This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If we look at the hierarchy of needs in data science implementations, we’ll see that the next step after gathering your data for analysis is dataengineering. This discipline is not to be underestimated, as it enables effective data storing and reliable data flow while taking charge of the infrastructure.
In this way, Equalum isn’t dissimilar to startups like Striim and StreamSets, which offer tools to build data pipelines across cloud and hybrid cloud platforms (i.e., mixes of on-premises and public cloud infrastructure). This is creating a very complex environment,” Eilon said.
It facilitates collaboration between a data science team and IT professionals, and thus combines skills, techniques, and tools used in dataengineering, machine learning, and DevOps — a predecessor of MLOps in the world of software development. MLOps lies at the confluence of ML, dataengineering, and DevOps.
Can deploy and define metrics, monitoring and logging systems on AWS. . Azure DataEngineer Associate. For individuals that design and implement the management, security, monitoring, and privacy of data – using the full stack of Azure data services – to satisfy business needs. .
MLEs are usually a part of a data science team which includes dataengineers , data architects, data and business analysts, and data scientists. Who does what in a data science team. Machine learning engineers are relatively new to data-driven companies.
Performance metrics appear in charts and graphs. . We compare the current run of a job to a baseline derived from performance metrics. Fixed Reports / DataEngineering jobs . Fixed Reports / DataEngineering Jobs. CDP runs on AWS and Azure, with GoogleCloud Platform coming soon. Report Format.
Taking a RAG approach The retrieval-augmented generation (RAG) approach is a powerful technique that leverages the capabilities of Gen AI to make requirements engineering more efficient and effective. As a GoogleCloud Partner , in this instance we refer to text-based Gemini 1.5 What is Retrieval-Augmented Generation (RAG)?
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. What does the high-performance data project have to do with the real Franz Kafka’s heritage? process data in real time and run streaming analytics. How Apache Kafka streams relate to Franz Kafka’s books.
Google Professional Machine Learning Engineer implies developers knowledge of design, building, and deployment of ML models using GoogleCloud tools. It includes subjects like dataengineering, model optimization, and deployment in real-world conditions. Dataengineer. Big Data technologies.
60 Minutes to Better Product Metrics , July 10. Data science and data tools. Practical Linux Command Line for DataEngineers and Analysts , May 20. First Steps in Data Analysis , May 20. GoogleCloud Platform Professional Cloud Architect Certification Crash Course , June 25-26.
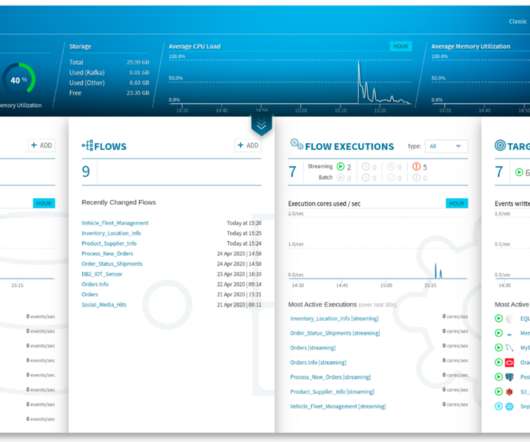
As the picture above clearly shows, organizations have data producers and operational data on the left side and data consumers and analytical data on the right side. Data producers lack ownership over the information they generate which means they are not in charge of its quality. It works like this.
Data science and data analysis certification from IBM, Google, or Johns Hopkins University The mix of linguistic studies, computer science, and AI and NLP-related certifications from top platforms like GoogleCloud, DeepLearning.ai, and Microsoft are vital for obtaining the expertise and skills to work as a prompt designer.
Rudra Gandhi, DataEngineering intern, (San Jose State University, Mathematics and Computer Science Major): As a company, I thought that StubHub is an interactive platform for its audiences and accepts feedback very nicely. Nagaraja: Time series forecasting for different metrics such as GMS, conversion rate and average order value.
Rather than asking ‘what are the productivity gains’ and seeking to translate those metrics into incremental efficiencies or profits, visionary enterprises should ask ‘what is our North Star vision and roadmap for human value development in the Generative Engineering Era’. We look forward to working with you to help you build yours.
That’s a situation that’s become increasingly common for data-driven businesses, which need to make critical, time-sensitive decisions informed by large datasets of metrics from their customers, operations, or infrastructure. For more on how we make it work, see Inside the Kentik DataEngine.).
Using prepared data, AI software developers can implement techniques to evaluate and optimize model performance. It can often involve feature engineering to support relevant functionality. Deployment: They deploy AI models into production environments, often using cloud services, containers, or other deployment tools.
What was worth noting was that (anecdotally) even engineers from large organisations were not looking for full workload portability (i.e. There were also two patterns of adoption of HashiCorp tooling I observed from engineers that I chatted to: Infrastructure-driven?—?in
The rest is done by dataengineers, data scientists , machine learning engineers , and other high-trained (and high-paid) specialists. The technology supports tabular, image, text, and video data, and also comes with an easy-to-use drag-and-drop tool to engage people without ML expertise. Source: GoogleCloud Blog.
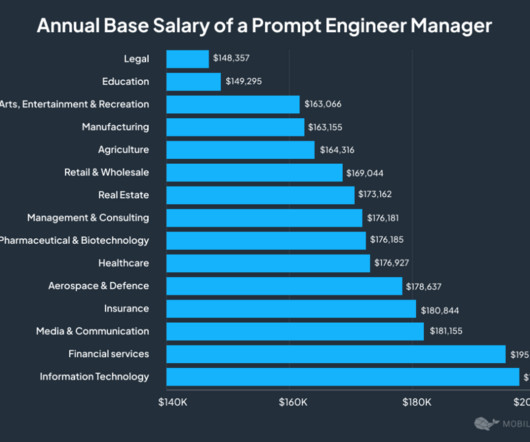
The data in each graph is based on OReillys units viewed metric, which measures the actual use of each item on the platform. In each graph, the data is scaled so that the item with the greatest units viewed is 1. Therefore, its not surprising that DataEngineering skills showed a solid 29% increase from 2023 to 2024.
Klipfolio: Klipfolio is designed to enable users to access and combine data from hundreds of services without writing any code. It leverages pre-built, curated instant metrics and a powerful data modeler, making it a good tool for building custom dashboards. It has an easy-to-use interface for making dashboards and reports.
Methodology This report is based on our internal “units viewed” metric, which is a single metric across all the media types included in our platform: ebooks, of course, but also videos and live training courses. Dataengineering was the dominant topic by far, growing 35% year over year. How do you deploy to the cloud?
So while we can discuss whether Answers usage is in line with other services, it’s difficult to talk about trends with so little data, and it’s impossible to do a year-over-year comparison. Both “GCP” and “GoogleCloud” were in the top 3% of their respective lists. We saw that play out on our platform.
Just a few notes on methodology: This report is based on O’Reilly’s internal “Units Viewed” metric. The data used in this report covers January through November in 2022 and 2023. Data analysis and databases Dataengineering was by far the most heavily used topic in this category; it showed a 3.6%
The biggest skills gaps were ML modelers and data scientists (52%), understanding business use cases (49%), and dataengineering (42%). The need for people managing and maintaining computing infrastructure was comparatively low (24%), hinting that companies are solving their infrastructure requirements in the cloud.
The biggest challenge facing operations teams in the coming year, and the biggest challenge facing dataengineers, will be learning how to deploy AI systems effectively. We don’t see that in our data, though there are certainly some metrics to say that artificial intelligence has stalled. What’s behind this story?
We organize all of the trending information in your field so you don't have to. Join 49,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content