This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The following is a review of the book Fundamentals of DataEngineering by Joe Reis and Matt Housley, published by O’Reilly in June of 2022, and some takeaway lessons. This book is as good for a project manager or any other non-technical role as it is for a computer science student or a dataengineer.
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
In the annual Porsche Carrera Cup Brasil, data is essential to keep drivers safe and sustain optimal performance of race cars. Until recently, getting at and analyzing that essential data was a laborious affair that could take hours, and only once the race was over. The device plugs into CAN bus cables by induction.
While Microsoft, AWS, GoogleCloud, and IBM have already released their generative AI offerings, rival Oracle has so far been largely quiet about its own strategy. While AWS, GoogleCloud, Microsoft, and IBM have laid out how their AI services are going to work, most of these services are currently in preview.
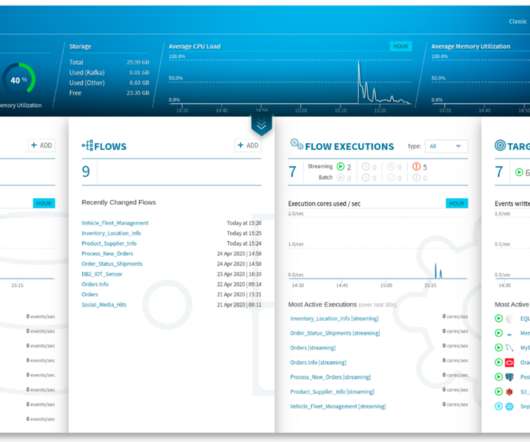
Equalum manages data pipelines, leveraging open source packages, including Apache Spark and Kafka to stream and batch data processes. In this way, Equalum isn’t dissimilar to startups like Striim and StreamSets, which offer tools to build data pipelines across cloud and hybrid cloud platforms (i.e.,
Previously, Walgreens was attempting to perform that task with its data lake but faced two significant obstacles: cost and time. Those challenges are well-known to many organizations as they have sought to obtain analytical knowledge from their vast amounts of data. You can intuitively query the data from the data lake. “You
But in an interview, he explained that the platform is designed to support labeling workflows for different AI use cases, with features that touch on data quality management, reporting, and analytics. This helps to monitor label quality and — ideally — to fix problems before they impact training data.
After a shaky start, Googles Gemini models have become solid performers. Many of the open models can deliver acceptable performance when running on laptops and phones; some are even targeted at embedded devices. So what does our data show? Dataengineers build the infrastructure to collect, store, and analyze data.
Azure Synapse Analytics is ideal if you are looking to unify dataengineering, data warehousing, and advanced analytics into a single, scalable environment while leveraging Azures broader ecosystem of data and AI services. on-premises, AWS, GoogleCloud).
The cloud offers excellent scalability, while graph databases offer the ability to display incredible amounts of data in a way that makes analytics efficient and effective. Who is Big DataEngineer? Big Data requires a unique engineering approach. Big DataEngineer vs Data Scientist.
This can help you see trends, understand the frequency of events, and track connections between operations and performance, for example. Key data visualization benefits include: Unlocking the value big data by enabling people to absorb vast amounts of data at a glance. It also features a drag-and-drop interface.
It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in dataengineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development. MLOps lies at the confluence of ML, dataengineering, and DevOps.
Intended for individuals who perform intricate networking tasks. Design, develop, and deploy cloud-based solutions using AWS. AWS Certified Big Data – Speciality. For individuals who perform complex Big Data analyses and have at least two years of experience using AWS. Azure DataEngineer Associate.
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, dataengineers and production engineers. For now, we’ll focus on Kafka.
In this article, we’ll take a closer look at the top cloud warehouse software, including Snowflake, BigQuery, and Redshift. We’ll review all the important aspects of their architecture, deployment, and performance so you can make an informed decision. Different data is processed in parallel on different nodes.
Ken Blanchard on Leading at a Higher Level: 4 Keys to Creating a High Performing Organization , June 13. Engineering Mentorship , June 24. Spotlight on Learning From Failure: Hiring Engineers with Jeff Potter , June 25. Performance Goals for Growth , July 31. Systems engineering and operations.
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies.
Later, this data can be: modified to maintain the relevance of what was stored, used by business applications to perform its functions, for example check product availability, etc. Namely, we’ll explain what functions it can perform, and how to use it for data analysis. An overview of data warehouse types.
Forbes notes that a full transition to the cloud has proved more challenging than anticipated and many companies will use hybrid cloud solutions to transition to the cloud at their own pace and at a lower risk and cost. This will be a blend of private and public hyperscale clouds like AWS, Azure, and GoogleCloud Platform.
A Big Data Analytics pipeline– from ingestion of data to embedding analytics consists of three steps DataEngineering : The first step is flexible data on-boarding that accelerates time to value. This will require another product for data governance. This is colloquially called data wrangling.
With CDP, customers can deploy storage, compute, and access, all with the freedom offered by the cloud, avoiding vendor lock-in and taking advantage of best-of-breed solutions. The new capabilities of Apache Iceberg in CDP enable you to accelerate multi-cloud open lakehouse implementations. Performance and scalability.
Performance metrics appear in charts and graphs. . WM compares the current and previous jobs by creating baselines for identifying and addressing performance problems. Establishing performance baselines between CDH/HDP and CDP. Suggesting workloads that should move to public cloud and understanding the public cloud costs.
Ken Blanchard on Leading at a Higher Level: 4 Keys to Creating a High Performing Organization , June 13. Engineering Mentorship , June 24. Spotlight on Learning From Failure: Hiring Engineers with Jeff Potter , June 25. Performance Goals for Growth , July 31. Systems engineering and operations.
