb, the biggest home-sharing and vacation rental site, as an orchestrator for increasingly complex data pipelines. How dataengineering works. What is Apache Airflow?
By creating a lakehouse, a company gives every employee the ability to access and employ data and artificial intelligence to make better business decisions. Many organizations that implement a lakehouse as their key data strategy are seeing lightning-speed data insights with horizontally scalabledata-engineering pipelines.
I’m aware that I am skipping over GoogleCloud Platform, but tI want to focus on the questions I am actually asked rather than questions that could be asked. I am also not advocating for one cloud provider over another. AWS takes the approach of providing more dials to tune in exchange for greater flexibility.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























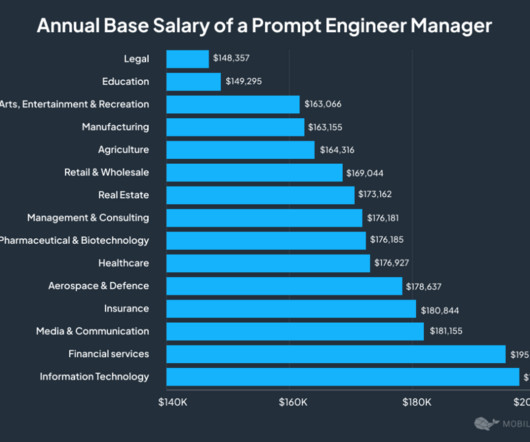
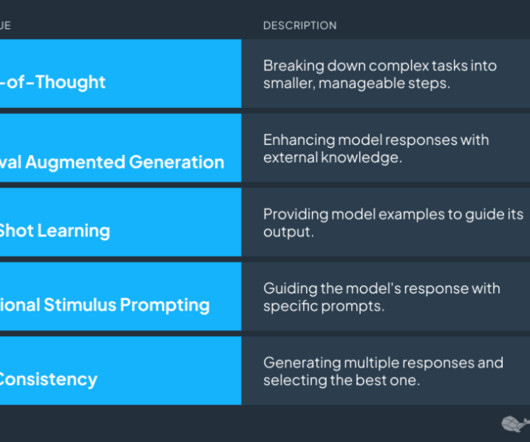

















Let's personalize your content