This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Plus, according to a recent survey of 2,500 senior leaders of global enterprises conducted by GoogleCloud and National Research Group, 34% say theyre already seeing ROI for individual productivity gen AI use cases, and 33% expect to see ROI within the next year. So a pretty high adoption rate for AI code generation.
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
“ Galileo … enforces the necessary rigor and the proactive application of research-backed techniques every step of the way in productionizing machine learning models … [It] leads to an order of magnitude improvement on how teams deal with the messy, mind-numbing task of improving their machine learning datasets.”
Predibase’s other co-founder, Travis Addair, was the lead maintainer for Horovod while working as a senior software engineer at Uber. and low-code dataengineering platform Prophecy (not to mention SageMaker and Vertex AI ). “[Our platform] has been used at Fortune 500 companies like a leading U.S.
Labeling data like legal contracts, medical images, and scientific literature requires domain expertise that not just any annotator has. In an MIT analysis of popular AI data sets, researchers found mislabeled data like one breed of dog confused for another and an Ariana Grande high note categorized as a whistle.
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
You can intuitively query the data from the data lake. Users coming from a data warehouse environment shouldn’t care where the data resides,” says Angelo Slawik, dataengineer at Moonfare. Gartner’s Ronthal sees the evolution of the data lake to the data lakehouse as an inexorable trend.
Living in the shadow, this stage, according to the recent study , eats up 25 percent of data scientists time. The same survey shows that putting a model from a research environment to production — where it eventually starts adding business value — takes between 8 to 90 days on average. Source: GoogleCloud.
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies.
But despite years of research and innovation, their unnatural responses remind us that no, we’re not yet at the HAL 9000-level of speech sophistication. Sentiment analysis results by GoogleCloud Natural Language API. Which of course means that there’s an abundance of research in this area. Spam detection.
Actionable Insights in a Week: User Research for Everyone , April 23. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , March 13. Data Modelling with Qlik Sense , March 19-20. Foundational Data Science with R , March 26-27. Managing Your Manager , April 25.
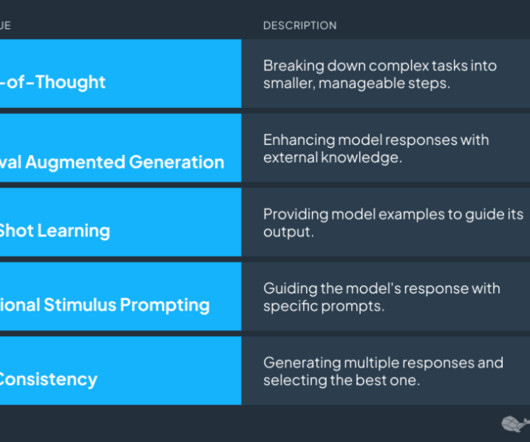
Taking a RAG approach The retrieval-augmented generation (RAG) approach is a powerful technique that leverages the capabilities of Gen AI to make requirements engineering more efficient and effective. As a GoogleCloud Partner , in this instance we refer to text-based Gemini 1.5 What is Retrieval-Augmented Generation (RAG)?
To get good output, you need to create a data environment that can be consumed by the model,” he says. You need to have dataengineering skills, and be able to recalibrate these models, so you probably need machine learning capabilities on your staff, and you need to be good at prompt engineering.
Artificial Intelligence, Machine Learning, or Robotics (PhD) is mostly a first choice for programmers deeply involved in academic research or high-level AI development, including original research, where they elaborate on new AI algorithms or solve complex AI-related problems. AI research scientist. Certifications.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
The highest salaries were associated with Clicktale (now ContentSquare), a cloud-based analytics system for researching customer experience: only 0.2% GoogleCloud is an obvious omission from this story. That was above the average salary for all users and at the low end of the midrange for salaries sorted by platform.
Having these requirements in mind and based on our own experience developing ML applications, we want to share with you 10 interesting platforms for developing and deploying smart apps: GoogleCloud. Another interesting aspect is the opportunity of collaborating as a team with GoogleColab for the research phase of a project.
GoogleCloud . Another great feature is the ability to collaborate as a team with GoogleColab for the research phase of any project. MathWork focused on the development of these tools to become experts in high-end financial use and dataengineering contexts.
Mr. Hypponen has written on his research for the New York Times, Wired, and Scientific American and he appears frequently on international TV. Launching 24/7 digital platforms made him appreciate how much cloud technologies are developer superpowers. He has worked at F-Secure for more than 30 years. Twitter: [link] Linkedin: [link].
Large language models can run through, research, and interpret large amounts of text data like reports and financial statements, to recognize trends and map out possible risks. LLM engineers stay in the loop of recent domain developments to learn new approaches for their existing models or further applications. Certifications.
Data Handling and Big Data Technologies Since AI systems rely heavily on data, engineers must ensure that data is clean, well-organized, and accessible. Do AI Engineer skills incorporate cloud computing? How important are soft skills for AI engineers?