Data science is generally not operationalized Consider a data flow from a machine or process, all the way to an end-user. 2 In general, the flow of data from machine to the dataengineer (1) is well operationalized. You could argue the same about the dataengineering step (2) , although this differs per company.
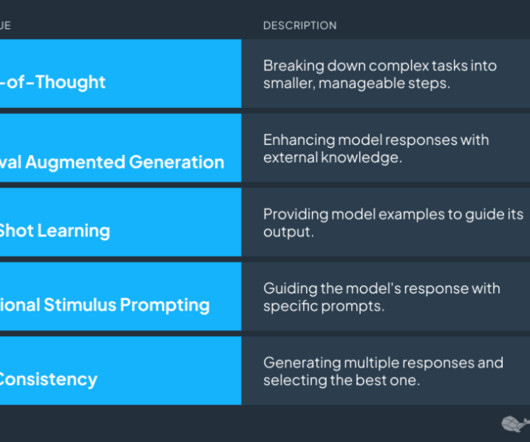
Taking a RAG approach The retrieval-augmented generation (RAG) approach is a powerful technique that leverages the capabilities of Gen AI to make requirements engineering more efficient and effective. As a GoogleCloud Partner , in this instance we refer to text-based Gemini 1.5 What is Retrieval-Augmented Generation (RAG)?
Distributed systems require designing software that can run effectively in these environments: software that’s reliable, that stays up even when some servers or networks go down, and where there are as few performance bottlenecks as possible. Dataengineering was the dominant topic by far, growing 35% year over year.
Three types of data migration tools. Automation scripts can be written by dataengineers or ETL developers in charge of your migration project. This makes sense when you move a relatively small amount of data and deal with simple requirements. Phases of the data migration process. Data sources and destinations.
As a result, it became possible to provide real-time analytics by processing streamed data. Please note: this topic requires some general understanding of analytics and dataengineering, so we suggest you read the following articles if you’re new to the topic: Dataengineering overview.
This gives some high-level information, however it is hard to determine what the actual SQL is that was executed, and on which exact records a data quality test failed or raised a warning. Logs will purely show information about a single run, so you don’t have an easy way to see how a test performs over time.
Rust is a relatively young language that stresses memory safety and performance. It’s designed for high performance, especially for numerical operations. Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6% Where are these languages going?
Sentiment analysis results by GoogleCloud Natural Language API. But the same principle of calculating probability of word sequences can create language models that can perform impressive results in mimicking human speech. are successfully performed by rules. Spam detection. Speech recognition.
What happens, when a data scientist, BI developer , or dataengineer feeds a huge file to Hadoop? Under the hood, the framework divides a chunk of Big Data into smaller, digestible parts and allocates them across multiple commodity machines to be processed in parallel. How dataengineering works under the hood.
Tasks that Offshore Python Developer Can Perform for You Remote coders with deep expertise in Python can add significant value to your projects in the following areas: Building web apps and APIs. Developers gather and preprocess data to build and train algorithms with libraries like Keras, TensorFlow, and PyTorch. Dataengineering.
The biggest skills gaps were ML modelers and data scientists (52%), understanding business use cases (49%), and dataengineering (42%). The need for people managing and maintaining computing infrastructure was comparatively low (24%), hinting that companies are solving their infrastructure requirements in the cloud.
ML algorithms for predictions and data-based decisions; Deep Learning expertise to analyze unstructured data, such as images, audio, and text; Mathematics and statistics. Google Professional Machine Learning Engineer implies developers knowledge of design, building, and deployment of ML models using GoogleCloud tools.
To get good output, you need to create a data environment that can be consumed by the model,” he says. You need to have dataengineering skills, and be able to recalibrate these models, so you probably need machine learning capabilities on your staff, and you need to be good at prompt engineering.
With the consistent rise in data volume, variety, and velocity, organizations started seeking special solutions to store and process the information tsunami. This demand gave birth to clouddata warehouses that offer flexibility, scalability, and high performance. As such, it is considered cloud-agnostic.
Reading Data: # Reading data from DBFS val data_df = spark.read.csv("dbfs:/FileStore/tables/Largest_earthquakes_by_year.csv") The code will read the specified CSV file into a DataFrame named data_df, allowing further processing and analysis using Spark’s DataFrame API. If the file exists, it prints “File exists.”;
After trying all options existing on the market — from messaging systems to ETL tools — in-house dataengineers decided to design a totally new solution for metrics monitoring and user activity tracking which would handle billions of messages a day. High performance. How Apache Kafka streams relate to Franz Kafka’s books.
To operate appropriately and perform specific tasks, LLMs are trained on vast amounts of data. LLM prompt engineering is the process of preparation and refinement of the inputs – the prompts from a developer to a large language model to encourage the LLM for the best possible output – response for particular tasks.
Then we perform frequent batch ETL from application databases to a data warehouse. Often post-extraction data is staged in intermediate tables which is followed by transformation and load steps to migrate data into a target database or data warehouse. Classic ETL. Transformation is happening at a very late stage.
Introduction to Employee Performance Management , June 10. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , May 20. First Steps in Data Analysis , May 20. Data Analysis Paradigms in the Tidyverse , May 30. Foundations of Microsoft Excel , June 5.
Data Handling and Big Data Technologies Since AI systems rely heavily on data, engineers must ensure that data is clean, well-organized, and accessible. ONNX Runtime an increasingly important tool because most applications demand real-time processing and reduced latency.
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content