Citing Microsoft’s principal researcher Rich Caruana, ‘75 percent of machine learning is preparing to do machine learning… and 15 percent is what you do afterwards.’ The rest is done by dataengineers, data scientists , machine learning engineers , and other high-trained (and high-paid) specialists.
But let’s gather some common tasks and responsibilities associated with the job of AI developers: Problem definition: It’s a common practice that AI experts have to work closely with stakeholders to understand business or research objectives. It really helps to identify problems solved or optimized using AI techniques.
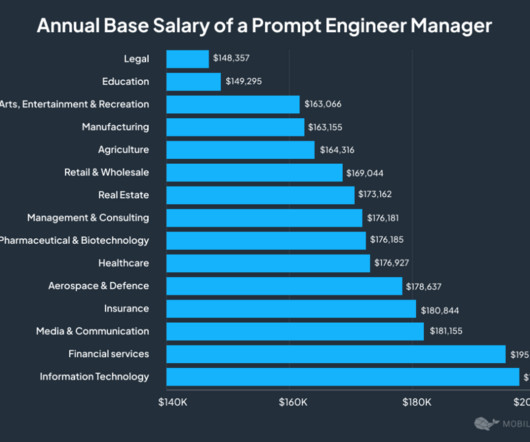
Insight “ Employment of computer and information research scientists is projected to grow 26 percent from 2023 to 2033, much faster than the average for all occupations.” ( U.S. Like no other, we know about the high demand for prompt engineers and see how much potential this field has. Bureau of Labor Statistics ).
But the current epoch of distributed computing is often traced to December of 2004, when Googleresearchers Jeffrey Dean and Sanjay Ghemawat presented a paper unveiling MapReduce. So in 2010 Google one-upped Hadoop, publishing a white paper titled “Dremel: Interactive Analysis of Web-Scale Datasets.”
According to BCC research , the global AI consulting market is expected to reach $4.3 We conducted comprehensive research and shortlisted the most popular and best AI consulting companies in USA, India, and other parts of the world based on the following criteria. billion in 2028.
Greg Rahn: Toward the end of that eight-year stint, I saw this thing coming up called Hadoop and an engine called Hive. It kind of was interesting to me that there were these big internet companies in the valley running this platform or a variation thereof of, based on Googleresearch papers. Greg Rahn: Oh, definitely.
Building applications with RAG requires a portfolio of data (company financials, customer data, data purchased from other sources) that can be used to build queries, and data scientists know how to work with data at scale. Dataengineers build the infrastructure to collect, store, and analyze data.
DataData is another very broad category, encompassing everything from traditional business analytics to artificial intelligence. Dataengineering was the dominant topic by far, growing 35% year over year. Dataengineering deals with the problem of storing data at scale and delivering that data to applications.
An animated age and gender demographic breakdown pyramid created by Pew Research Center as part of its The Next America project , published in 2014. The project is filled with innovative data visualizations. Klipfolio: Klipfolio is designed to enable users to access and combine data from hundreds of services without writing any code.
The source code for LLaMA was open source, and its weights (parameters) were easily available to researchers. Those weights quickly leaked from “researchers” to the general public, where they jump-started the creation of smaller open source models. Designing enterprise-scale data storage systems is a core part of dataengineering.
A quick look at bigram usage (word pairs) doesn’t really distinguish between “data science,” “dataengineering,” “data analysis,” and other terms; the most common word pair with “data” is “data governance,” followed by “data science.” Cloud deployments aren’t top-down.
The biggest skills gaps were ML modelers and data scientists (52%), understanding business use cases (49%), and dataengineering (42%). The need for people managing and maintaining computing infrastructure was comparatively low (24%), hinting that companies are solving their infrastructure requirements in the cloud.
Looking a bit further into the difficulty of hiring for AI, we found that respondents with AI in production saw the most significant skills gaps in these areas: ML modeling and data science (45%), dataengineering (43%), and maintaining a set of business use cases (40%). Use of AutoML tools. Deploying and Monitoring AI.
Developed in 2006 by Doug Cutting and Mike Cafarella to run the web crawler Apache Nutch, it has become a standard for Big Data analytics. According to the study by the Business Application Research Center (BARC), Hadoop found intensive use as. a suitable technology to implement data lake architecture. Robust community.
The research pinpointed some of the mega-trends—including cloud computing and the rise of open-source technology—that are upending today’s huge enterprise-IT market as organizations across industries push to digitize their operations by modernizing their technology stacks.
The biggest challenge facing operations teams in the coming year, and the biggest challenge facing dataengineers, will be learning how to deploy AI systems effectively. We informally define machine learning as “the part of AI that works”; AI itself is more research oriented and aspirational.
Large enterprises have long used knowledge graphs to better understand underlying relationships between data points, but these graphs are difficult to build and maintain, requiring effort on the part of developers, dataengineers, and subject matter experts who know what the data actually means.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content